
U.S. chatbot use passes 50 percent: AA-Briefcase benchmark measures knowledge work
ARD, an open spec for discovery. North Mini Code gains traction. Security experts criticize U.S. government. Apple Intelligence, beyond Siri.

ARD, an open spec for discovery. North Mini Code gains traction. Security experts criticize U.S. government. Apple Intelligence, beyond Siri.
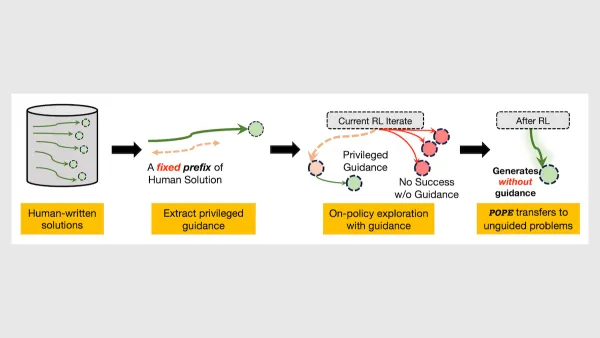
Reinforcement learning can’t train a model to solve a difficult problem if the model doesn’t discover all the right steps.
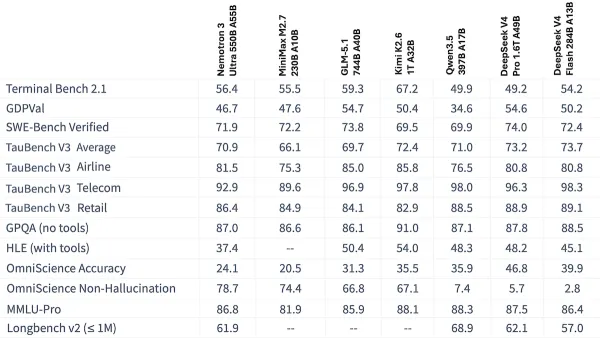
Nvidia’s largest-yet model is among the best-performing from a developer based in the U.S. and among the most open developed by anyone.
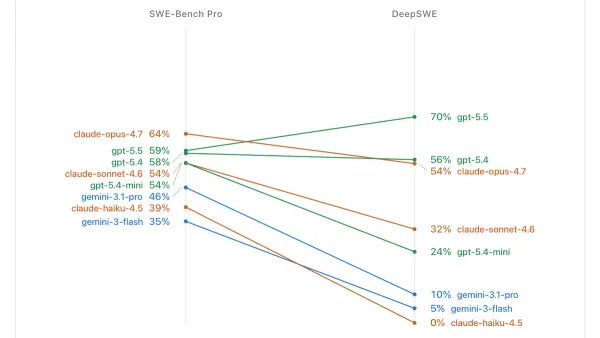
SWE-bench, a family of benchmarks that focuses on an LLM’s ability to fix software bugs, is giving way to new tests that evaluate agent software-engineering performance in more challenging ways.
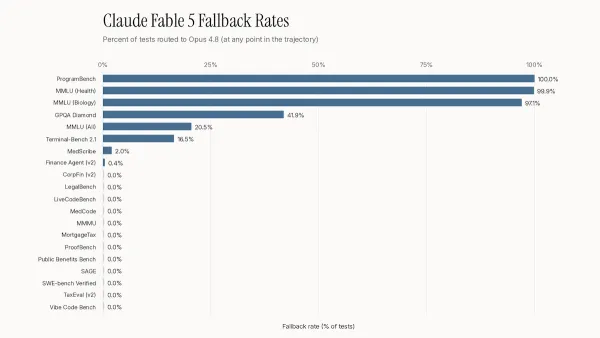
Before Anthropic pulled its latest Claude models from circulation, even professional testers couldn’t readily tell whether they were getting a Mythos-class model or a lesser version under the same name.

Over the last two weeks, both the U.S. Government and Anthropic took significant actions that demonstrated their power to control access to AI by restricting what others can do with frontier models.

The Batch AI News and Insights: Over the last two weeks, both the U.S. Government and Anthropic took significant actions that demonstrated their power to control access to AI by restricting what others can do with frontier models.

OpenRouter’s model mix-and-match. Subject expertise trumps software skills. OpenAI loses share to Google, Anthropic. Google ruled liable for AI mistakes.

Claude Fable 5 no longer silently degrades. Hermes Agent maker streamlines setup. Agents’ Last Exam pushes top models. Gemini-SQL2 translates database queries.
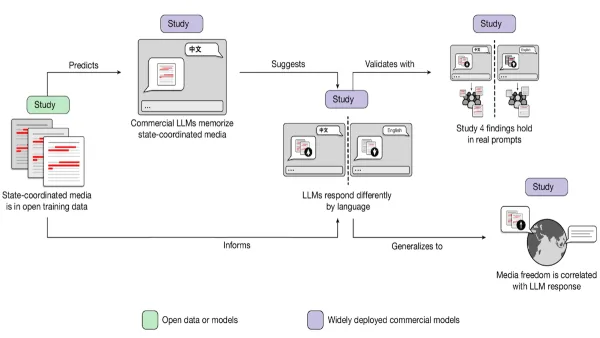
Popular large language models have adopted the biases of governments that control the free flow of information, particularly when those models generate output in the languages of countries where such governments are in power, researchers found.
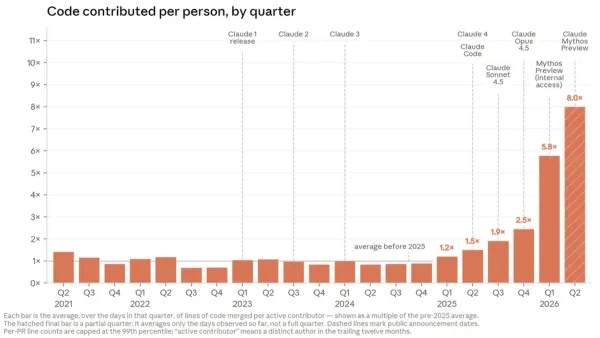
The phrase recursive self-improvement erupted on social media following an Anthropic report that tracked AI-driven gains in the company’s internal software-engineering productivity.
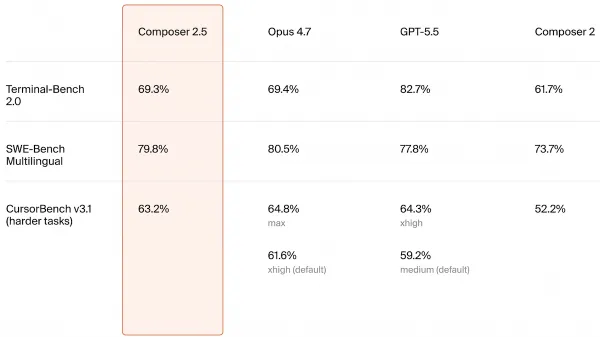
Cursor’s latest software engineering model rivals the performance of leading competitors like Claude Opus 4.7 and GPT 5.5 for a fraction of the price.
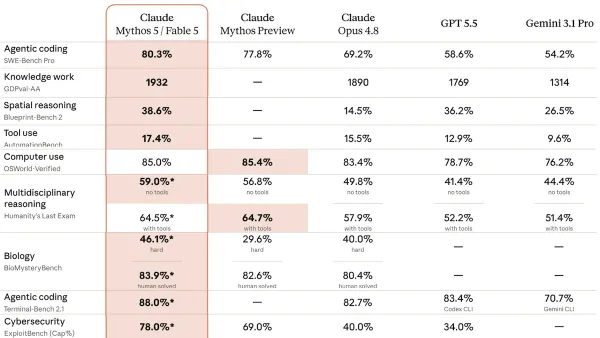
Machine Learning Research
After months of headlines that teased a large language model with extraordinary capabilities, Anthropic launched Claude Mythos 5, which can crack software previously believed to be secure, and Claude Fable 5, a version for general use that limits what users can do in an unprecedented way.
Letters
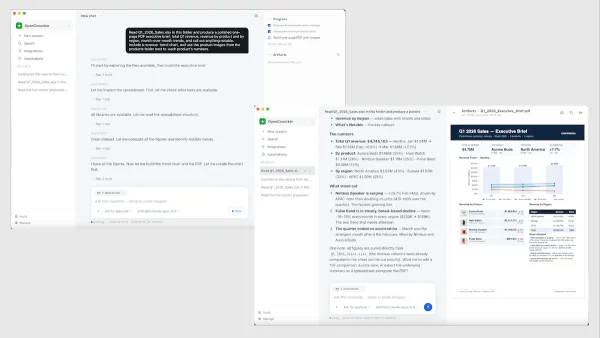
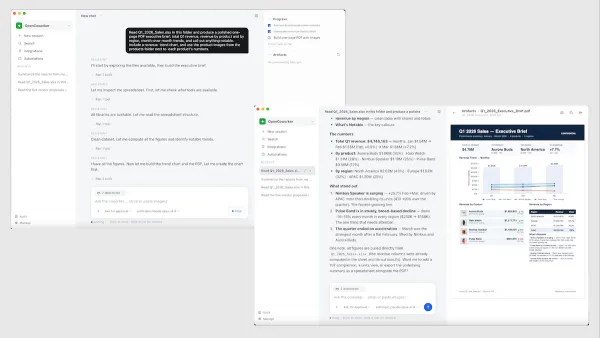
If you haven’t already, I encourage you to experiment with using AI agents not just to chat but to actually do work for you on your desktop.
The Batch Newsletter
The Batch AI News and Insights: If you haven’t already, I encourage you to experiment with using AI agents not just to chat but to actually do work for you on your desktop.

Data Points
Google’s voice translation model covers 70+ languages. OpenAI’s preliminary public-offering paperwork. NotebookLM, now powered by Gemini 3.5 agents. FrontierCode, a new code-quality benchmark from Cognition.

Data Points
The first working vaccine built by AI. Kimi CLI, Moonshot’s software engineering agent. The White House’s plans for an OpenAI stake. OpenJarvis, an open-source agent that learns on-device.
Machine Learning Research
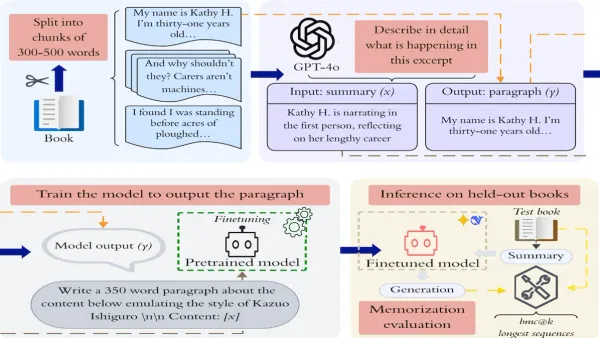
Fine-tuning large language models on a seemingly benign task that would be useful to writers — expanding plot summaries into paragraphs of polished fiction — causes them to regurgitate substantial portions of books on which they were pretrained.
Tech & Society
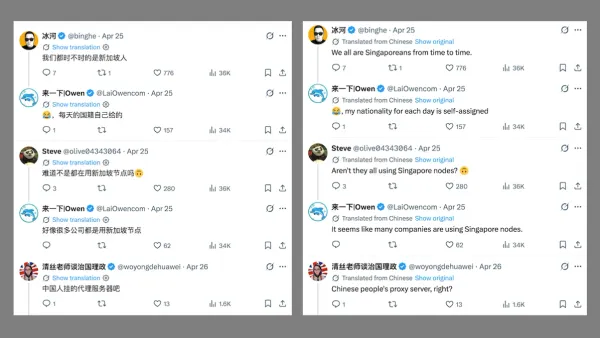
An ecosystem of API proxy servers enables AI developers in China to access top U.S. models at deeply discounted prices.

Tech & Society
An AI-powered network of thermal sensors is helping ships avoid collisions with whales.
Machine Learning Research
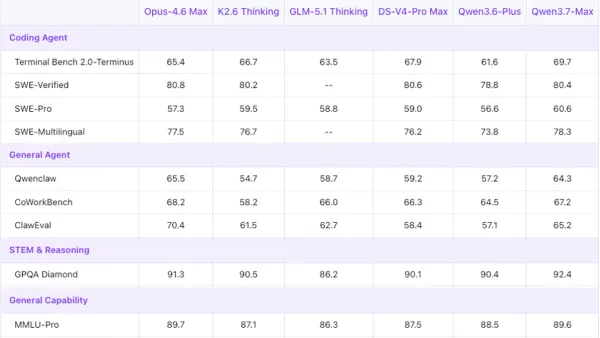
Alibaba updated its flagship large language model for long-running agentic work, pushing it into the top rank among LLMs built in China.

Letters
There have been intense efforts over the past few years to lobby governments to pass AI laws for regulatory capture or to suppress open source.

The Batch Newsletter
The Batch AI News and Insights: There have been intense efforts over the past few years to lobby governments to pass AI laws for regulatory capture or to suppress open source.

Data Points
How agents think about search. Hermes now a multi-platform desktop app. Qwen3.7-Plus, Alibaba’s midsized cloud model. OpenAI’s latest plugins for Codex.