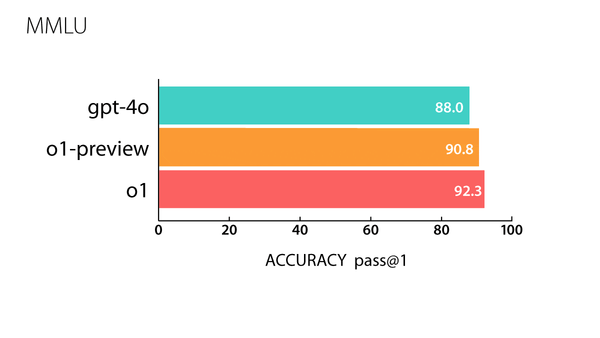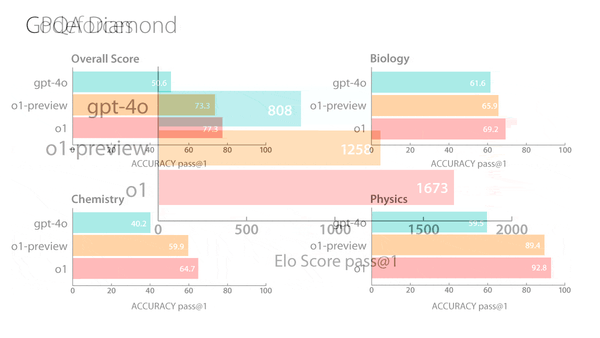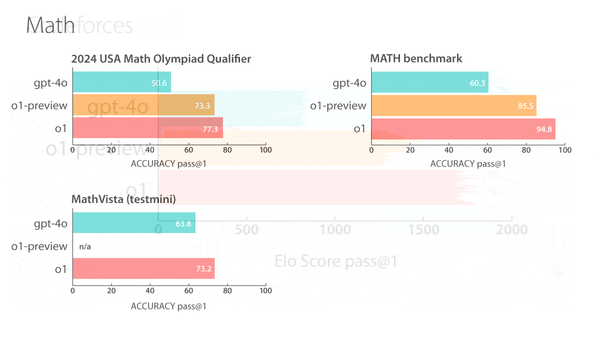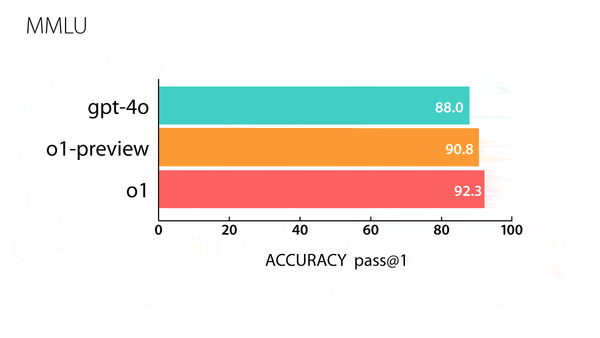
Machine Learning Research
Enabling LLMs to Read Spreadsheets: A method to process large spreadsheets for accurate question answering
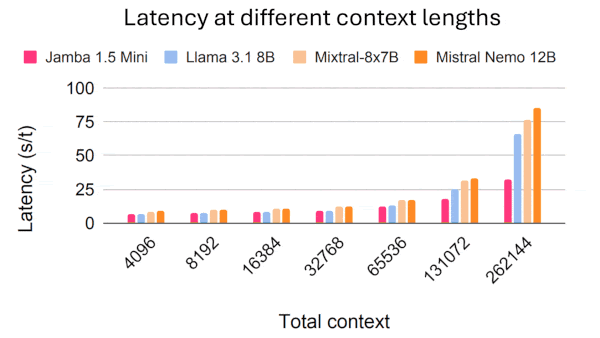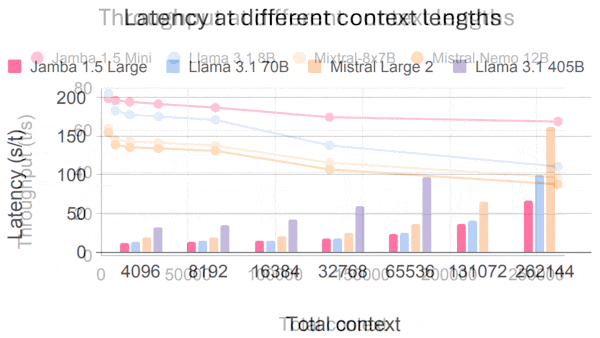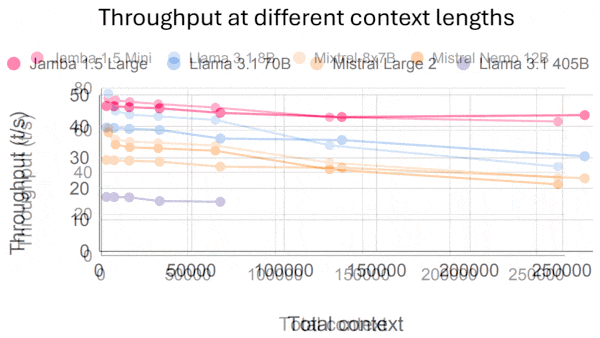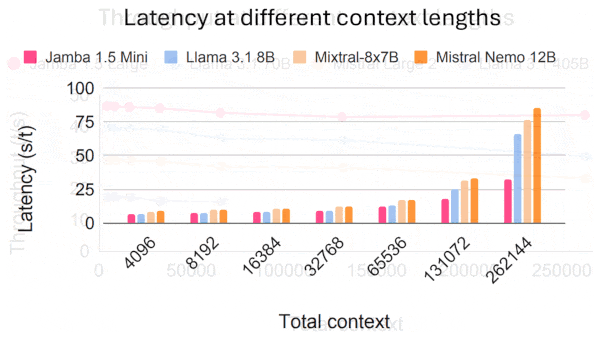
Large language models can process small spreadsheets, but very large spreadsheets often exceed their limits for input length. Researchers devised a method that processes large spreadsheets so LLMs can answer questions about them.