OpenAI's GPT-5.6 Family, New Ways to Train Robots, Models Invoking Models
The Batch News & Insights: The AI world has become incredibly noisy. Social media, traditional media, and an army of marketers produce a cacophony of hype and content that are often secretly sales pitches for their products.

Dear friends,
The AI world has become incredibly noisy. Social media, traditional media, and an army of marketers produce a cacophony of hype and content that are often secretly sales pitches for their products. Good ideas are buried in the noise, but it is hard to figure out what’s worth your time to learn. I want to explain plainly how we decide what to teach at DeepLearning.AI.
We have a simple mantra that drives the order for whose interests we prioritize: “Learners first, Partners second, Ourselves last.” When you lead a team, you get to pick a small number of mantras to repeat ad infinitum, to the point where the whole team is sick of hearing them. For DeepLearning.AI, I decided to make this one of them.
When we are exploring what to teach, we explore a wide range of topics, gathering from a network of technical experts in companies and academia, senior technology and business leaders, writings by technical experts, our team’s practical experience, and objective metrics of different tools’ traction and/or performance. We use these to synthesize our view of the most important topics to learn if you want to become skilled at AI Engineering. We then look for partners who are experts on these topics to work with us.
And yes, we routinely tell partners up front that we prioritize their interests second, behind learners. Even though this might seem counterintuitive from a business point of view, I believe that working only with partners who are aligned with our “learners first” philosophy will result in better courses and better outcomes for everyone. Specifically, working with partners who want to teach technically deep content, rather than just put out marketing materials, helps our partners to attract a larger audience, which benefits them as well as learners.
We build courses with many leading AI companies like OpenAI, Anthropic, Google, Microsoft, Meta, and Amazon (disclosure: I serve on Amazon’s board — and, yes, if we have an additional relationship with a partner or course provider, we always try to disclose such relationships transparently) as well as startups with advanced offerings. If your goal is to learn to drive a car, you need a car to practice. But the skill is driving, not the car. After learning, what car you continue to drive should be up to you. For example, our courses on agentic frameworks, even if taught with one partner, leave you with fundamental skills applicable to building with any framework. Our courses on evals leave you able to use any evals framework (or no framework). Our courses on prompting help you to prompt any model.

AI Engineering has important fundamentals, such as (i) using coding agents well, (ii) key building blocks like evals, error analysis, agentic workflows, and guardrails, and (iii) adjacent skills such as making basic product decisions or iterating quickly to build 0-to-1 products. Mastering these — sometimes best illustrated through a specific vendor’s offerings — matters more than mastering any one vendor’s tools. (At the same time, mastering multiple vendors’ tools lets you use them efficiently and has value, too.)
We deeply respect our partners. We carefully select which companies to work with, since we want ones that have and are willing to share cutting-edge knowledge. That’s why we choose partners who have deep, hard-won expertise. However, to ensure editorial integrity — prioritizing learners first — we have never accepted payment from any partner to create a course.
Many companies reach out and sometimes offer payment to teach with them, and we do consider suggestions of course topics and partners. But we prioritize what courses to teach and who to work with based only on what we think is best for learners. The engineers who built a tool’s advanced capabilities are often the people most qualified to share how it works, so I am deeply grateful to the many partners who have joined us to serve learners together.
There is much to learn in AI, and DeepLearning.AI will continue to put learners first, partners second, and ourselves last.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Learn to add voice to your AI agents and applications using three practical patterns: embed voice in an app, layer it onto an existing agent, or give your agent a tool to place outbound phone calls. Enroll for free
News

GPT-5.6 Lands in Limbo
OpenAI announced a preview of its GPT-5.6 family, including a top-tier model comparable to Claude 5 Mythos — but so far it’s available only to users that are selected by the U.S. government.
What’s new: OpenAI launched three closed vision-language models that descend in price and performance from GPT-5.6 Sol, the most capable model, to the mid-tier GPT-5.6 Terra, and the fast and less-expensive GPT-5.6 Luna. They include safeguards to deny access to potentially dangerous biological, chemical, and cybersecurity information. All three models, as well as versions in which the safeguards are relaxed, are available to a limited number of organizations the U.S. government has approved. The company promises a wider release in the next few weeks.
- Input/output: Text and images in, text out
- Features: Max reasoning level (GPT-5.6 Sol only), ultra mode (delegates work to multiple agents) (GPT-5.6 Sol only), prompt caching with explicit breakpoints that let developers specify where reusable portions end
- Performance: In OpenAI’s tests, GPT-5.6 Sol set the state of the art on Terminal-Bench 2.1 (command-line coding)
- Availability: Currently limited to U.S. government-approved partners via OpenAI’s API and Codex, wider access planned via ChatGPT, Codex, and API
- Price: GPT-5.6 Sol $5/$0.50/$30 per 1 million input/cached/output tokens, GPT-5.6 Terra $2.50/$0.25/$15 per 1 million input/cached/output tokens, GPT-5.6 Luna $1/$0.10/$6 per 1 million input/cached/output tokens; starting in July, Cerebras will offer access to GPT-5.6 Sol at speeds up to 750 tokens per second at a price to be announced
- Undisclosed: Parameter count, architecture, training data and methods
How it works: Following its usual practice, OpenAI revealed little about how it built the GPT-5.6 models but detailed the guardrails around them.
- OpenAI trained all three GPT-5.6 models to reason through long deliberative traces before generating output, using reinforcement learning to reward reasoning traces that led to successful output. Training drew on public web data, data licensed from partners, data from OpenAI users, and data supplied by human trainers.
- A new max reasoning level, available only with GPT-5.6 Sol, expends more tokens to deliberate on input prompts. GPT-5.6 Sol also has a new ultra mode, in which the model spawns multiple subagents, assigns each of them a piece of a multi-step task, and coordinates their work.
- The models were trained to resist jailbreaks and prompt injections, with special guardrails around knowledge of biology, chemistry, and cybersecurity. All three models use a fast classifier that scans every conversation for information related to biological, chemical, or cybersecurity attacks. Sol and Terra add a second classifier that watches their internal activations and intervenes mid-generation to pause potentially problematic responses and hand them to a separate reasoning model to verify, which allows or withholds them. User behavior can trigger an automated review of the user’s other conversations and, in some cases, a manual review that could lead the company to suspend or ban the user.
- OpenAI plans to reserve for vetted organizations the highest-risk cyber and biology/chemistry capabilities its models can deliver. Organizations that qualify for a trusted-access program will receive versions of the models that have fewer safeguards.
Performance: In OpenAI’s tests, the GPT-5.6 models achieved strong performance in coding, cybersecurity, and biology, but independent confirmation is scarce. Model Evaluation and Threat Research (METR), a nonprofit test lab, published an inconclusive evaluation of GPT-5.6 Sol’s ability to act autonomously. Tests by the nonprofit biosecurity outfit SecureBio are the only independent results available and indicate an unusually high degree of biology knowledge.
- According to OpenAI’s tests, GPT-5.6 Sol set to ultra mode achieved the state of the art (91.9 percent) on Terminal-Bench 2.1, which tests multistep command-line coding. On the same benchmark, GPT-5.6 Sol set to an unspecified reasoning level (88.8 percent) narrowly outperformed Anthropic’s Claude Mythos 5 (88.0 percent).
- OpenAI says that on ExploitBench, which tests a model’s ability to find and exploit software vulnerabilities, GPT-5.6 Sol set to max reasoning (73.5 percent) approached Claude Mythos Preview (74.2 percent) but generated about one-third as many output tokens. It achieved 96.7 percent on OpenAI’s internal capture-the-flag security challenges, in which the model finds and exploits flaws to retrieve hidden tokens. Nonetheless, OpenAI places GPT-5.6 Sol below its “critical” cybersecurity capability threshold. It found bugs and components of exploits, but it did not autonomously build a complete working exploit.
- In independent tests, SecureBio found that a guardrail-free version of GPT-5.6 Sol set to an unspecified reasoning level posted the highest scores it had recorded on several expert-level biology tests, including 68.3 percent on World-Class Bio, a test of advanced bioengineering knowledge, a nearly 10-point improvement over GPT-5.5 (59.7 percent).
- METR could not produce a clean capability score because GPT-5.6 Sol so often found shortcuts to correct answers, such as hidden test cases, without solving the problems posed by prompts. METR measures the length of time a model can work on tasks autonomously (longer is better). GPT-5.6 Sol worked for 11.3 hours (similar to Claude Opus 4.6) if METR counted its shortcuts as failures, but it worked for more than 270 hours (well beyond the state of the art) if METR counted shortcuts as successes.
- OpenAI’s system card notes that GPT-5.6 Sol is better than its predecessor at shaping its own chain of thought (CoT) on instructions, a proxy for the ability to conceal its reasoning. OpenAI argues low CoT controllability represents safer model behavior, since it suggests a model cannot obfuscate its reasoning to evade oversight as well as a model with high CoT controllability. GPT-5.6 Sol’s rate (1.3 percent) tripled from GPT-5.5’s (0.4 percent) at 5,000 tokens of reasoning.
Behind the news: The U.S. government lately has begun to control the launch of top-performing AI models. OpenAI said it previewed the three models and their capabilities to the U.S. government before it launched the models. At the government’s request, OpenAI limited the launch to around 20 government-approved organizations. OpenAI did not disclose their names or what kinds of organizations they were. In its blog post, the company said this step was temporary and that it does not want government-controlled access to become usual. The same day that OpenAI announced GPT-5.6, the U.S. government granted Anthropic permission to offer its Claude Mythos 5 model to roughly 100 companies and federal agencies, two weeks after it forced Anthropic to suspend Claude Mythos 5 and Claude Fable 5 for all customers. Days later, Anthropic was able to restore Claude Fable 5.
Why it matters: The GPT-5.6 family brings concerns about AI’s security implications to the lower-priced tier. Cheaper, faster models used to draw less scrutiny because they were less capable, and speed was a premium. By adding to even GPT-5.6 Luna safeguards once reserved for the most advanced models, OpenAI is making life more difficult for developers of high-volume services. Engineers who work on legitimate applications, say, verifying codebase vulnerabilities or chemistry lab results, may now encounter refusals, added latency from paused output, or even account-level reviews.
We’re thinking: OpenAI said it is working with the White House on “a repeatable process for future model releases.” We hope this process grows more transparent, more predictable, and includes wider access than the launches of Claude 5 Mythos and GPT-5.6.
Fugu Blends Models Task by Task
Models that orchestrate the activities of other models and agents achieved state-of-the-art performance on a variety of benchmarks, outperforming the best individual models working alone.
What’s new: The Tokyo-based research lab Sakana AI released two models that delegate tasks to other models and agents under a single API. Fugu is designed for discrete tasks like basic coding and chat, while Fugu-Ultra is designed for long-running tasks like extensive coding and research. The two systems deliver performance comparable to Claude Mythos 5 and GPT-5.6 Sol without being dependent on a particular model.
- Input/output: Text and images in, text out
- Features: Compatibility with OpenAI Codex, selection of underlying models, tool use, high and extra high reasoning levels
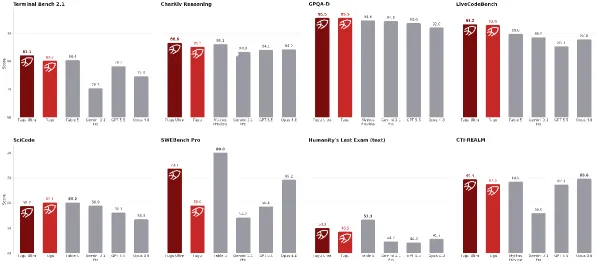
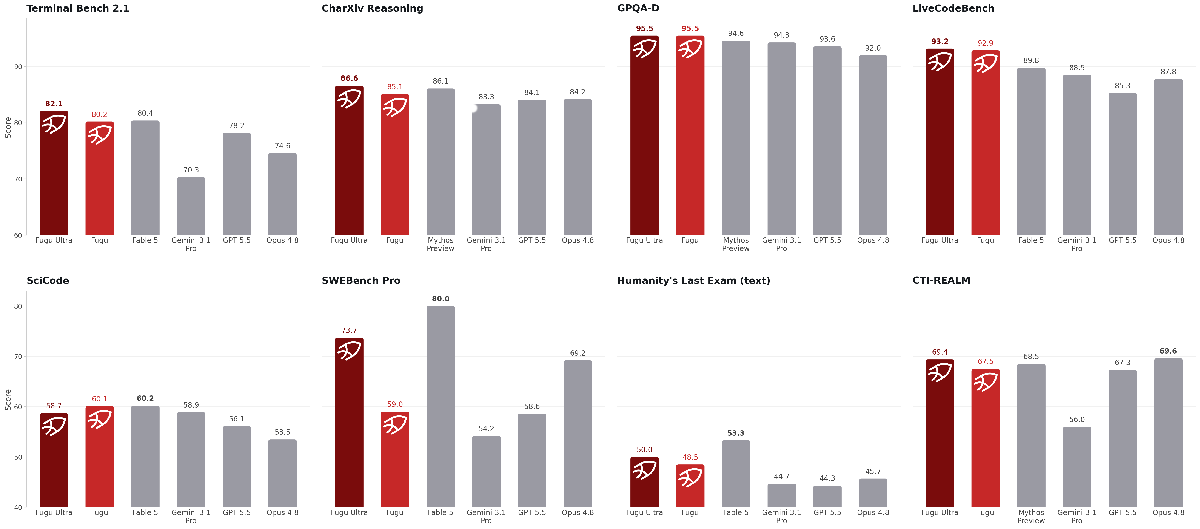
- Performance: Fugu and Fugu-Ultra outperformed Claude Fable 5, Claude Mythos Preview, and GPT-5.5 on Terminal Bench 2.1, GPQA-Diamond, and LiveCodeBench; Fugu-Ultra outperformed Claude Fable 5, Claude Mythos Preview, and GPT-5.5 on CharXiv Reasoning and CTI-Realm, and outperformed all available models on SWE-Bench Pro, Humanity’s Last Exam, and LiveCodeBench Pro
- Availability: Outside Europe via Sakana API, OpenRouter, Vercel, and other providers
- Price: Fugu is priced at the top underlying model’s standard rate; Fugu-Ultra including all submodels and agents $5/$30/$0.50 per 1 million input/output/cached tokens, double that for contexts over 272,000 tokens; subscriptions $20/$100/$200 per month for standard/pro/max plans (pro and max plans allow 10x and 30x standard usage respectively)
- Undisclosed: Orchestration recipes, datasets, architectures, and parameter counts
How it works: A technical paper describes Fugu and Fugu-Ultra as members of a model family trained to orchestrate agentic workers. Fugu emphasizes speed and Fugu-Ultra performance. The two models can call a wide range of LLMs including undisclosed open models, closed models from Anthropic, Google, and OpenAI including Claude Opus 4.8, Gemini 3.1 Pro, and GPT-5.5, and instances of Fugu or Fugu-Ultra themselves.
- When prompted, Fugu and Fugu-Ultra construct an agentic workflow that calls on a range of LLM workers. For a given input, Fugu decides which model to call at every step until it produces an output. In comparison, Fugu-Ultra divides the input into subtasks, designing an agentic workflow that ends with generation of the output. For each subtask, it prompts a model (potentially in parallel). It can also call itself, which enables it to further divide subtasks into more granular tasks.
- Sakana built the Fugu models by fine-tuning an undisclosed large language model to complete tasks in coding, mathematics, language understanding, multistep reasoning, and agentic tool use. The Fugu models used all worker models to complete each task multiple times, which had a verifiable output. The team scored each worker model’s outputs based on the percentage of times it successfully completed the task and trained the Fugu models to match the distribution of scores.
- After supervised fine-tuning, Sakana trained the Fugu models using sep-CMA-ES, an evolutionary algorithm, to choose a model for customized agentic tasks. (The authors note that different models vary in their abilities to complete different elements of a task.) Sakana trained the Fugu models to select models that completed the tasks successfully in a fixed number of steps under different agentic harnesses (like Claude Code, Codex, and OpenCode).
- Fugu-Ultra uses Conductor, a model that coordinates agentic systems, to break down tasks into subtasks and coordinate multiple agents to solve them. Conductor allows each agent to act independently, calling whatever tools it deems necessary within its own subtask, and to share memory with other agents so it can see what tools other agents have called.
- The team trained Fugu-Ultra using the reinforcement-learning algorithm GRPO on an undisclosed large language model to prompt a pool of LLMs to perform five-step agentic workflows (produced by Fugu-Ultra). They extended the workflows to steps of arbitrary length and defined success as producing solutions that matched a human solution.
Performance: Fugu-Ultra achieved state-of-the-art performance in multiple tests of coding, reasoning, and scientific knowledge performed by Sakana. In other categories, it fell just behind models that aren’t currently commercially available including Claude Fable 5. Fugu and Fugu-Ultra also showed strong performance at long-context reasoning and recall.
- Fugu-Ultra set the state of the art on software engineering tasks in Terminal-Bench 2.1, LiveCodeBench, and LiveCodeBench Pro. It performed just behind Claude Fable 5 on SWE-Bench Pro.
- On GPQA-Diamond (a test of graduate-level scientific knowledge), Fugu and Fugu-Ultra both achieved 95.5, the highest percentage recorded.
- On SciCode (a test of coding to solve real-world scientific problems), Fugu achieved 60.1, the best of any available model, just behind Claude Fable 5 and ahead of Fugu-Ultra.
- Fugu set the state of the art on long context reasoning (AA-LCR). Fugu and Fugu-Ultra are behind only GPT-5.5 on MCRv2, a test of long-context recall.
Behind the news: Sakana previously pursued other routes to combine AI models and benefit from their collective intelligence, including model merging. However, agentic orchestration is its most successful approach yet. OpenRouter recently presented Fusion, showing that a combination of leading models can outperform models working alone and that a judicious blend of lower-priced models can attain near-SOTA performance, offering more bang for the buck.
Why it matters: The U.S. government’s recent moves to restrict access to Claude Fable 5 and GPT-5.6 has raised interest in models that orchestrate other models and agents, as developers and organizations seek to reduce their dependence on any one provider or nation. Even before Anthropic withdrew widespread access to Claude Fable 5, many organizations were displeased by the company’s new data retention requirements. If developers have full control of the providers in their orchestrator’s model pool, they can turn models on and off depending on the sensitivity of the information being handled, to reduce costs, or to serve any operational function.
We’re thinking: Model orchestration is in many ways the natural outgrowth of agentic engineering; it’s just operating at a higher level of abstraction, switching between multiple models in addition to tools and subagents. This permits a new form of competition; instead of using a single AI company’s API to build applications, developers can put other companies’ models to work and become the API provider themselves.
Microsoft Strikes Out on Its Own
Microsoft, once OpenAI’s exclusive partner and still a major reseller of other companies’ AI models, built its own reasoning model from scratch.
What’s new: Microsoft introduced MAI-Thinking-1, its first reasoning language model that was not distilled or fine-tuned from a model built by a different developer. Microsoft describes MAI-Thinking-1 as a medium-sized model comparable to Claude Sonnet 4.6. It leads a family of seven MAI models unveiled at Microsoft’s Build conference, including MAI-Code-1-Flash, a small coding model available in GitHub Copilot and Visual Studio Code.
- Input/output: Text in (up to 256,000 tokens), text out (up to 256,000 tokens)
- Architecture: Mixture of experts (1 trillion parameters total, 35 billion parameters active per token)
- Features: Function calling, developer instructions (set by developers and ranked above user prompts in conflicts), compatible with OpenAI’s Chat Completions API
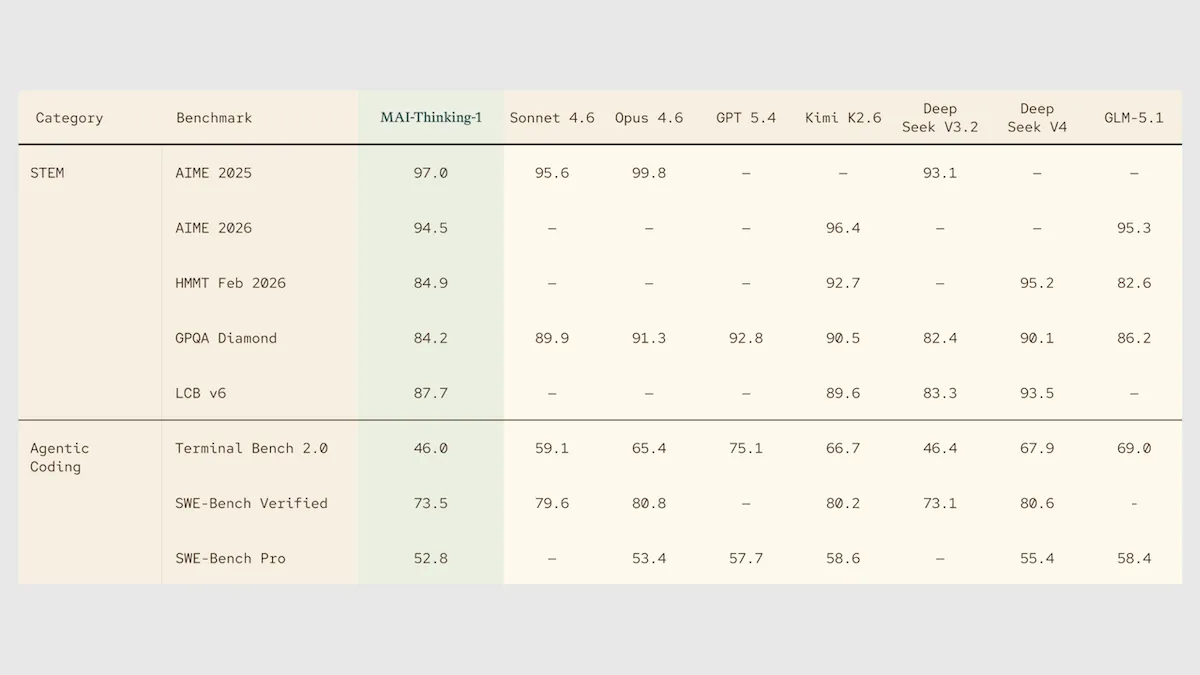
- Performance: According to Microsoft’s tests, third-place on the AIME 2025 math benchmark
- Availability: Private preview via Microsoft Foundry, broader access planned via Fireworks AI, Baseten, and OpenRouter
- Undisclosed: Full list of datasets and data providers, price
How it works: Microsoft built MAI-Thinking-1 by pretraining a base model, fine-tuning separate copies into specialized models to use as teachers, distilling them into a student model, and teaching the student to reason via reinforcement learning. The pretraining and midtraining data comprised 30 trillion and 3.55 trillion tokens respectively, including primarily human-generated data, including over 50 percent code. Post-training data included more than 5 million STEM questions and more than 160,000 coding questions.
- Microsoft pretrained primarily on licensed material, avoiding synthetic data. The company argues that a model trained on AI-generated data or via distillation of third-party teacher models inherits the teacher’s design choices and generalizes less easily, so training it directly yields more steerable behavior.
- For further training data, Microsoft crawled roughly 1.2 trillion webpages, filtered this set to 794 billion webpages, and separately drew in 24.2 billion deduplicated webpages from Common Crawl, an open archive whose own terms grant no rights to the content it stores and tell users they rely on it at their own risk.
- The team applied reinforcement learning on this base model to train three separate specialist models: one focused on STEM reasoning, another on agentic coding and tool use, and a third primarily devoted to helpfulness and safety. Rather than imitating reasoning traces of other models, the models generated original chains of thought and were rewarded for correct math solutions, passing code test cases, and sound judgement.
- The team consolidated the three specialists in two stages: (i) supervised fine-tuning that distilled them into a single model and (ii) a round of reinforcement learning to avoid over-refusals and improve safety and style.
Results: According to Microsoft's tests, MAI-Thinking-1 is strongest on mathematics and trails other models (including those from Anthropic, DeepSeek, and OpenAI) on graduate-level science and agentic coding. On AIME 2025, which tests the ability to solve competition math problems, MAI-Thinking-1 (97.0 percent) topped Claude Sonnet 4.6 (95.6 percent) and DeepSeek V3.2 (93.1 percent) but trailed Claude Opus 4.6 (99.8 percent). No independent evaluations or comparisons to more recent models have been published yet.
Behind the news: Microsoft has long relied on OpenAI’s models to power products such as Copilot and built earlier models of its own by drawing on those of its rivals. Its Phi family distilled OpenAI’s GPT-4 and GPT-5 models, and MAI-DS-R1 was a fine-tuned version of DeepSeek-R1. That changed in April 2026, when Microsoft and OpenAI amended their partnership, making Microsoft’s license to OpenAI’s models non-exclusive and freeing OpenAI to serve its products with any cloud provider.
Why it matters: Teams on the Microsoft stack can reach a capable reasoning model without adding a vendor or moving data out of the tools they already use. That may attract users among Microsoft’s large base of Azure and Copilot customers. Microsoft says it is planning more models based on the data pipeline created for MAI-Thinking-1 and its siblings.
We’re thinking: The company set out to train a reasoning model on fully attributable data but still drew heavily on the web. Of course everyone else does, too. Much of the success of large language models to date has been built on web data.
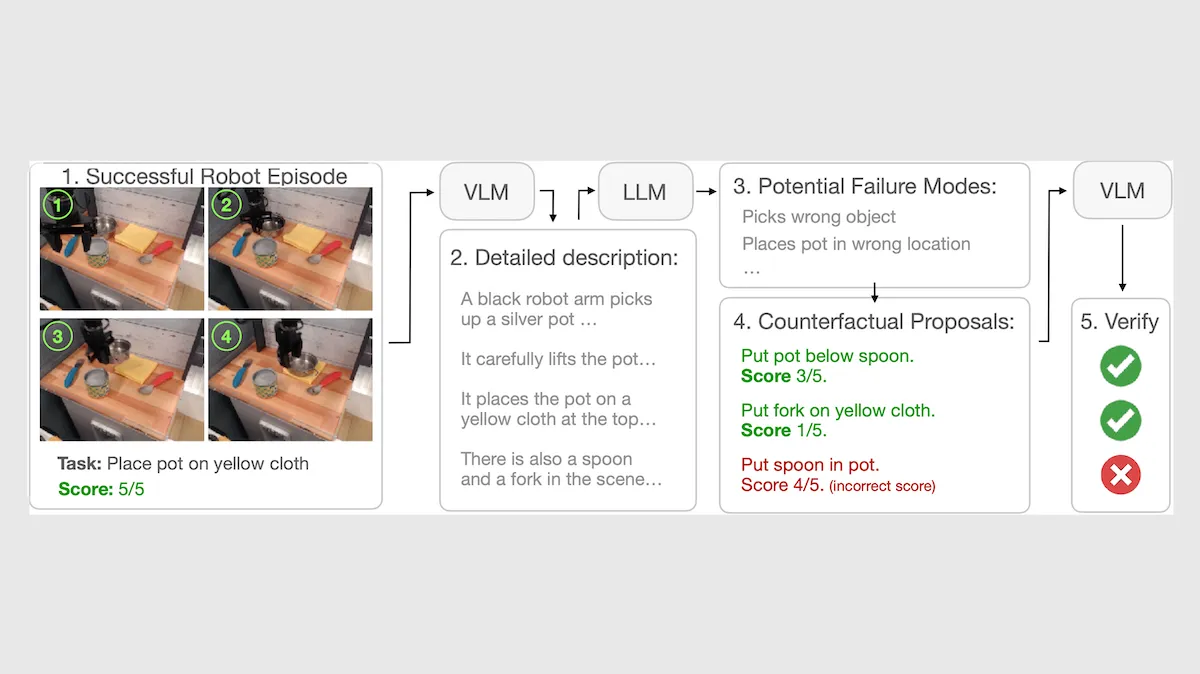
Better Reward Models for Robots
When you’re training a robot via reinforcement learning, a handcrafted reward function is labor-intensive to build but often dispenses rewards more effectively than a general-purpose reward model based on a vision-language model. Researchers built reward models that narrowed the gap.
What’s new: Tony Lee, Andrew Wagenmaker, Karl Pertsch, and colleagues at Stanford University and UC Berkeley built RoboReward, a family of vision-language reward models in 4 billion-parameter and 8 billion-parameter sizes. These models reward a variety of different tasks performed by a variety of robot types. The authors also provide a dataset and benchmark for training and evaluating vision-language reward models.
Key insight: Popular text-video datasets of robot actions mainly include examples of successful actions, which makes it hard for models to learn the difference between success and failure. But it’s possible to produce negative examples by relabeling positive examples (for example, given an example that includes a video of a robot putting a spoon in a pot, replace the command “put the spoon in the pot” with “put the spoon by the pot”). It’s also possible to produce incomplete attempts by trimming videos of successful actions.
How it works: The authors built a diverse robot-action dataset in which each example included a command, a video of a robot responding to the command, and a progress score from 1 (failed) to 5 (completed). They gathered videos from two datasets that depict single-arm, dual-arm, and humanoid robots. They standardized the task descriptions, augmented the data with negative examples, and assigned progress scores.
- To produce negative examples, the authors used GPT-5 mini, given a video that depicted a robot successfully executing a command, to describe (i) the scene, (ii) the robot’s actions, and (iii) the final state of the scene and robot. Given this analysis, Qwen3-4B-Instruct-2507 proposed alternative commands for which the video would merit a progress score less than 5. GPT-5 mini analyzed the alternative examples and discarded the ones with labels that didn’t match the corresponding videos.
- The authors truncated videos of successfully executed commands to create negative examples of partial progress.
- GPT-5 mini assigned each example a progress score from 1 to 4.
- The authors fine-tuned Qwen3-VL 4B and Qwen3-VL 8B, given a video and a command, to predict the progress score. The progress score served as a reward.
- They manually verified 2,831 examples to form a test dataset called RoboRewardBench.
Results: The RoboReward models estimated rewards for examples in RoboRewardBench more accurately than the robotics model Gemini Robotics-ER 1.5 and generalist models including GPT-5. In a real-world robot demonstration, training based on rewards from RoboReward models resulted in better performance than training via previous reward models, though not better than training via human-assigned rewards.
- Given a video and command from RoboRewardBench, the reward models calculated a reward, and the authors evaluated the results according to mean absolute error (lower is better). RoboReward 8B (0.665 mean absolute error) outperformed 21 other models including GPT-5 mini (0.691 mean absolute error), GPT-5 (0.811 mean absolute error), and Gemini Robotics-ER 1.5 (0.906 mean absolute error). RoboReward 4B (0.845 mean absolute error) achieved 4th place, outperforming 18 competitors including Gemini 3 Pro (0.851 mean absolute error).
- In the real-world demonstration, a diffusion transformer that was trained to manipulate a WidowX robot arm via rewards from RoboReward 8B outperformed one that was trained using rewards from Gemini Robotics-ER 1.5. Picking up a toy and placing it on a towel, the model trained on RoboReward 8B (50 percent) dramatically outperformed a model trained on Gemini Robotics-ER 1.5 (10 percent) but underperformed a human who manually assigned rewards (75 percent). Similarly, opening a drawer, the model trained on Roboreward 8B (80 percent) substantially outperformed the model that used Gemini Robotics-ER 1.5 (45 percent) but underperformed one that used human-assigned rewards (90 percent).
Why it matters: Vision-Language reward models have been promising in training robots, and this approach makes them much more effective. By augmenting successful demonstrations with validated failures, the authors trained a general‑purpose reward model that works across various types of robots and tasks, alleviating the need for task‑specific engineering.
We’re thinking: Releasing a benchmark and pretrained reward models invites the community to improve reward functions directly rather than hoping they emerge as a side-effect of better generalist models.