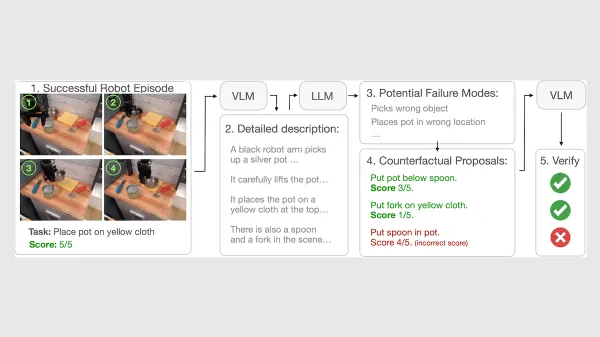
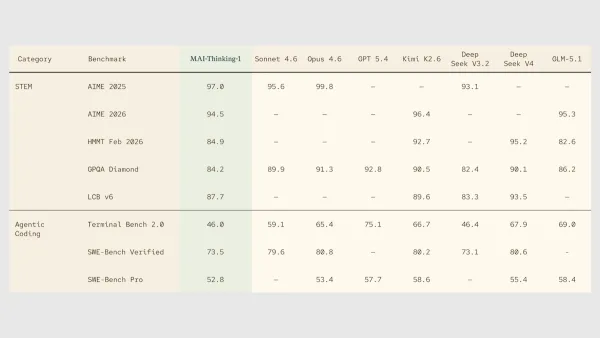
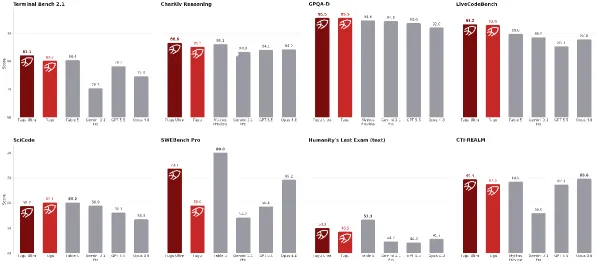
Cybersecurity Alarms Grow Louder: Google study shows LLM-generated malware is getting harder to track and stop
An AI-generated script to bypass two-factor authentication signals a dawning era of industrial-scale cyberattacks, according to a Google report.

An AI-generated script to bypass two-factor authentication signals a dawning era of industrial-scale cyberattacks, according to a Google report.
What’s new: Hackers used a large language model to identify a previously unknown vulnerability that made it possible for them to commandeer a widely used web administration tool, security researchers at Google reported. The researchers believe a criminal planned to use the technique on a large scale, and its discovery thwarted a broader attack. Their study outlines a variety of cybersecurity threats posed by the steady advance of large language models.
How it works: The Google team identified several ways in which large language models are making it faster and easier to execute cyberattacks. LLMs have aided cyberattacks before, and Anthropic recently warned that its Claude Mythos Preview model can find previously unknown vulnerabilities, but the report offers a catalog of up-and-coming approaches.
- Morphing malware: LLMs can generate malware that evades detection by changing elements of its code. Such programs include a so-called mutation engine that, every time they replicate or infect a new system, rewrite their own decryption routines, swap commands for alternatives that accomplish the same results, add nonfunctional subroutines, and so on without changing their functions. This approach can evade antivirus detection while keeping malicious payloads intact, increasing the danger of attacks that steal data, install backdoors, or encrypt files.
- Identifying logical flaws: Unlike tools typically used by cybersecurity professionals to find bugs in code, which often work by finding known patterns or bombarding it with random data until it breaks, LLMs can reason about what code is intended to do and apply that reasoning to identify logical flaws. This capability can discover vulnerabilities that are invisible to the usual tools and would require a focused review by human experts to find.
- Obfuscation networks: Threat actors often orchestrate ad hoc sets of routers, servers, and specialized technology to hide their points of origin, cover their tracks, and bypass defenses. AI-powered tools can direct malicious traffic through multiple compromised intermediary servers while avoiding patterns that would alert typical security monitors.
- Insecure AI infrastructure: AI infrastructure itself is becoming an attractive target for hackers. Beyond using AI to mask attacks, attackers increasingly target AI tools, models, and accessory software as entry points into networks. Compromising insecure components gives attackers a foothold to spread deeper into systems and steal data, deploy ransomware, or disrupt operations.
Behind the news: Security personnel and policy makers are reviewing defenses and governance measures in light of Claude Mythos Preview. Researchers at the cybersecurity firm Calif used that model to penetrate Apple’s famously sturdy security. Calif brought the exploit to Apple, which is working on a patch. Meanwhile, the United Kingdom-backed AI Security Institute (AISI) reported that Claude Mythos Preview and OpenAI’s GPT-5.5 could reliably execute attacks that would be expected to take humans 3 hours — substantially longer than their previous forecast of 1 hour. (At its debut, Claude Opus 4.6 was able to execute attacks that take people 30 minutes.) AISI’s tests limited the models to 2.5 million output tokens. When they allowed the models to use more tokens, the models were able to execute attacks that would take human attackers longer.
Why it matters: Google’s findings point to a widening gap between the ability of LLMs to find security vulnerabilities and widely used security methods. The report’s description of automated, industrial-scale attacks implies that next-gen LLMs may be able to exploit bugs faster than cyber teams can implement patches. Its findings may spur further federal scrutiny and complicate both regulatory and commercial efforts, as AI is both a defensive and an offensive tool as well as a prime target of attacks.
We’re thinking: Experts who have used Claude Mythos Preview confirm that it’s a clear advance for both security threats and defenses. We’re optimistic that the current round of patches will make networks more secure, and the lessons learned will contribute to safe roll-outs of further AI advances. Beyond that, software developers will need to devote more attention to proactive defensive research so they discover vulnerabilities before threat actors do.