Claude Fable 5, or Mythos for the masses: Apple rethinks mixture-of-experts to save local memory
Google’s voice translation model covers 70+ languages. OpenAI’s preliminary public-offering paperwork. NotebookLM, now powered by Gemini 3.5 agents. FrontierCode, a new code-quality benchmark from Cognition.

In today’s edition of Data Points, you’ll learn about our top headlines, and more:
- Google’s voice translation model covers 70+ languages
- OpenAI’s preliminary public-offering paperwork
- NotebookLM, now powered by Gemini 3.5 agents
- FrontierCode, a new code-quality benchmark from Cognition
But first:
Anthropic debuts Claude Mythos 5 and a safer sibling model, Fable
Anthropic launched Claude Fable 5, which outperforms all previous publicly released Claude models on nearly all tested benchmarks, including software engineering, knowledge work, vision, and scientific research.. The model includes automatic guardrails that redirect certain high-risk queries to the less capable Claude Opus 4.8. For a limited group of cyberdefenders and infrastructure providers, Anthropic is releasing Claude Mythos 5, the same underlying model with safeguards removed, initially through Project Glasswing in collaboration with the US government. Both cost $10 per million input tokens and $50 per million output tokens. Stripe used Fable 5 to migrate 50 million lines of Ruby code in a single day, work that would have required two months of team effort. Anthropic’s internal testing found Mythos 5 accelerated drug design workflows tenfold and produced molecular biology hypotheses preferred over Opus-class outputs in 80 percent of blinded comparisons. (Anthropic)
Apple’s latest on-device and cloud AI models
Apple released five new foundation models across on-device and cloud tiers, the third generation of its Apple Foundation Models (AFM) lineup. On-device models include a 3B-parameter AFM 3 Core and a 20B-parameter AFM 3 Core Advanced, which uses a sparse architecture that activates only one to four billion parameters per request. The new architecture stores full weights in flash and loads them into DRAM on demand, permitting a larger model without ballooning runtime memory. For cloud workloads, Apple offers AFM 3 Cloud, an image-generation model called ADM 3 Cloud, and AFM 3 Cloud Pro, all built with Google and Nvidia. The Pro variant runs on Nvidia GPUs in Google Cloud while preserving Apple’s Private Cloud Compute privacy model, a constraint that required custom infrastructure work. In human evaluation, AFM 3 Cloud beat Apple’s 2025 baseline on 64.7 percent of text prompts; new text-to-speech voices powered by AFM 3 Core Advanced scored 4.15 out of five versus 3.87 for the current system. Apple trained all models on publicly available data, licensed datasets, and synthetic material, not user activity or personal data. (Apple)
Google updates its real-time translation model
Google released Gemini 3.5 Live Translate, an audio model that translates speech across 70 languages while preserving the speaker’s intonation, pacing, and pitch. Unlike turn-based systems that wait for pauses, it generates translated speech continuously, staying a few seconds behind the speaker. It’s rolling out via three channels: a public preview API for developers, a private preview in Google Meet for enterprise customers this month, and globally in the Google Translate mobile app. The Meet integration expands support from five languages to 70-plus, enabling over 2,000 language pair combinations in a single meeting and dropping the previous English-only bridge requirement. All model-generated audio includes SynthID watermarking. (Google)
OpenAI files for an IPO, but won’t commit to going public
OpenAI filed confidential SEC paperwork Monday, opening the door to a public offering, but the company stressed it hasn’t decided on timing and may stay private for now. The move follows Anthropic’s IPO disclosure and Elon Musk’s SpaceX pitching itself to investors as an AI company. CEO Sam Altman has long flagged a public offering as likely, given OpenAI’s $852 billion valuation and its capital demands. The company faces mounting pressure from Google and Anthropic even as it declines to disclose profitability or earnings. CFO Sarah Friar told AP in April that OpenAI already operates with “the good hygiene of a public company,” measuring revenue by SEC standards and positioning itself to tap public markets when ready. (Associated Press)
NotebookLM update can suggest its own sources
Google updated NotebookLM to run on Gemini 3.5 by default and added Antigravity-powered skills for research and content generation. The tool now suggests sources automatically during chat—pulling from Google Search and related material—letting users build knowledge bases without pre-loading documents. Users can specify output formatting and edit results afterward; supported formats include PDFs, Excel, PowerPoint, CSV, JSON, and data visualizations. Updates appear in chat as step-by-step reasoning so users can verify how NotebookLM reached its answers. The features roll out today to Google AI Ultra users and Workspace customers with AI Ultra or AI Expanded Access, with broader availability to follow. (TechCrunch)
FrontierCode benchmark challenges top AI models on code quality
Cognition launched FrontierCode, a benchmark measuring whether AI models write code maintainers would actually merge, not just code that runs. More than 20 open-source maintainers spent over 40 hours per task building it, grading submissions across six axes: correctness, test quality, scope discipline, style, regression safety, and codebase standards. Novel grading techniques include reverse-classical tests that verify agent-written tests catch real bugs, scope constraints that penalize unnecessary changes, and adaptive grading that accepts multiple valid solutions. Claude Opus 4.8 leads with 13.4 percent on the hardest subset and 34.3 percent on the main 100-task set. GPT-5.5 achieves 6.3 percent using four times fewer tokens. Cognition reports 81 percent fewer misclassification errors than SWE-Bench Pro—suggesting most existing code benchmarks let agents game scores without producing mergeable code. (Cognition)
Want to know more about what matters in AI right now?
Read the latest issue of The Batch for in-depth analysis of news and research.
Last week, Andrew discussed the White House’s new executive order on AI and the importance of steering away from overregulation while stopping legitimate cybersecurity risks.
“As AI continues to develop, I’m sure that new harmful ways to use it will arise alongside the far larger number of beneficial ways. Nations will be better off if their governments are able to demonstrate sound technical judgement and navigate that fine balance.”
Read Andrew’s letter here.
Other top AI news and research stories covered in depth:
- Alibaba’s latest proprietary model, Qwen3.7-Max, adds speed and power, challenging U.S. rivals in the AI race.
- WhaleSpotter pairs sensors with AI algorithms to detect marine mammals, showcasing how AI is saving whales.
- An investigation into the gray market for LLM access reveals how middlemen package extra tokens and hijack IDs to resell and distill models.
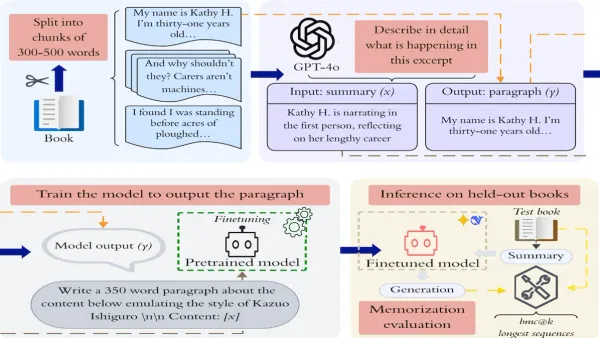
- Fine-tuning LLMs to expand on summaries can inadvertently strip models of copyright alignment guidelines, unearthing pretraining texts.
A special offer for our community
In case you missed it, DeepLearning.AI launched our first-ever subscription plan for our entire course catalog! As a Pro Member, you’ll immediately enjoy access to:
- Nearly 200 AI short and long courses from Andrew Ng and industry experts
- Labs and quizzes to test your knowledge
- Projects to share with employers
- Certificates to testify to your new skills
- A community to help you advance at the speed of AI
Enroll now to lock in a year of full access for $25 per month paid upfront, or opt for month-to-month payments at just $30 per month. Both payment options begin with a one-week free trial. Explore Pro’s benefits and start building today!
Data Points is produced by human editors with AI assistance.