Built-In Conversational Interactivity: Thinking Machines reveals its first interaction model, a new type of multimodal AI
Conversational models typically wait for a turn before they respond.
Conversational models typically wait for a turn before they respond. A system from Thinking Machines Lab listens, watches, and replies at the same time.
What’s new: TML-Interaction-Small is a multimodal system that processes audio, video, and text input and generates output concurrently rather than waiting for a user to finish. It’s currently undergoing tests, and Thinking Machines Lab expects to make it available later this year.
- Input/output: Concurrent audio, video, text in, concurrent audio and text out
- Architecture: Mixture-of-experts transformer (276 billion parameters total, 12 billion parameters active per token), separate background-reasoning model of undisclosed architecture
- Features: Real-time turn-taking and interruption, simultaneous input and output (for example, live translation), proactive interjection based on visual cues, plus a separate model that reasons and calls tools without interrupting conversation
- Performance: Leads other voice models on interactivity benchmarks but trails GPT-Realtime-2’s strongest reasoning mode on intelligence benchmarks
- Availability: Closed research preview in coming months, wider release later in 2026
- Undisclosed: Training data and methods, knowledge cutoff, context window, pricing, background model architecture
How it works: TML-Interaction-Small pairs two components: a fast interaction model that processes conversations in real time, and an asynchronous background model that performs reasoning. The interaction model interleaves 200-millisecond chunks of input processing and output generation, which Thinking Machines Lab calls micro-turns, rather than alternating between typical turns of input and output. It processes audio, video, and text as parallel streams, eliminating the perceived boundary between the end of an input and generation of an output.
- The interaction model takes in discretized audio tokens, embeddings of image patches of 40x40 pixels (produced by a hierarchical multilayer perceptron), and embeddings of text.
- It generates audio and text via a flow-matching decoder. Thinking Machines Lab calls this approach encoder-free early fusion because it skips large pretrained encoders that many multimodal systems require (like OpenAI Whisper uses for audio and vision transformers use for images). The team trained the transformer, perceptron, and decoder together from scratch.
- The interaction model delegates reasoning, web browsing, and tool calls to the background model, which runs asynchronously. Both share the same context. The interaction model weaves the background model’s output into the conversation when appropriate.
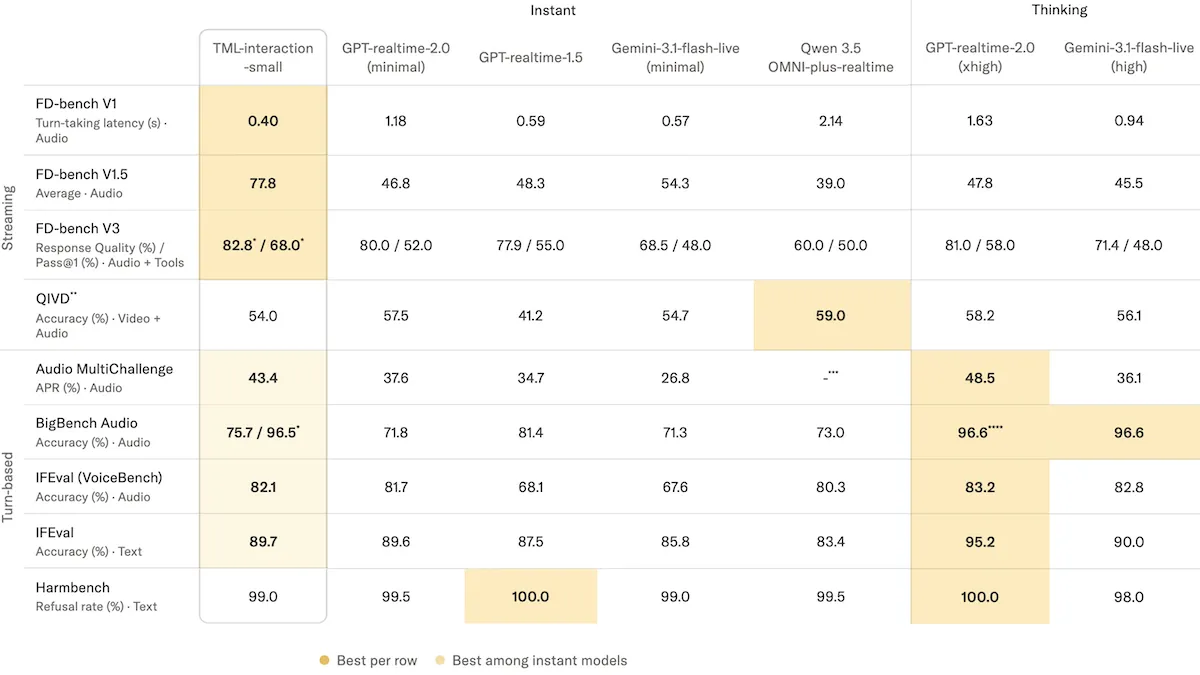
Performance: In Thinking Machines Lab’s tests, TML-Interaction-Small outperformed other voice models on benchmarks that evaluate interactivity but trailed GPT-Realtime-2’s strongest reasoning mode on tests of intelligence.
- On FD-bench V1, which measures audio latency in conversational turns, TML-Interaction-Small responded in 0.40 seconds, significantly faster than Gemini-3.1-flash-live-preview set to minimal reasoning (0.57) and GPT-Realtime-2 set to minimal reasoning (1.18 seconds).
- On FD-bench V1.5, which gauges a model’s ability to manage interruptions, interjections such as “uh huh,” and foreground versus background speech, TML-Interaction-Small achieved 77.8 average quality, well above GPT-Realtime-2 set to xhigh reasoning (47.8 average quality) and Gemini-3.1-flash-live-preview set to high reasoning (45.5 average quality).
- On Audio MultiChallenge, which tests reasoning and following instructions in multi-turn audio dialogue, TML-Interaction-Small achieved 43.4 percent APR (average pass rate, the share of conversations in which the model satisfied all criteria), behind GPT-Realtime-2 set to xhigh reasoning (48.5 percent APR) but ahead of Gemini-3.1-flash-live-preview set to high reasoning (36.1 percent APR).
- On BigBench Audio, a test of audio reasoning, TML-Interaction-Small achieved 96.5 percent accuracy with its background model activated, slightly below GPT-Realtime-2 set to high reasoning and Gemini-3.1-flash-live-preview set to high reasoning (tied at 96.6 percent accuracy).
Behind the news: TML-Interaction-Small, which arrives roughly 15 months after Mira Murati founded Thinking Machines Lab, promises to be the company’s first public model. The startup shipped a fine-tuning API called Tinker in October. This year, four other companies have launched models that listen, speak, and see videos or images in real time, and handle interruptions gracefully: OpenBMB open-sourced the 9-billion-parameter MiniCPM-o 4.5 in February, Google launched Gemini 3.1 Flash Live and Alibaba launched Qwen3.5 Omni in March, and OpenAI launched GPT-Realtime-2 in May.
Why it matters: Multimodal models often make users wait a second or more before responding, like GPT-Realtime-2, or they don’t respond to cues appropriately. Models that listen, see, and respond in real time open up interactions that turn-based systems can’t support like, say, coaching athletics or monitoring surgery. Of such models whose sizes are disclosed, TML-Interaction-Small is the largest to be trained specifically for interactive performance — 276 billion parameters versus 9 billion for MiniCPM-o 4.5, the most architecturally similar competitor whose parameter count is publicly known. Thinking Machines Lab said it has larger pretrained interaction models but can’t yet serve them fast enough for real-time interaction, and it plans to release them later this year.
We’re thinking: It’s worth noting how TML-Interaction-Small’s architecture differs from the approach taken by Vocal Bridge, an AI Fund portfolio company that we covered previously. While TML-Interaction-Small’s foreground and background models are jointly trained, Vocal Bridge takes an orchestration approach: A real-time voice model uses tool calls to defer heavy queries to a separate reasoning model and weaves its output back into the conversation. The upside is flexibility, since any real-time model can be paired with any reasoner, no training required. The downsides are that latency is bounded by the underlying API, the system is fundamentally turn-based, and handoffs between foreground and background are orchestrated rather than learned.