Toward Agent Benchmarks That Reflect Human Work: AI agents may not be getting better at full range of economically valuable labor
AI agents seem to be increasingly capable of performing economically valuable tasks, but current benchmarks measure this capability only narrowly.
AI agents seem to be increasingly capable of performing economically valuable tasks, but current benchmarks measure this capability only narrowly.
What’s new: Zora Z. Wang and colleagues at Carnegie Mellon University and Stanford University mapped examples drawn from agent benchmarks to statistics that represent U.S. labor. The mapping revealed a mismatch between the tests, which generally emphasize software development, and the more varied work most people do.
Key insight: Engineers tend to describe benchmark examples in technical terms, like “implement bubble sort,” while economists describe work activities using standardized descriptions like “Write, update, and maintain computer programs or software packages to handle specific tasks such as tracking inventory, storing or retrieving data, or controlling other equipment.” Work is also described in terms of skills necessary to do a job, such as “working with computers.” A large language model can translate among these languages. This capability makes it possible to compare the relative distributions of benchmark examples and work activities and skill.
How it works: The authors collected a representative selection of more than 10,000 examples drawn from 43 agent benchmarks, such as SWE-bench and WebArena. The authors built two taxonomies based on the U.S. government’s O*NET: (i) occupations (including 5,806 computer-based work activities) and (ii) 41 related skills.
- They retrieved the number of people employed in the U.S. and median wages data for each occupation and calculated the total number of workers and capital (employment multiplied by wages) associated with each occupation and skill.
- They used Claude 3.5 Sonnet to match the benchmark examples to all relevant computer-based work activities and skills (matching, for instance, the benchmark example “implement bubble sort” to the work activity “write, update, and maintain computer programs . . . ” and the skill “working with computers”).
- To limit their expenses, they randomly sampled batches of five examples at a time from each benchmark and mapped them to work activities and skills. When the total coverage in either taxonomy increased by less than 0.1 percent, they stopped. In practice, this meant that, if the benchmark contained less than 300 examples, they included all of them; for most other benchmarks, they sampled roughly 300 examples.
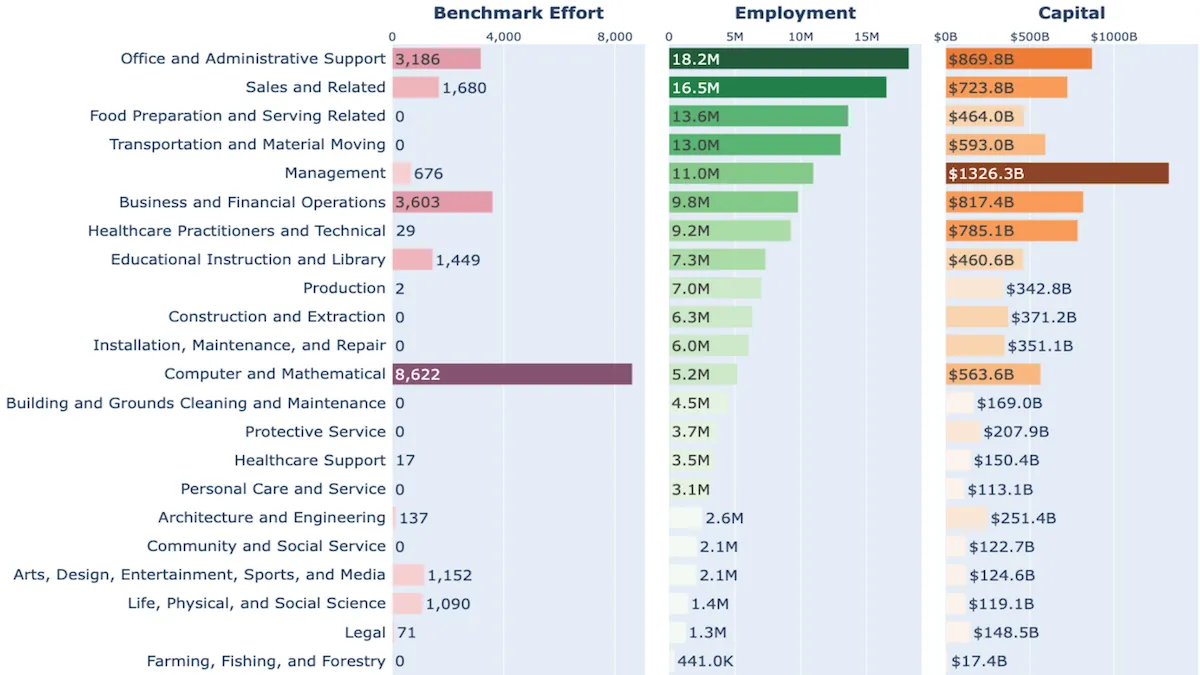
Results: The mapping showed that agent benchmarks largely measure performance in software engineering, which is distinctly different from the distribution of broader employment and capital within the job market.
- The benchmarks focus much more on “computer and mathematical” occupations (8,622 examples) than “office and administrative support” (3,186 examples) and “management” (676 examples). In comparison, the U.S. employs significantly fewer employees in “computer and mathematical” professions (5.2 million employees) than “office and administrative support” (18.2 million) and “management” (11 million). Similarly, U.S. employers pay “computer and mathematical” professionals a total of 563.6 billion dollars a year, hundreds of billions of dollars less than “office and administrative support” ($869.8 billion) and “management” ($1326.3 billion).
- Each benchmark covered less than 50 percent of all work activities and less than 60 percent of all skills. The benchmark that best covered both categories is GDPval, which encompassed 47.8 percent of work activities and 58.5 percent of skills. All benchmarks put together covered 56.5 percent of work activities, though they covered 85.4 percent of the authors’ 41 skill categories.
Why it matters: Agents have rapidly boosted productivity in software engineering, and they could do the same for other occupations that make up a large share of the economy. Identifying the gap between agent benchmarks and human labor distribution highlights untapped opportunities. Building agents for administrative, financial, and managerial sectors could yield higher economic value and help a larger portion of the workforce.
We're thinking: It makes sense that current benchmarks of agentic performance focus on software engineering — agentic coding is on fire! In some ways, software engineering is an incubator for applying agentic AI to other kinds of work, and we trust that benchmarks for measuring performance in broader work activities will come in due course.