A Full Accounting of Models’ GPU Use: Researchers detail the energy and water needed to train a family of open weight models
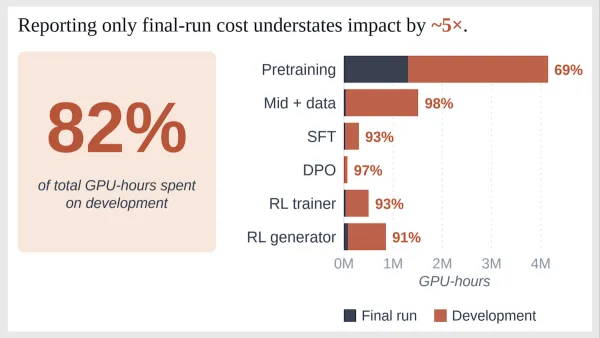
Assessments of the environmental impact of large language models typically focus on their final training runs, but there’s a lot more to building AI systems.