
Benchmarking Costs Climb: Reasoning LLMs Are Pricey to Test
An independent AI test lab detailed the rising cost of benchmarking reasoning models.
An independent AI test lab detailed the rising cost of benchmarking reasoning models.
What’s new: Artificial Analysis, an organization that tracks model performance and cost, revealed its budgets for evaluating a few recent models that improve their output by producing chains of thought, which use extra computation and thus boost the cost of inference. The expense is making it difficult for startups, academic labs, and other organizations that have limited resources to reproduce results reported by model developers, TechCrunch reported. (Disclosure: Andrew Ng is an investor in Artificial Analysis.)
How it works: Artificial Analysis tested reasoning and non-reasoning models on popular benchmarks that gauge model performance in responding to queries that require specialized knowledge or multi-step reasoning, solving math problems, generating computer programs, and the like.
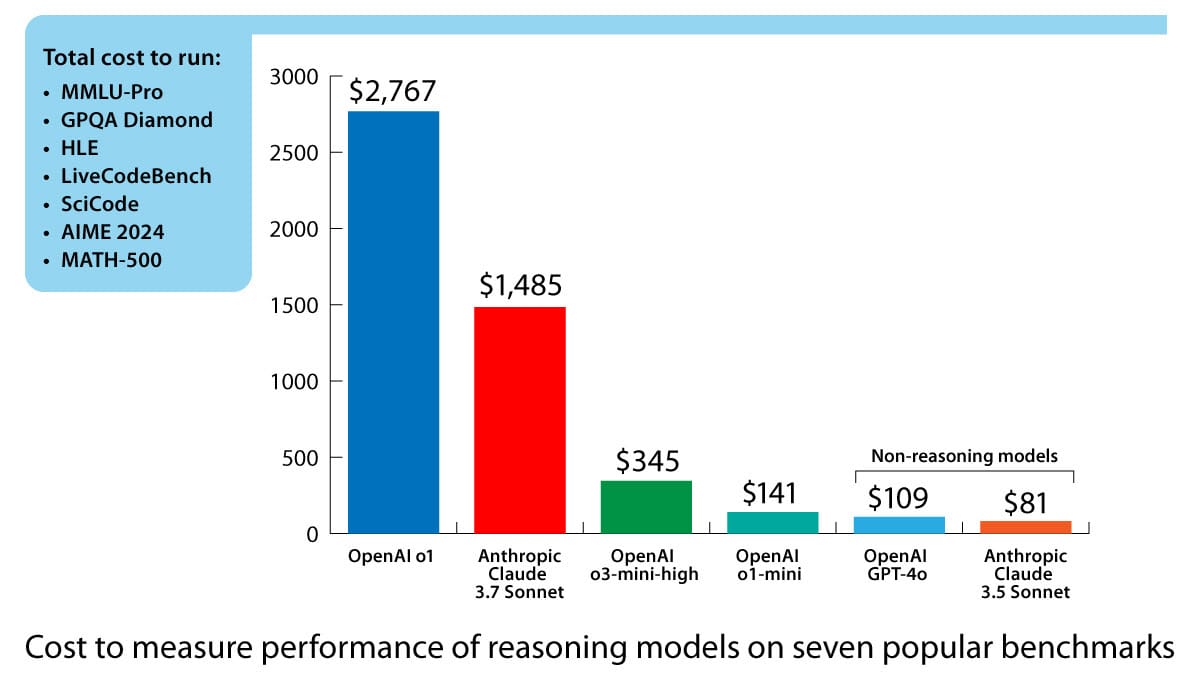
- Running a group of seven popular benchmarks, OpenAI o1 (which produces chains of thought) produced more than 44 million tokens, while GPT-4o (which doesn’t take explicit reasoning steps) produced around 5.5 million tokens.
- Benchmarking o1 cost $2,767, while benchmarking Anthropic Claude 3.7 Sonnet (which allows users to allocate a number of reasoning tokens per query; TechCrunch doesn’t provide the number in this case) cost $1,485. Smaller reasoning models are significantly less expensive: o3-mini (at high effort, which uses the highest number of reasoning tokens per query) cost $345, and o1-mini cost $141.
- Non-reasoning models are less expensive to test. Evaluating GPT-4o cost $109, Claude 3.5 Sonnet was $81.
- Artificial Analysis spent around $5,200 to test 12 reasoning models versus around $2,400 to test more than 80 non-reasoning models.
Behind the news: Generally, the cost per token of using AI models has been falling even as their performance has been rising. However, two factors complicate that trend. (i) Reasoning models produce more tokens and thus cost more to run, and (ii) developers are charging higher per-token prices to use their latest models. For example, o1-pro and GPT-4.5 (a non-reasoning model), both released in early 2025, cost $600 per million output tokens, while Claude 3.5 Sonnet (released in July 2024) costs $15 per million tokens of output. Emerging techniques that allow users to allocate numbers of tokens to reasoning (whether “high” or “low” or a specific tally) also make benchmarking more costly and complicated.
Why it matters: Benchmarks aren’t entirely sufficient for evaluating models, but they are a critical indicator of relative performance, and independent benchmarking helps to ensure that tests are run in a fair and consistent way. As the cost of benchmarking climbs, fewer labs are likely to confirm or challenge results obtained by the original developer, making it harder to compare models and recognize progress.
We’re thinking: Verifying performance claims in independent, open, fair tests is essential to marking progress in general and choosing the right models for particular projects. It's time for the industry to support independent benchmarking organizations.



