Fugu Blends Models Task by Task: Sakana debuted dedicated orchestrator models, Fugu and Fugu-Ultra, that spawn Claude, Gemini, and GPT agents
Models that orchestrate the activities of other models and agents achieved state-of-the-art performance on a variety of benchmarks, outperforming the best individual models working alone.
Models that orchestrate the activities of other models and agents achieved state-of-the-art performance on a variety of benchmarks, outperforming the best individual models working alone.
What’s new: The Tokyo-based research lab Sakana AI released two models that delegate tasks to other models and agents under a single API. Fugu is designed for discrete tasks like basic coding and chat, while Fugu-Ultra is designed for long-running tasks like extensive coding and research. The two systems deliver performance comparable to Claude Mythos 5 and GPT-5.6 Sol without being dependent on a particular model.
- Input/output: Text and images in, text out
- Features: Compatibility with OpenAI Codex, selection of underlying models, tool use, high and extra high reasoning levels
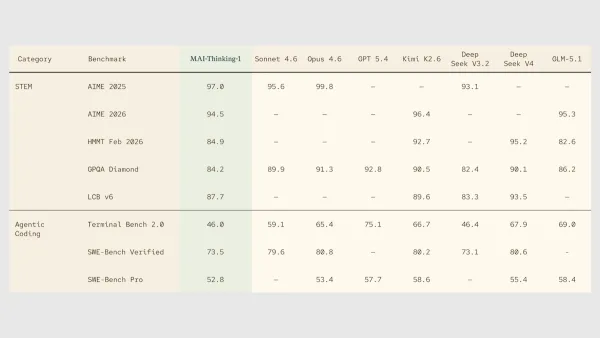
- Performance: Fugu and Fugu-Ultra outperformed Claude Fable 5, Claude Mythos Preview, and GPT-5.5 on Terminal Bench 2.1, GPQA-Diamond, and LiveCodeBench; Fugu-Ultra outperformed Claude Fable 5, Claude Mythos Preview, and GPT-5.5 on CharXiv Reasoning and CTI-Realm, and outperformed all available models on SWE-Bench Pro, Humanity’s Last Exam, and LiveCodeBench Pro
- Availability: Outside Europe via Sakana API, OpenRouter, Vercel, and other providers
- Price: Fugu is priced at the top underlying model’s standard rate; Fugu-Ultra including all submodels and agents $5/$30/$0.50 per 1 million input/output/cached tokens, double that for contexts over 272,000 tokens; subscriptions $20/$100/$200 per month for standard/pro/max plans (pro and max plans allow 10x and 30x standard usage respectively)
- Undisclosed: Orchestration recipes, datasets, architectures, and parameter counts
How it works: A technical paper describes Fugu and Fugu-Ultra as members of a model family trained to orchestrate agentic workers. Fugu emphasizes speed and Fugu-Ultra performance. The two models can call a wide range of LLMs including undisclosed open models, closed models from Anthropic, Google, and OpenAI including Claude Opus 4.8, Gemini 3.1 Pro, and GPT-5.5, and instances of Fugu or Fugu-Ultra themselves.
- When prompted, Fugu and Fugu-Ultra construct an agentic workflow that calls on a range of LLM workers. For a given input, Fugu decides which model to call at every step until it produces an output. In comparison, Fugu-Ultra divides the input into subtasks, designing an agentic workflow that ends with generation of the output. For each subtask, it prompts a model (potentially in parallel). It can also call itself, which enables it to further divide subtasks into more granular tasks.
- Sakana built the Fugu models by fine-tuning an undisclosed large language model to complete tasks in coding, mathematics, language understanding, multistep reasoning, and agentic tool use. The Fugu models used all worker models to complete each task multiple times, which had a verifiable output. The team scored each worker model’s outputs based on the percentage of times it successfully completed the task and trained the Fugu models to match the distribution of scores.
- After supervised fine-tuning, Sakana trained the Fugu models using sep-CMA-ES, an evolutionary algorithm, to choose a model for customized agentic tasks. (The authors note that different models vary in their abilities to complete different elements of a task.) Sakana trained the Fugu models to select models that completed the tasks successfully in a fixed number of steps under different agentic harnesses (like Claude Code, Codex, and OpenCode).
- Fugu-Ultra uses Conductor, a model that coordinates agentic systems, to break down tasks into subtasks and coordinate multiple agents to solve them. Conductor allows each agent to act independently, calling whatever tools it deems necessary within its own subtask, and to share memory with other agents so it can see what tools other agents have called.
- The team trained Fugu-Ultra using the reinforcement-learning algorithm GRPO on an undisclosed large language model to prompt a pool of LLMs to perform five-step agentic workflows (produced by Fugu-Ultra). They extended the workflows to steps of arbitrary length and defined success as producing solutions that matched a human solution.
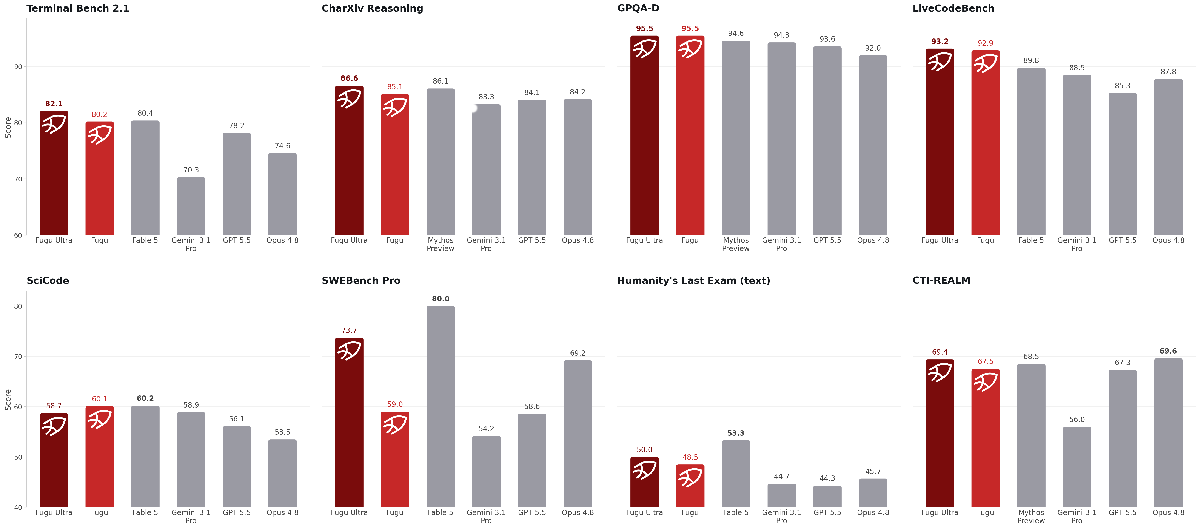
Performance: Fugu-Ultra achieved state-of-the-art performance in multiple tests of coding, reasoning, and scientific knowledge performed by Sakana. In other categories, it fell just behind models that aren’t currently commercially available including Claude Fable 5. Fugu and Fugu-Ultra also showed strong performance at long-context reasoning and recall.
- Fugu-Ultra set the state of the art on software engineering tasks in Terminal-Bench 2.1, LiveCodeBench, and LiveCodeBench Pro. It performed just behind Claude Fable 5 on SWE-Bench Pro.
- On GPQA-Diamond (a test of graduate-level scientific knowledge), Fugu and Fugu-Ultra both achieved 95.5, the highest percentage recorded.
- On SciCode (a test of coding to solve real-world scientific problems), Fugu achieved 60.1, the best of any available model, just behind Claude Fable 5 and ahead of Fugu-Ultra.
- Fugu set the state of the art on long context reasoning (AA-LCR). Fugu and Fugu-Ultra are behind only GPT-5.5 on MCRv2, a test of long-context recall.
Behind the news: Sakana previously pursued other routes to combine AI models and benefit from their collective intelligence, including model merging. However, agentic orchestration is its most successful approach yet. OpenRouter recently presented Fusion, showing that a combination of leading models can outperform models working alone and that a judicious blend of lower-priced models can attain near-SOTA performance, offering more bang for the buck.
Why it matters: The U.S. government’s recent moves to restrict access to Claude Fable 5 and GPT-5.6 has raised interest in models that orchestrate other models and agents, as developers and organizations seek to reduce their dependence on any one provider or nation. Even before Anthropic withdrew widespread access to Claude Fable 5, many organizations were displeased by the company’s new data retention requirements. If developers have full control of the providers in their orchestrator’s model pool, they can turn models on and off depending on the sensitivity of the information being handled, to reduce costs, or to serve any operational function.
We’re thinking: Model orchestration is in many ways the natural outgrowth of agentic engineering; it’s just operating at a higher level of abstraction, switching between multiple models in addition to tools and subagents. This permits a new form of competition; instead of using a single AI company’s API to build applications, developers can put other companies’ models to work and become the API provider themselves.