Machine Learning Research
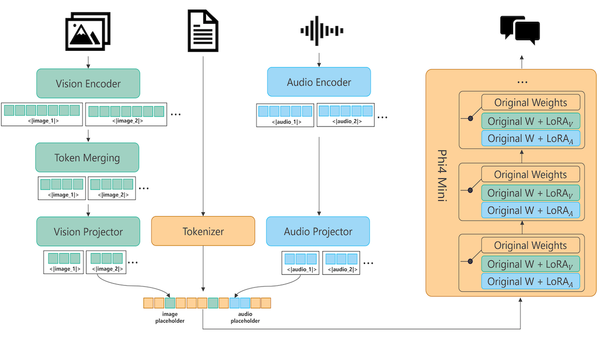
Microsoft Tackles Voice-In, Text-Out: Microsoft’s Phi-4 Multimodal model can process text, images, and speech simultaneously
Microsoft debuted its first official large language model that responds to spoken input.

Machine Learning Research
Microsoft debuted its first official large language model that responds to spoken input.
Machine Learning Research
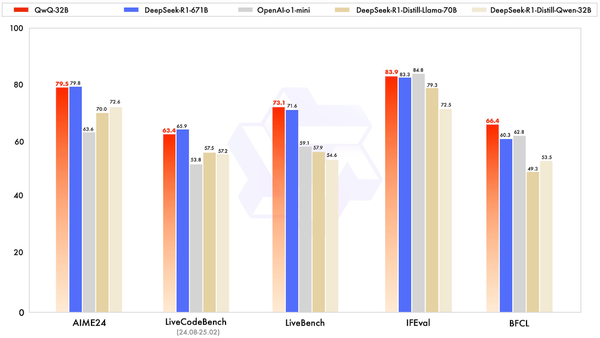
Most models that have learned to reason via reinforcement learning were huge models. A much smaller model now competes with them.
Machine Learning Research
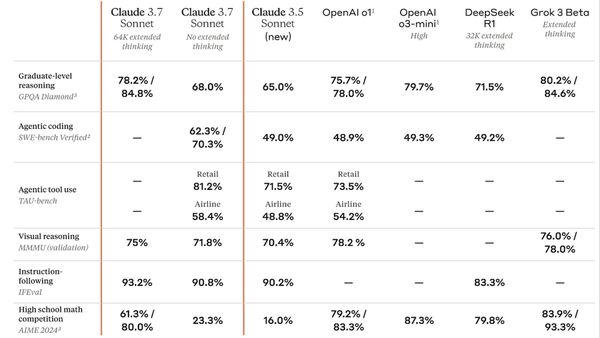
Anthropic’s Claude 3.7 Sonnet implements a hybrid reasoning approach that lets users decide how much thinking they want the model to do before it renders a response.
Machine Learning Research
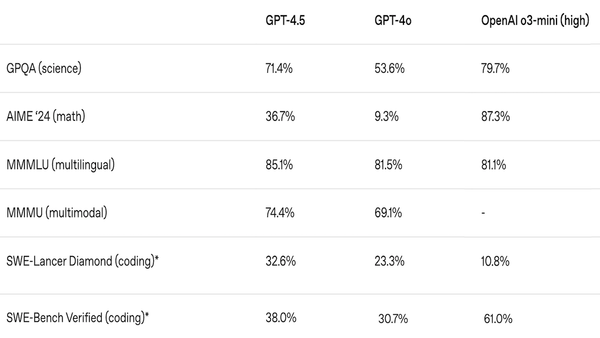
OpenAI launched GPT-4.5, which may be its last non-reasoning model.
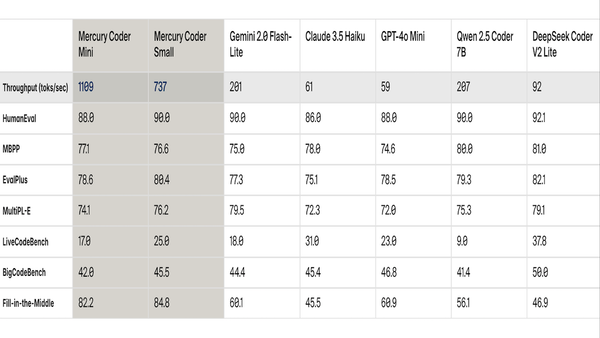
Machine Learning Research
Typical large language models are autoregressive, predicting the next token, one at a time, from left to right. A new model hones all text tokens at once.
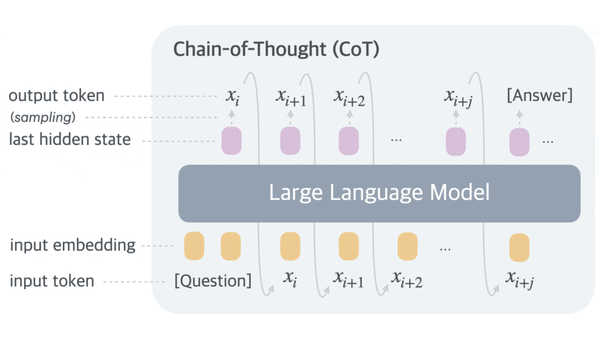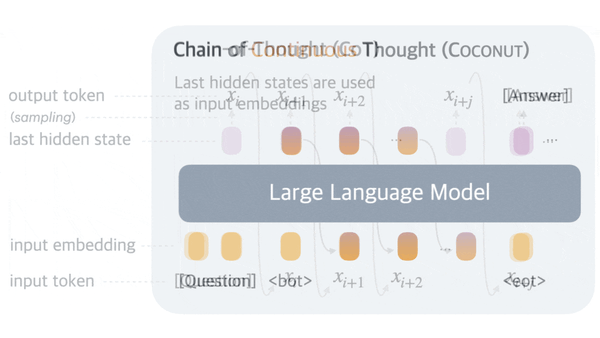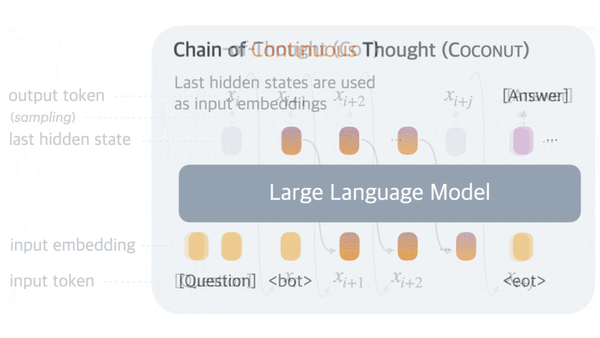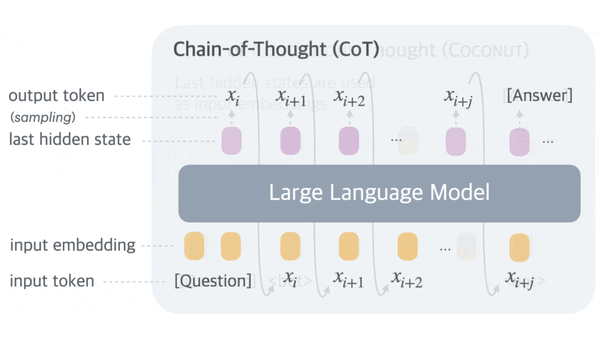
Machine Learning Research
Although large language models can improve their performance by generating a chain of thought (CoT) — intermediate text tokens that break down the process of responding to a prompt into a series of steps.

Machine Learning Research
Replit, an AI-driven integrated development environment, updated its mobile app to generate further mobile apps to order.

Machine Learning Research
xAI’s new model family suggests that devoting more computation to training remains a viable path to building more capable AI.

Machine Learning Research
Browsing the web to achieve a specific goal can be challenging for agents based on large language models and even for vision-language models that can process onscreen images of a browser.
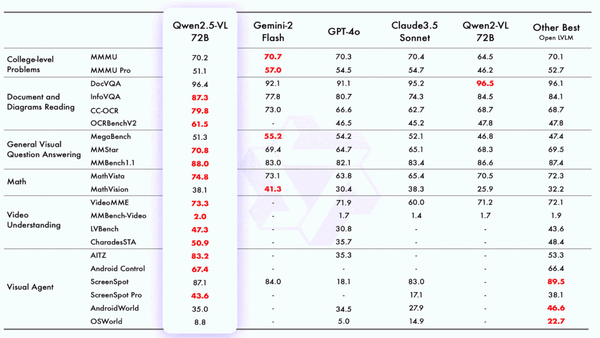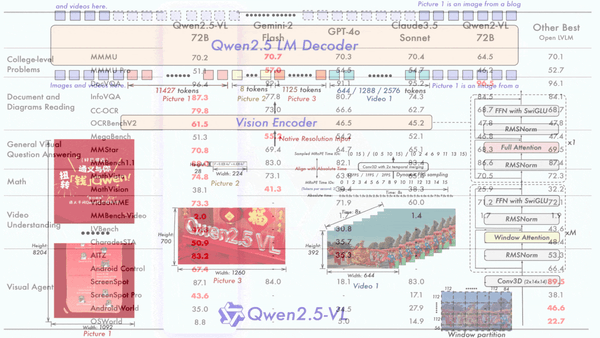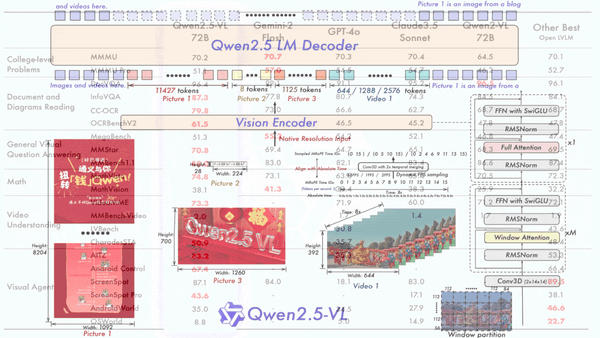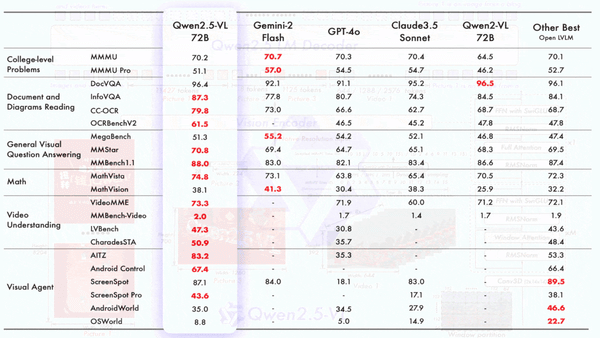
Machine Learning Research
While Hangzhou’s DeepSeek flexed its muscles, Chinese tech giant Alibaba vied for the spotlight with new open vision-language models.
Machine Learning Research
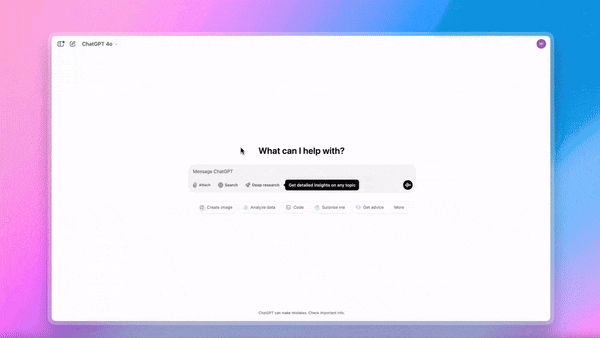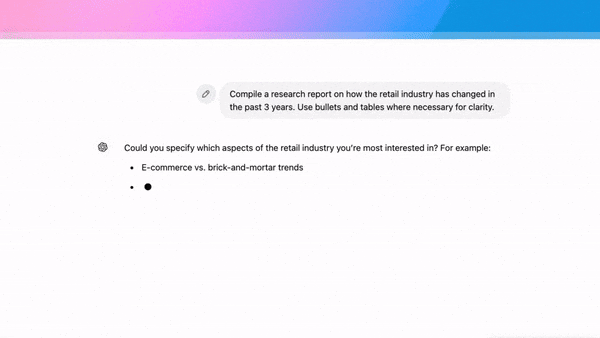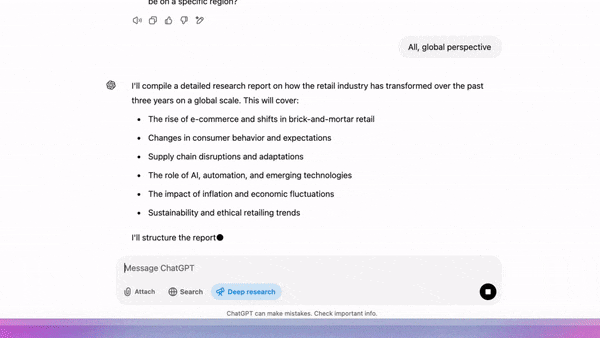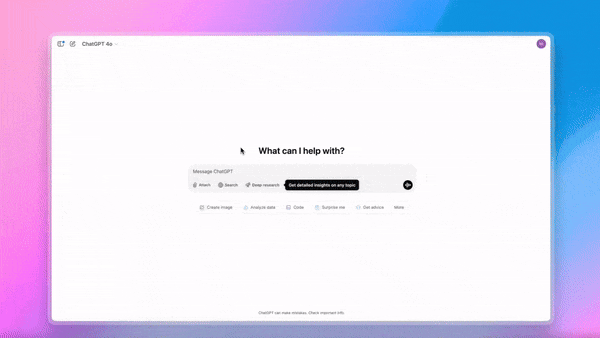
OpenAI introduced a state-of-the-art agent that produces research reports by scouring the web and reasoning over what it finds.

Machine Learning Research
Even cutting-edge, end-to-end, speech-to-speech systems like ChatGPT’s Advanced Voice Mode tend to get interrupted by interjections like “I see” and “uh-huh” that keep human conversations going. Researchers built an open alternative that’s designed to go with the flow of overlapping speech.