Seedance Makes A Splash, Nvidia's AI-Guided Chip Designs, Helping Robots Not Forget
The Batch AI News and Insights: There will be no AI jobpocalypse.
Dear friends,
There will be no AI jobpocalypse.
The story that AI will lead to massive unemployment is stoking unnecessary fear. AI — like any other technology — does affect jobs, but telling overblown stories of large-scale unemployment is irresponsible and damaging. Let’s put a stop to it.
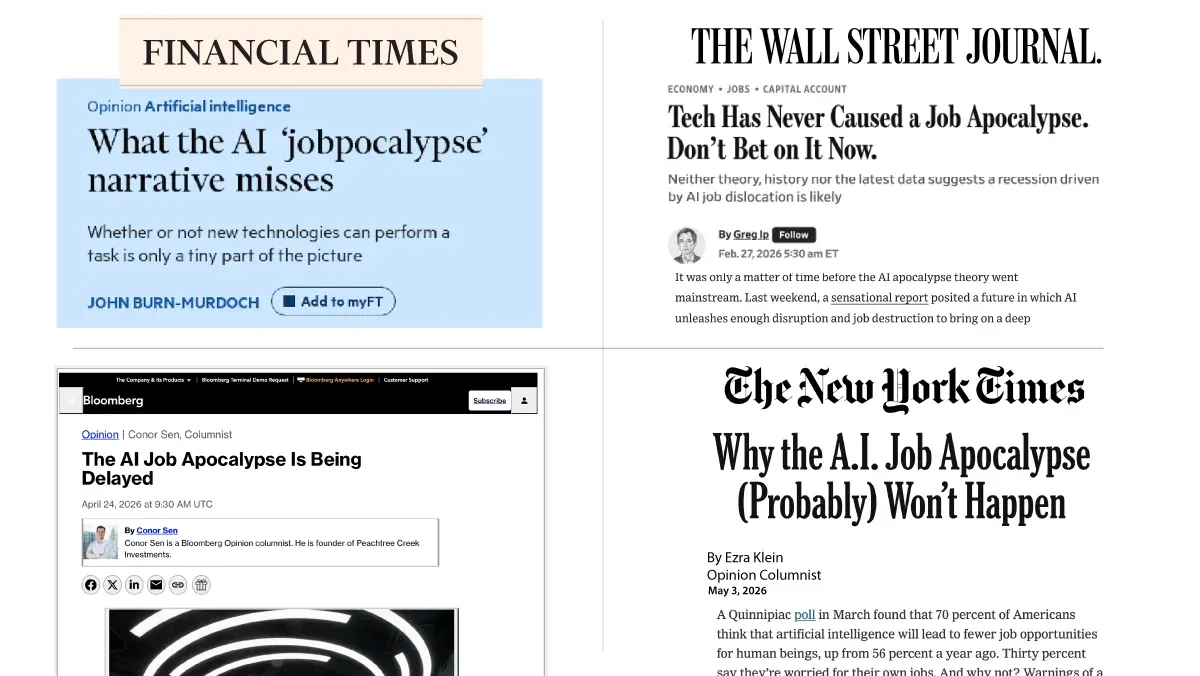
I’ve expressed skepticism about the jobpocalypse in previous letters. I’m glad to see that the popular press is now pushing back on this narrative. The image below features some recent headlines.
Software engineering is the sector most affected by AI tools, as coding agents race ahead. Yet hiring of software engineers remains strong! So while there are examples of AI taking away jobs, the trends strongly suggest the net job creation is vastly greater than the job destruction — just like earlier waves of technology. Further, despite all the exciting progress in AI, the U.S. unemployment rate remains a healthy 4.3%.
Why is the AI jobpocalypse narrative so popular? For one thing, frontier AI labs have a strong incentive to tell stories that make AI technology sound more powerful. At their most extreme, they promote science-fiction scenarios of AI “taking over” and causing human extinction. If a technology can replace many employees, surely that technology must be very valuable!
Also, a lot of SaaS software companies charge around $100-$1000 per user/year. But if an AI company can replace an employee who makes $100,000 — or make them 50% more productive — then charging even $10,000 starts to look reasonable. By anchoring not to typical SaaS prices but to salaries of employees, AI companies can charge a lot more.
Additionally, businesses have a strong incentive to talk about layoffs as if they were caused by AI. After all, talking about how they’re using AI to be far more productive with fewer staff makes them look smart. This is a better message than admitting they overhired during the pandemic when capital was abundant due to low interest rates and a massive government financial stimulus.
To be clear, I recognize that AI is causing a lot of people’s work to change. This is hard. This is stressful. (And to some, it can be fun.) I empathize with everyone affected. At the same time, this is very different from predicting a collapse of the job market.
Societies are capable of telling themselves stories for years that have little basis in reality and lead to poor society-wide decision making. For example, fears over nuclear plant safety led to under-investment in nuclear power. Fears of the “population bomb” in the 1960s led countries to implement harsh policies to reduce their populations. And worries about dietary fat led governments to promote unhealthy high-sugar diets for decades.
Now that mainstream media is openly skeptical about the jobpocalypse, I hope these stories will start to lose their teeth (much like fears of AI-driven human extinction have).
Contrary to the predictions of an AI jobpocalypse, I predict the opposite: There will be an AI jobapalooza! AI will lead to a lot more good AI engineering jobs, and I’m also optimistic about the future of the overall job market. What AI engineers do will be different from traditional software engineering, and many of these jobs will be in businesses other than traditional large employers of developers. In non-AI roles, too, the skills needed will change because of AI. That makes this a good time to encourage more people to become proficient in AI, and make sure they’re ready for the different but plentiful jobs of the future!
Keep building,
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Most agents respond with text. Learn to build agents that render charts, forms, and interactive user interfaces. In this course, you’ll connect a LangChain agent to a React front end and build across the generative user-interface spectrum, ending with a full-stack app that enables users and agents work on a shared state. Enroll for free!
News

ByteDance Bids for Video Leadership
As OpenAI prepares to shut down Sora, ByteDance made its own video generation model available to hundreds of millions of users.
What’s new: ByteDance added Seedance 2.0, its multimodal video generator, to its popular video-editing app CapCut. Launched earlier this year in China, the model now reaches paying CapCut users in Southeast Asia, Latin America, Africa, the Middle East, parts of Europe, Japan, and the United States.
- Input/output: Text, images, audio, and video in (up to 3 video clips, 9 images, and 3 audio clips), synchronized video and audio out (4 to 15 seconds at 480 or 720 pixels on the shorter edge in 6 aspect ratios: 21:9, 16:9, 4:3, 1:1, 3:4, and 9:16)
- Features: Lip-synced dialogue in multiple languages, ambient sound, music, multiple camera shots with cuts in a single clip, camera and lighting controlled by prompts, outputs marked by invisible watermark, blocking of input images that contain real faces or copyrighted characters (via CapCut)
- Performance: Within top two on Arena AI and Artificial Analysis video leaderboards
- Availability/price: Via CapCut (Jianying in China) paid tier, Dreamina web interface, API via the ByteDance services BytePlus and Volcengine, and third-party providers including Higgsfield.ai for $0.30 per second of output (720 pixels, audio included) or $0.24 per second for faster processing by SeeDance 2.0 Fast
- Undisclosed: Architecture, parameter count, training data and methods
How it works: Seedance 2.0 extends ByteDance’s earlier work from synchronous generation of audio-video streams in parallel to joint generation within a unified system. ByteDance’s launch announcement characterizes the architecture as “sparse.”
- The model accepts video-audio reference input for four tasks: (i) Referenced-based generation applies subject, motion, visual effects, and/or style cues to new output. (ii) Editing modifies specified regions, characters, actions, and/or audio within existing video. (iii) Extension produces output that precedes or succeeds existing video. (iv) Combination modes pair these (for example, replacing the subject in an existing video with one from a reference image).
- Audio is generated simultaneously with video, producing stereo dialogue, sound effects, and background audio.
- The model generates sequential shots and cuts in a single pass rather than generating and assembling separate clips, which helps to maintain character and scene consistency.
Performance: Seedance 2.0 ranks first and second on two independent leaderboards that rank models through blind votes of human preference in head-to-head matchups. Alibaba’s HappyHorse-1.0 is the closest challenger on both leaderboards.
- On arena.ai, Seedance 2.0 achieved 1,460 Elo on text-to-video performance and 1,454 Elo on image-to-video performance, narrowly leading both categories over HappyHorse-1.0 (1,444 Elo on each). However, the leaderboard labels Seedance 2.0 and HappyHorse-1.0 results as preliminary.
- On Artificial Analysis, Alibaba’s HappyHorse-1.0 leads three of four video categories (image-to-video without audio and text-to-video with and without audio), while Seedance 2.0 ranks second. Seedance 2.0 leads image-to-video performance with synchronized audio, achieving 1,182 Elo, ahead of HappyHorse-1.0 (1,168 Elo) and Sky Work AI’s SkyReels V4 (1,091 Elo).
- ByteDance flags limitations in detail stability, “hyper-realism,” audio distortion, multi-subject consistency, text-rendering accuracy, and “complex” editing effects.
Yes, but: Shortly after ByteDance released Seedance 2.0 in China, a generated clip that featured likenesses of actors Tom Cruise and Brad Pitt spurred six top Hollywood studios to demand that the company stop training its models on copyrighted material and block users from generating clips based on copyrighted material. The dispute remains unresolved. ByteDance added safeguards on CapCut, but it remains unclear whether they extend to outputs generated via third-party APIs.
Behind the news: The video generation market has reshuffled quickly over the past month. U.S. developers have retreated from the consumer market, and Chinese developers have released new models at an accelerating pace.
- In March, OpenAI announced it would discontinue the Sora app and API. Reports indicated that the company had shifted compute to coding and business products after Sora’s daily active user count fell from about 1 million at launch to under 500,000, while the service costs an estimated $1 million a day to operate.
- Alibaba’s HappyHorse-1.0 debuted on independent video leaderboards in early April, while it was still undergoing a closed beta test, and rose to first place across multiple categories.
- Shortly after, Alibaba unveiled HappyOyster, an AI system that generates 3D environments for developing games and films. Users can generate 3D environments from text or images and steer them in real time.
- Tencent open-sourced an updated version of its Hunyuan 3D the same day.
Why it matters: While competitors offer either a video generator or an editing app, ByteDance owns both. Moreover, its editor appears to have gargantuan reach. CapCut reportedly has 736 million monthly active users on mobile, the second-largest consumer AI product behind only ChatGPT. Seedance 2.0’s arrival on CapCut shows what one company can do when it controls both.
We’re thinking: OpenAI’s withdrawal of Sora points to a hard truth: Given the current cost of computation, AI-generated video is an expensive consumer product.
How Nvidia Uses AI to Design Chips
Nvidia’s chief scientist dreams of telling an AI model to design a new GPU, then skiing for a couple days while the system does the job. He outlined Nvidia’s progress toward that goal and how far it has to go.
What’s new: Bill Dally, who leads roughly 300 researchers at Nvidia, described AI’s growing role in designing the company’s chips in a conversation with his Google counterpart, Jeff Dean, onstage at Nvidia’s GTC conference in mid-March. His examples (starting in the video at around 24 minutes) ranged from a reinforcement learning system that lays out a chip’s building blocks to large language models trained on decades of proprietary documents.
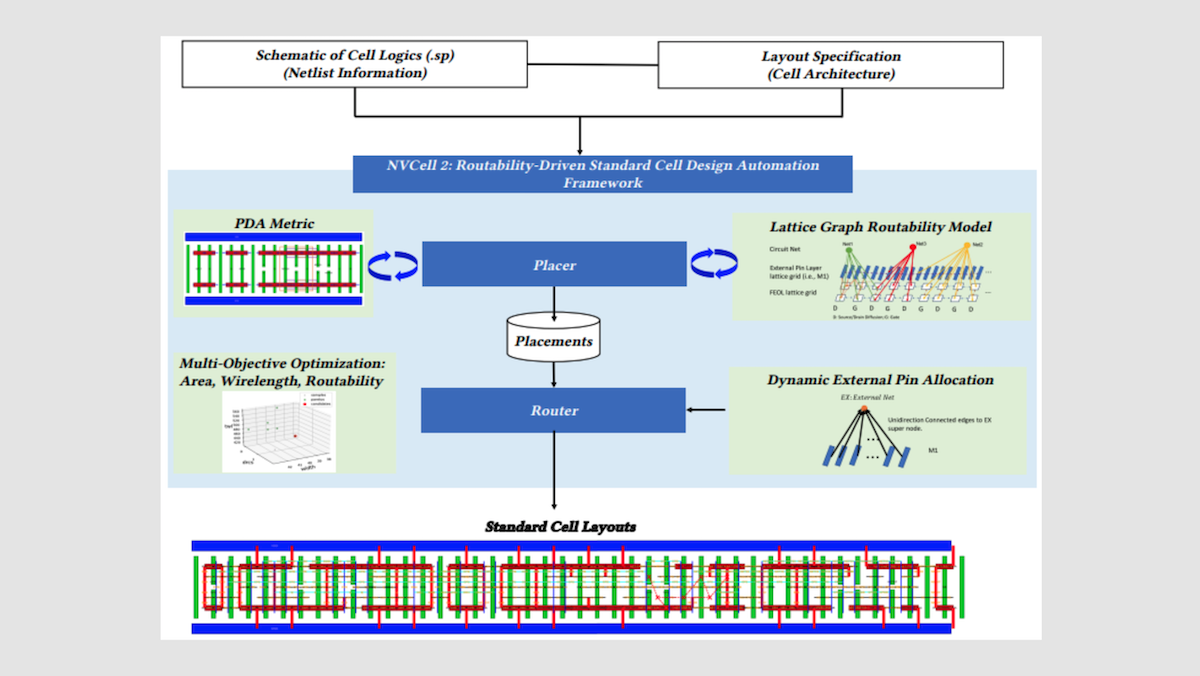
How it works: Nvidia applies AI at five stages of chip design: laying out components, designing arithmetic circuits (components that perform math on binary numbers, like adders and counters), general engineering assistance, verifying finished designs, and exploring novel layouts.
- Each time Nvidia takes advantage of a new semiconductor manufacturing process — generally to shrink component sizes, which makes it possible to fit more of them per area of silicon — it must redesign around 2,500 to 3,000 small reusable layout blocks, or cells, such as logic gates and memory latches. An AI system called NVCell does this work. NVCell pairs a genetic algorithm that proposes candidate layouts with a reinforcement learning agent that incrementally corrects violations of design rules (for instance, wires placed too close together). The agent receives a reward each time it clears a violation and a small penalty for each step it takes, an incentive to find the shortest path to a clean design. A rule checker flags violations, and the agent learns to fix them. NVCell cuts work that previously occupied eight engineers for roughly 10 months to an overnight run on a single GPU. The results match or exceed human designs with respect to the area each cell occupies, the power it consumes, and how quickly signals propagate through it.
- Another reinforcement learning system, PrefixRL, designs the microscopic circuits at the heart of GPU arithmetic units. The agent receives a reward when the circuit design meets timing constraints while minimizing the chip area it occupies and the power it draws. The resulting components are “bizarre” configurations that are 20 percent to 30 percent better than human designs, Dally said. For instance, a 64-bit adder (a circuit that sums two binary numbers) designed by PrefixRL occupies 25 percent less chip area than an equivalent design produced by industry-standard chip-design tools.
- Nvidia built two large language models, ChipNeMo and BugNeMo, for internal use. The team fine-tuned open-weights LLaMA 2 base models (7 billion and 13 billion parameters) on Nvidia’s internal documentation, including the low-level design code for every GPU the company has produced along with the accompanying hardware specifications. A 2023 paper describes three uses: (i) answering engineers’ questions about Nvidia hardware, (ii) generating code snippets in specialized chip-design languages, and (iii) summarizing bug reports. In that work, the domain-adapted models matched or outperformed a general-purpose base model five times their size on a range of chip design tasks.
- Verification, which confirms that a finished design behaves as intended, is the longest stage. Dally’s team is working to compress it using AI.
Yes, but: Designing a GPU from end-to-end based on a prompt remains a distant goal, Dally said.
Behind the news: AI is not yet designing chips from scratch, but it is making steady progress toward that goal.
- A paper published in April by Verkoran, an AI chip-design startup, described an agentic AI system that, given a 219-word specification, autonomously designed a 1.48 gigahertz RISC-V CPU chip, roughly equivalent to a 2011-vintage Intel Celeron SU2300. The authors validated the design in simulation but did not fabricate it.
- Last year, researchers at Princeton and Indian Institute of Technology Madras used deep learning and an evolutionary algorithm to generate wireless communications circuits, producing high-performing designs that defied conventional rules of thumb.
- In 2023, Google described its use of reinforcement learning to arrange components on the surface of its Tensor Processing Units.
- Nvidia first highlighted NVCell in 2021; the PrefixRL adder followed in 2022, and ChipNeMo in 2023.
Why it matters: In chip design, the search space is enormous and only thinly covered by human intuition. Nvidia’s report that its reinforcement learning agents produce unusual but measurably superior circuits echoes a broader pattern in which AI solves problems by finding solutions that human engineers would not consider. And the company is using GPUs to train the AI systems that have been designing its next generation of GPUs, so each chip generation both accelerates the design of the next and produces chips better suited to running the tools that helped to design it.
We’re thinking: There’s a considerable distance between “AI helps a junior engineer understand the company’s technology” and “AI designs the next GPU.” Dally’s willingness to temper expectations is refreshing.
AI at Work, Quantified
Half of workers in the United States used AI at work at least a few times last year, a sign of steadily rising AI adoption in U.S. workplaces.
What’s new: Most U.S. workers who used AI found that it boosted their productivity, according to a poll conducted by Gallup, an organization that surveys public opinion on a wide variety of topics. Respondents were most likely to use the technology when it fit into the way they worked and their employers supported it. Still, a sizable portion of employees and employers are holding out.
How it works: Gallup surveyed 23,700 U.S. employees between February 4 and February 19 on a range of questions related to AI and work. They explored the technology’s impact on productivity, whether it is changing workflows, and whether organizations are supporting and integrating it. Some employees remain skeptical of AI, but the findings suggest that AI improves productivity and plays a larger role in organizations that support its use and provide suitable tools.
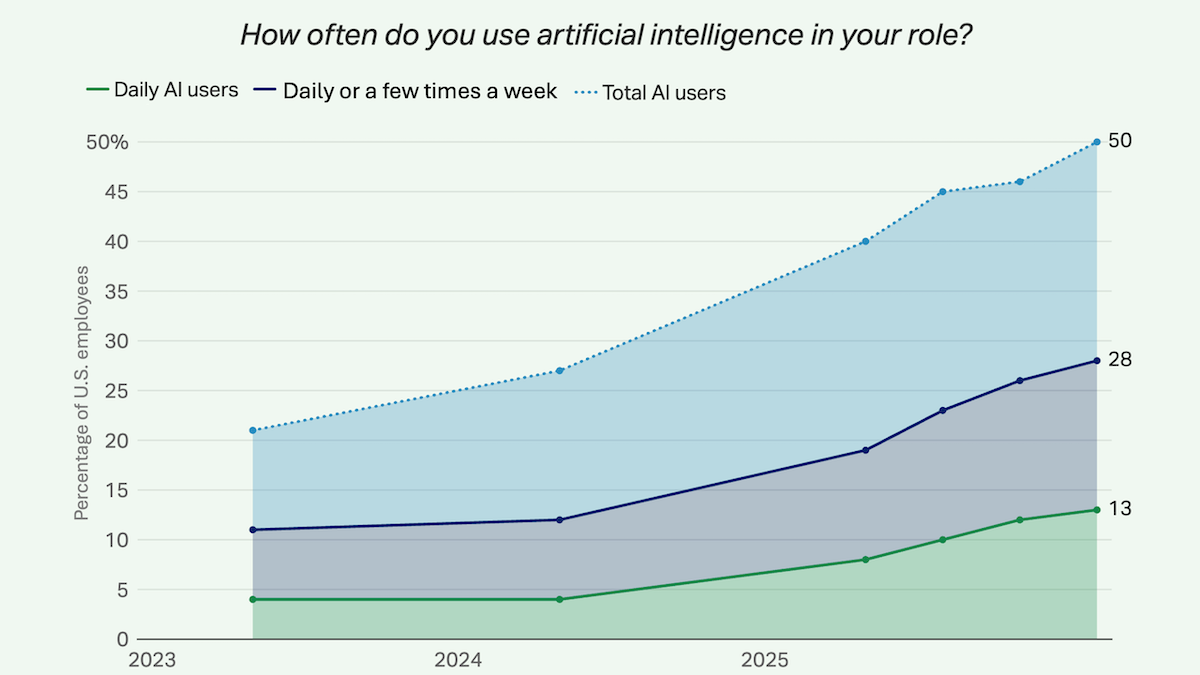
- Regular AI use is rising steadily. For example, 13 percent of respondents said they used AI daily, and 28 percent used it a few times a week. These figures are up from 4 percent and 11 percent respectively in 2023. At the organization level, two in five workers said their employers had introduced AI tools into the workplace and a quarter of companies had clear AI strategies.
- AI is boosting productivity but doesn’t yet substitute for established processes. Within companies where AI was used, 65 percent of employees said it improved their productivity, while 31 percent said it had changed the ways they worked. Only 7 percent of respondents who worked in organizations where AI was used disagreed that AI had affected how they worked.
- Managerial support influences employees’ behavior and outlook. Employees with strongly supportive managers in organizations that used AI were more likely to use AI and agree it had transformed their work.
- Low users and non-users widely indicated a desire to keep doing the work they do now. Other common barriers to AI adoption included ethical concerns, data privacy, and a belief or experience that AI wasn’t useful.
Behind the news: According to some accounts, AI’s impact has been disappointing relative to the promises made by tech evangelists. “AI is everywhere except in the incoming macroeconomic data,” such as metrics that gauge employment, productivity, and inflation, writes Torsten Slok, chief economist at the investment firm Apollo. By other accounts, evidence is mounting that AI is impacting the job market. Research published by Stanford economists last year found that employment was declining for workers whose jobs may be affected by AI, such as software developers and customer-service representatives.
Why it matters: The Gallup results suggest that workers use AI to help them do their jobs, not to do their jobs for them. This can be good both for workers, who may be freed of monotonous tasks, and their employers, which may gain productivity. But AI has the potential to automate some positions entirely. The jury is still out regarding whether AI-driven productivity gains will reduce or increase overall employment.
We’re thinking: While it’s trendy in some circles to forecast massive job losses due to AI, current signals are conflicting, and some show that AI is boosting employment. For instance, a 2025 study by Brookings found that companies that invested in AI hired more workers. There are endless opportunities for workers to stand out by applying AI in imaginative, productive ways.

Robots That Adapt to New Tasks
Neural networks can forget how to perform earlier tasks as they learn new ones. A simple recipe addresses this problem for vision-language models, specifically in robotics applications.
What’s new: Jiaheng Hu, Jay Shim, and colleagues at University of Texas Austin, University of California Los Angeles, Nanyang Technological University, and Sony trained large vision-language-action models using a combination of reinforcement learning and low-rank adaptation (LoRA) to outperform established methods for robotics training in simulation. Their recipe reduced catastrophic forgetting, which can occur when models learn tasks sequentially.
Key insight: Together, large pretrained models, LoRA, and on-policy reinforcement learning reduce the amount of information a model can forget while training.
- The trend toward large pretrained models limits how much models can forget during post-training. In a model that has a huge number of parameters, small updates are likely to not interfere with existing knowledge.
- LoRA, which adjusts model weights by adding to them the product of two small matrices, limits how much models can change. Thus, when it’s applied at inference, it limits how much they can forget.
- On-policy reinforcement learning methods such as GRPO also limit updates, since they reward actions the model itself generated — so they, too, limit how much models can forget while learning new things. In contrast, supervised fine-tuning and off-policy reinforcement learning, which rewards models for taking actions that were chosen by a separate policy, can result in large updates if a model learns actions it might not have performed previously.
How it works: The authors fine-tuned a large pretrained vision-language-action (VLA) model (OpenVLA-OFT) on each of three task suites in the LIBERO benchmark executed by a simulated robot arm. Each suite contained five tasks such as opening a drawer or moving an object to a target location. The authors fine-tuned the models on each task sequentially.
- At each step, a model took as input an image and instruction, and it predicted a sequence of continuous actions to control the robot arm and gripper.
- The authors fine-tuned the models using GRPO and LoRA without reusing data from previous tasks to train on new tasks. During GRPO, the model received a reward for completing each task.
Results: The authors’ method matched or outperformed earlier methods for iteratively learning robotics tasks, which the authors combined with GRPO and LoRA for fair comparison. It resulted in very little forgetting as well as slight improvement on tasks that models had not encountered during fine-tuning. Removing any individual component caused performance to collapse and led to strong forgetting.
- On the libero-spatial tasks, the authors’ method reached 81.2 percent average success rate. This result exceeded Dark Experience Replay (73.4), an approach that reuses data; SLCA (69.9), which uses higher learning rates in output layers and lower learning rates in earlier layers, so early layers change less during training; and Elastic Weight Consolidation (66.1), which aims to preserve knowledge by penalizing changes to weights that were important for previous tasks.
- The authors’ method showed near-zero forgetting (0.3 percentage point average drop in success rate on previously learned tasks) on libero-spatial, lower than Elastic Weight Consolidation (0.7) and Dark Experience Replay (4.7), and comparable to SLCA (-0.6, meaning performance on earlier tasks improved slightly).
- On five additional libero-spatial tasks, the model did not encounter during training, the authors’ method reached 57.1 percent average success rate, outperforming Elastic Weight Consolidation (52.6) and Dark Experience Replay (55.2).
Yes, but: In their comparisons, the authors added to the earlier methods LoRA and GRPO using the LIBERO dataset. But the earlier methods weren’t designed to combine with those techniques or use that data, and it’s not clear how they would have compared had they been applied strictly as intended. For instance, Dark Experience Replay, while fine-tuning a model on a new task, aims to avoid forgetting by re-introducing examples that were used in fine-tuning for earlier tasks. Adding LoRA may affect the learning of new tasks.
Why it matters: Training a robot on all tasks at once can be effective, but it requires that all tasks are mapped out ahead of time. If tasks change, it becomes helpful to train on one task at a time, and in many cases it’s valuable to retain earlier training. Relative to prior methods, the authors’ sequential fine-tuning approach is simpler, easier to understand, and more effective under the conditions they tested. (The authors didn’t explore whether it would be effective beyond robotics.)
We’re thinking: Robots are rapidly entering new environments and situations. Nimble operations will benefit from robots that adapt to new tasks on the fly.