Claude Opus 4.8 advertises its uncertainty: Dynamic workflows manage Anthropic subagents
MiniMax M3, the new open-weights champ. Nvidia’s PC superchips. Cosmos 3, an all-modal world/action model. Nvidia’s latest robotics partnerships.

In today’s edition of Data Points, you’ll learn more about:
- MiniMax M3, the new open-weights champ
- Nvidia’s PC superchips
- Cosmos 3, an all-modal world/action model
- Nvidia’s latest robotics partnerships
But first:
An updated Opus, along with a preview of Claude Mythos
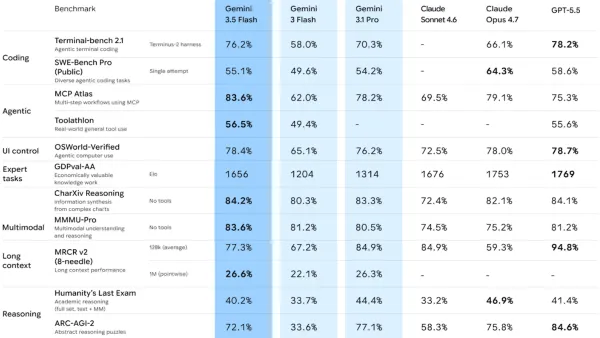
Anthropic released Claude Opus 4.8 at the same price as Opus 4.7, with improvements across coding, reasoning, and agentic tasks. The model shows notably better judgment and honesty: It flags uncertainties more reliably and is about four times less likely than Opus 4.7 to let code flaws pass without comment. Early testers across legal, finance, and engineering report it as more trustworthy for high-stakes work. Harvey, a legal AI platform, notes it's the first model to break 10 percent on their Legal Agent Benchmark’s all-pass standard. Alongside the model, Anthropic introduced dynamic workflows in Claude Code for codebase-scale migrations across hundreds of thousands of lines, an effort-control slider on claude.ai for trading speed against quality, and a 3x price cut on fast mode. The company also previewed Mythos-class models, sitting above Opus in capability, currently available to a small number of organizations for cybersecurity work, with broader release planned once cyber safeguards are in place. (Anthropic)
Mass-migrating agentic swarms come to Claude Code
Anthropic's dynamic workflows let Claude orchestrate tens to hundreds of parallel subagents to tackle large-scale engineering tasks in a single session. Claude dynamically plans subtasks, farms them out to independent agents running in parallel, and verifies results before surfacing them, compressing work that would take weeks into days. The feature is available now in research preview across Claude Code’s CLI, desktop app, VS Code extension, and API, on Max, Team, and Enterprise plans. Early users have applied it to codebase-wide bug hunts, security audits, framework migrations spanning thousands of files, and work requiring independent verification. One real tradeoff: dynamic workflows consume substantially more tokens than standard Claude Code sessions, so Anthropic recommends starting with scoped tasks to understand your usage patterns. (Anthropic)
MiniMax’s open M3 bests OpenAI and Google’s top models at coding
MiniMax released M3, an open-weight model combining frontier coding performance, a one-million-token context window, and native multimodal capabilities. The model uses MiniMax Sparse Attention, a new architecture that cuts per-token compute to about one-twentieth of the previous generation. On SWE-Bench Pro, M3 scores roughly 60 percent, putting it ahead of GPT-5.5 and Gemini 3.1 Pro. But MiniMax says the efficiency gains matter more than the score: its Sparse Attention delivers nearly ten times faster prefilling and over fifteen times faster decoding at full context length, keeping longer conversations and reasoning chains cheap to run. In internal tests, M3 ran unsupervised for nearly 12 hours to reproduce an ICLR 2025 Outstanding Paper on LLM fine-tuning learning dynamics, and spent 24 hours optimizing a CUDA kernel from roughly seven percent to seventy percent hardware utilization. M3 ships through MiniMax Code, a web IDE, API access with tiered pricing, and subscription token plans starting at 20 dollars monthly. It was trained with native multimodality from the start, supporting image and video input alongside interleaved text-image training data. (MiniMax)
Nvidia announces CPUs for data centers and CPU/GPUs for PCs
At its Taiwan event, Nvidia unveiled the RTX Spark superchip, a combined CPU/GPU processor designed to power AI-enabled Windows laptops and desktops from Microsoft, Dell, and others launching this fall. The chip lets PCs run AI agents locally: autonomous assistants that understand context, process files, and handle research tasks without cloud servers. Nvidia framed this as a fundamental shift from passive tools to intelligent agents that interact with users directly. The company is simultaneously expanding its Vera CPUs for data centers (early customers include Anthropic, OpenAI, and SpaceX) as part of a broader strategy to extend its dominance beyond data centers into consumer hardware. (Associated Press)
World model combines many modalities plus action and reasoning
Nvidia shipped Cosmos 3, a world foundation model that merges video generation, physical reasoning, and action prediction into a single architecture. Built on a Mixture-of-Transformers backbone, it processes text, images, video, audio, and robotic actions through one forward pass, handling everything from autonomous driving simulations to robot policy generation without switching models. The release includes two sizes: an 8-billion-parameter Nano model that runs on workstation GPUs like the RTX PRO 6000, and a 32-billion-parameter Super model for data centers. Nvidia also open-sourced post-training scripts and five synthetic datasets covering robotics, warehouse operations, and driving scenarios. The model integrates directly with Hugging Face Diffusers, so developers can drop it into existing pipelines with a few lines of code. (Hugging Face)
Nvidia updates GR00T robot design for Unitree partnership
Nvidia announced a collaboration with Chinese robotics maker Unitree to deliver a standardized humanoid robot for academic researchers, combining Unitree’s H2 body, Sharpa’s five-fingered hands, and Nvidia’s Jetson Thor chip. The Isaac GR00T reference design will be used by researchers at Stanford and UC San Diego, among others. Nvidia plans similar partnerships with robotics firms in the U.S., Europe, and South Korea, though executives declined to name partners. The arrangement includes secure boot and confidential computing, routing all software updates through Nvidia’s chip to verify code authenticity and prevent malicious execution, mirroring data-center protections. (Reuters)
Want to know more about what matters in AI right now?
Read the latest issue of The Batch for in-depth analysis of news and research.
Last week, Andrew discussed the emerging role of AI Forward Deployed Engineers (FDEs) in Silicon Valley, predicted greater demand for AI Engineers than for FDEs, and anticipated more specialization within AI engineering roles.
“The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalyse narrative of upcoming job market collapse is false). There will be many AI and non-AI jobs. However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.”
Read Andrew’s letter here.
Other top AI news and research covered in depth:
- Google's updated Flash, Gemini 3.5 Flash Pairs Smarts With Speed, approaches top models but raises prices.
- European Union regulators pause some AI Act provisions and delete others, affecting the timeline of AI regulations.
- A study shows that internet traffic driven by AI tripled last year, highlighting the growing influence of AI-generated content.
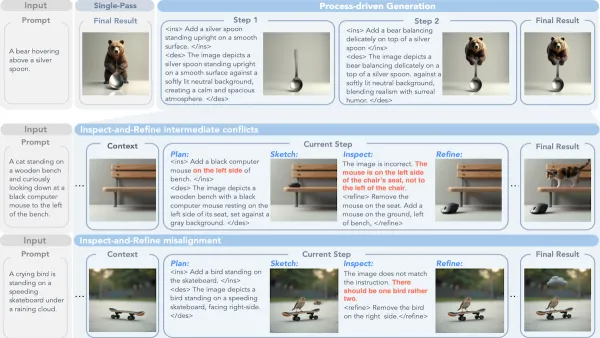
- Meta enhances image models by planning generated images in stages, improving quality through step-by-step plotting and revising.
A special offer for our community
In case you missed it, DeepLearning.AI launched our first-ever subscription plan for our entire course catalog! As a Pro Member, you’ll immediately enjoy access to:
- Nearly 200 AI short and long courses from Andrew Ng and industry experts
- Labs and quizzes to test your knowledge
- Projects to share with employers
- Certificates to testify to your new skills
- A community to help you advance at the speed of AI
Enroll now to lock in a year of full access for $25 per month paid upfront, or opt for month-to-month payments at just $30 per month. Both payment options begin with a one-week free trial. Explore Pro’s benefits and start building today!
Data Points is produced by human editors with AI assistance.