Kimi K2.6 Challenges Open-Weights Champs: Kimi K2.6 matches open Qwen3.6 Max andDeepSeek V4, falls just behind top closed models.
Moonshot AI’s updated Kimi model handles longer autonomous coding sessions and scales up its multi-agent orchestration relative to its predecessor.
Moonshot AI’s updated Kimi model handles longer autonomous coding sessions and scales up its multi-agent orchestration relative to its predecessor.
What’s new: Kimi K2.6 is a 1 trillion-parameter vision-language model that performs neck and neck with Qwen3.6 Max Preview and the newly released DeepSeek V4 and falls just behind top closed models. It’s designed to generate code in a plan-write-test-debug loop that can last for days, and it can instantiate hundreds of agents that collaborate on a single task. It also produces fewer hallucinations than its predecessor.
- Input/output: Text, images, and video in (up to 256,000 tokens), text out (up to 98,000 tokens)
- Architecture: Mixture-of-experts, 1 trillion parameters total, 32 billion active per token, MoonViT vision encoder
- Features: Tool use, web search, native INT4 quantization, “preserve thinking” mode, agent swarm
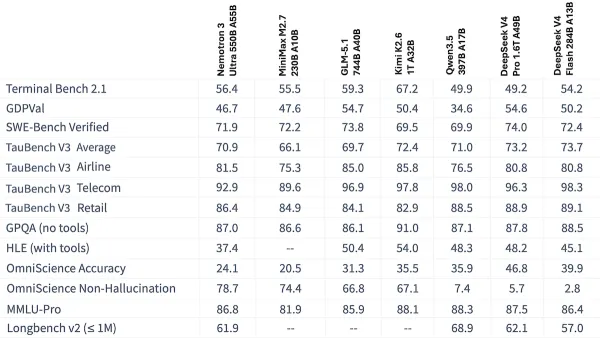
- Performance: Tops other open-weights models on the Artificial Analysis Intelligence Index but trails leading proprietary models
- Availability/price: Weights free to download from Hugging Face under a modified MIT license that permits commercial uses with attribution for products with more than 100 million monthly active users or more than $20 million in monthly revenue, free chat interface at kimi.com and Kimi mobile app, API access via Moonshot $0.95/$0.16/$4.00 per million input/cached/output tokens
- Undisclosed: Training data and methods
How it works: Kimi K2.6 reuses the architecture introduced with Kimi K2 and refined in Kimi K2.5, including the multi-headed latent attention (an attention variant that reduces memory requirements by compressing keys and values) and MoonViT vision encoder (400 million parameters). Moonshot has not disclosed how Kimi K2.6 differs with respect to training data and methods.
- Like Kimi K2 Thinking and Kimi K2.5, Kimi K2.6 was trained with native INT4 quantization.
- A preserve thinking option retains previously generated reasoning tokens across multi-turn interactions, which improves coding performance according to Moonshot.
- In agent swarm mode, a coordinator agent decomposes a task into subtasks, creates up to 300 parallel subagents that can execute 4,000 steps (up from 100 subagents and 1,500 steps in Kimi K2.5) to execute tasks, and reassigns work when an agent fails or stalls. A research preview feature called claw groups opens agent swarm mode to agents from other developers — that can run on any device or model — as well as human collaborators.
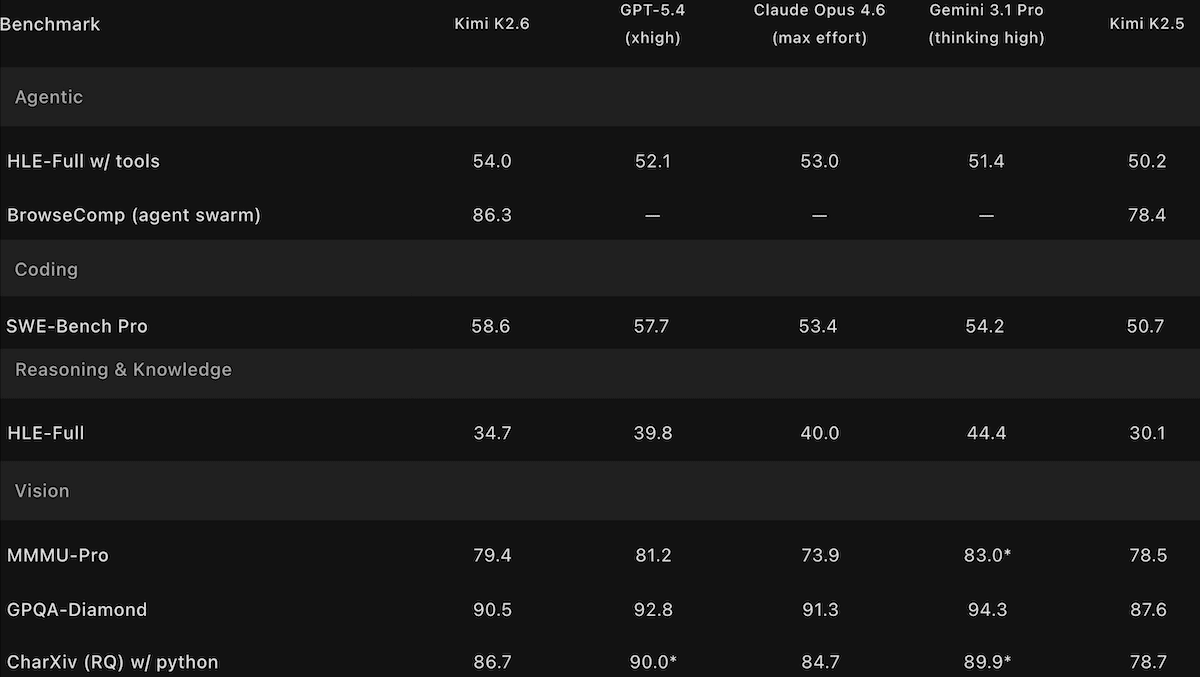
Performance: Kimi K2.6 leads open-weights models on some benchmarks of intelligence and agentic capability and ranks highly relative to its peers in subjective tests of human preferences. However, it trails leading closed models on benchmarks that evaluate reasoning and coding large projects as well as human preferences.
- On the Artificial Analysis’ Intelligence Index, a composite of 10 tests of economically useful tasks, Kimi K2.6 set to reasoning (54) leads open-weights models but trails GPT-5.5 set to xhigh reasoning (60) as well as Claude Opus 4.7 set to max reasoning and Gemini 3.1 Pro Preview set to reasoning. The closest open-weights competitors are Qwen3.6 Preview set to max reasoning and DeepSeek-V4-Pro set to max reasoning (tied at 52).
- KimiK2.6’s position in the Intelligence Index rests on its top performance among open-weights models on GPQA Diamond (answering graduate-level science questions), HLE (answering expert-level multidisciplinary questions designed to test reasoning), and SciCode (generating code for scientific research). However, it fell just behind the newly released open-weights model DeepSeek-V4-Pro on five index benchmarks, and it underperformed Xiaomi MiMo-2.5-Pro and other open-weights models on the remaining two.
- Moonshot tested Kimi K2.6’s ability to complete large-scale coding projects by asking it to port Qwen3.5-0.8B’s inference code to Zig (a systems-programming language) and optimize it for a Mac. Across 4,000-plus tool calls and 14 successive revisions over more than 12 hours, Kimi K2.6 raised the port’s throughput from roughly 15 to 193 tokens per second, ending around 20 percent faster than LM Studio, a popular local inference app, running on the same hardware.
- Artificial Analysis measured Kimi K2.6’s hallucination rate (given a question-answering benchmark of general knowledge, the proportion of non-correct outputs that include erroneous responses, professions of ignorance, and refusals to respond) at 39.26 percent. This is lower than Kimi K2.5 (64.6 percent) and roughly comparable to Anthropic Claude Opus 4.7 (36.18 percent)
- On Arena.ai’s Code Arena WebDev leaderboard, which ranks models on web-development coding via blind pairwise comparisons, Kimi K2.6 (1,529 Elo) ranked sixth among 67 models as of April 26, 2026, behind Anthropic Claude Opus 4.7 (1,565 Elo), Claude Opus 4.6 (1,548 Elo), and Z.ai’s open-weights GLM-5.1 (1,534 Elo).
Behind the news: The ability to stay on task across hours of autonomous execution emerged as a competitive frontier in late 2025. Anthropic’s Claude Code, OpenAI’s Codex, and Alibaba’s Qwen3-Coder all targeted this capability in their most recent releases. Kimi K2, released in July 2025, was an early open-weights entrant in agentic tool use, and the family has been updated every few months since with growing emphasis on long-horizon execution.
Why it matters: Moonshot has steadily extended the duration over which Kimi K2 family models can usefully execute tasks autonomously: first short reasoning traces, then multi-step tool use, multi-hour coding sessions, and now multi-day projects. Each extension widens the interval between human check-ins required to keep agents on track.
We’re thinking: Sustained autonomy and low hallucination rates are related, but less and less so. If an agent makes a mistake, it can check its work, find the mistake, and fix it.