GLM-4.5, an Open, Agentic Contender: Zhipu AI (Z.ai) releases open-weights GLM-4.5 models that perform comparably to the latest from Claude and DeepSeek
The race is on to develop large language models that can drive agentic interactions. Following the one-two punch of Moonshot’s Kimi K2 and Alibaba’s Qwen3-235B-A22B update, China’s Z.ai aims to one-up the competition.
The race is on to develop large language models that can drive agentic interactions. Following the one-two punch of Moonshot’s Kimi K2 and Alibaba’s Qwen3-235B-A22B update, China’s Z.ai aims to one-up the competition.
What’s new: GLM-4.5 is a family of open-weights models trained to excel at tool use and coding. The family includes GLM-4.5 and the smaller GLM-4.5-Air, both of which offer reasoning that can be switched on or off.
- Input/output: Text in (up to 128,000 tokens), text out (up to 96,000 tokens)
- Architecture: Mixture-of-experts (MoE) transformer. GLM-4.5: 355 billion parameters total, 32 billion active at any given time. GLM-4.5-Air: 106 billion parameters total, 12 billion active at any given time.
- Performance: Both models outperform Anthropic Claude 4 Opus, DeepSeek-R1-0528, Google Gemini 2.5 Pro, Grok 4, Kimi K2, and/or OpenAI o3 on at least one reasoning, coding, or agentic benchmark
- Availability: Web interface (free), API (GLM-4.5: $0.60/$0.11/$2.20 per million input/cached/output tokens; GLM-4.5-Air: $0.20/$0.03/$1.10), weights available via HuggingFace and ModelScope for commercial and noncommercial uses under MIT license
- Features: Function calling, switchable reasoning/non-reasoning
- Undisclosed: Specific training datasets
How it works: GLM-4.5 models include several architectural features that differ from other recent MoE models. Instead of adding more experts or making the experts use more parameters per layer (which would make the models wider), the team increased the number of layers per expert (which makes them deeper). The pretraining/fine-tuning process distilled three models into one.
- The team pre-trained the models on 22 trillion tokens: 15 trillion tokens of text followed by 7 trillion tokens of further text devoted to code and reasoning.
- They fine-tuned three copies of the pretrained GLM-4.5 using supervised fine-tuning and reinforcement learning, producing specialized versions for reasoning, agentic capabilities, and general knowledge. Then they fine-tuned the pretrained model to match the outputs from the specialized versions, producing one model with the capabilities of all three. Finally, they fine-tuned this model via reinforcement learning on further reasoning, agentic, and general data.
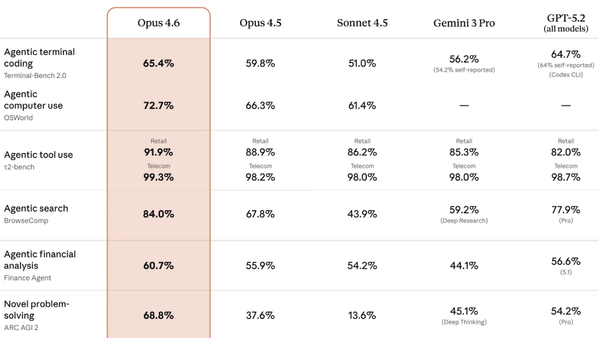
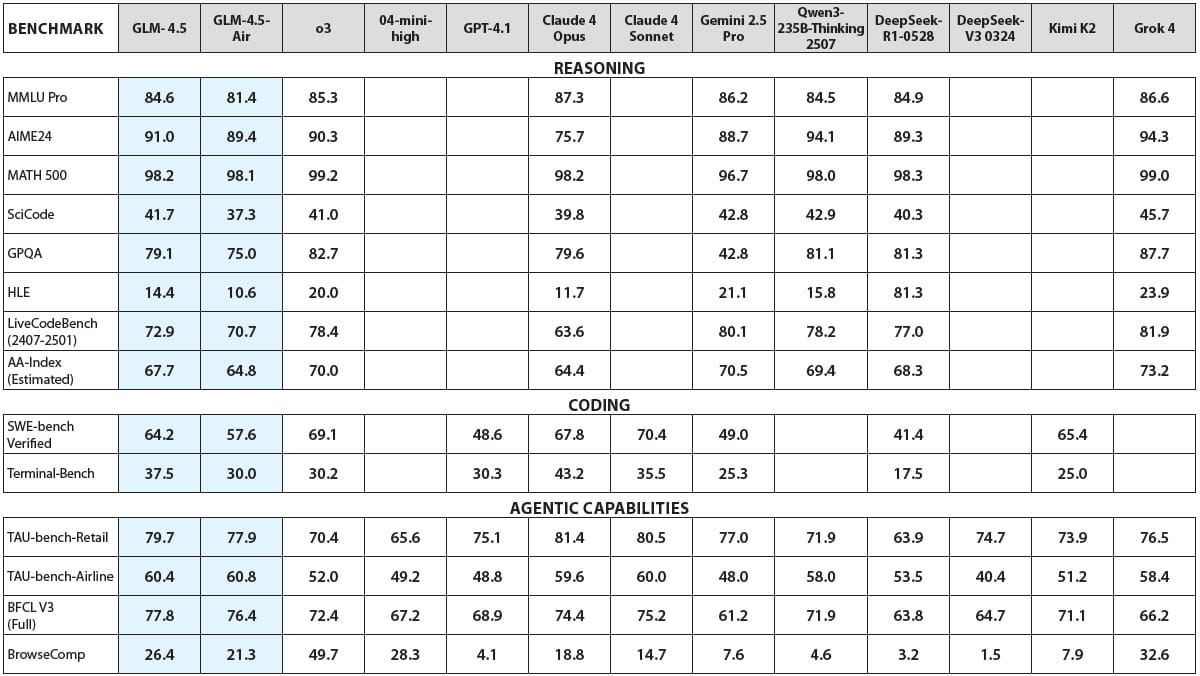
Results: The team compared GLM-4.5 and GLM-4.5-Air to top open and closed models across 12 benchmarks that assess reasoning, coding, and tool use.
- In an average of tool-use benchmarks (τ-Bench, BFCL v3 Full, ad BrowseComp), GLM-4.5 (90.6 percent accuracy) outperformed Claude Sonnet 4 (89.5 percent accuracy), Kimi K2 (86.2 percent accuracy), and Qwen3-Coder (77.1 percent accuracy). On BrowseComp (web browsing with multi-step searches), GLM-4.5 (26.4 percent accuracy) outperformed Claude 4 Opus (18.8 percent accuracy) but trailed o3 (49.7 percent accuracy).
- On MATH 500 (selected competition-level problems),GLM-4.5 (98.2 percent accuracy) equalled Claude 4 Opus. On AIME24 (competition math), GLM-4.5 (91.0 percent accuracy) outperformed Claude Opus 4 (75.7 percent accuracy) but trailed Qwen3-235B-Thinking (94.1 percent accuracy).
- On SWE-bench Verified (software engineering problems), GLM-4.5 (64.2 percent) outperformed Kimi K2 (65.4 percent) but trailed Claude 4 Sonnet (70.4 percent) and Qwen3-Coder (67 percent, tested separately). In Z.ai’s own evaluation across 52 coding tasks, GLM-4.5 achieved an 80.8 percent win rate against Qwen3-Coder and a 53.9 percent win rate against Kimi K2.
- GLM-4.5-Air excelled against likely larger models on multiple benchmarks, For instance, on BFCL v3, GLM-4.5-Air (76.4 percent) outperformed Gemini Pro 2.5 (61.2 percent). On AIME 2024, GLM-4.5-Air (89.4 percent) outperformed Claude 4 Opus (75.7 percent).
Behind the news: A rapid run of releases by teams in China — Kimi K2, Qwen3’s updates, and now GLM-4.5 — has established momentum in open-weights, large language models that are tuned for agentic behavior.
Why it matters: It’s not uncommon to distill larger models into smaller ones, sometimes to shrink the parameter count, sometimes to improve an existing small model’s performance. Z.ai’s approach distilled not a larger model but three specialized variations on the base model.
We’re thinking: The “best” open model for agentic applications is shifting weekly, creating both exciting opportunities and daunting challenges for developers.