Claude Mythos Preview Raises Security Worries: Why Claude’s advanced Mythos Preview model will be limited-release-only
Anthropic took unusual steps to prepare the world for a forthcoming large language model that it said poses extraordinary risks to cybersecurity.
Anthropic took unusual steps to prepare the world for a forthcoming large language model that it said poses extraordinary risks to cybersecurity.
What’s new: Claude Mythos Preview, which is not generally available, broadly outperforms the two-month-old Claude Opus 4.6, but it’s “strikingly capable” of identifying and exploiting vulnerabilities in existing code, Anthropic said. The company detailed its capabilities in a model card that fills 244 pages — the first time it has published a model card without making the model itself available commercially. Anthropic did not announce plans for a commercial release.
Precautions: To harden existing code against such capabilities, the company assembled a consortium called Project Glasswing that includes Amazon Web Services, Apple, CrowdStrike, Google, JPMorganChase, Linux Foundation, Microsoft, and Nvidia along with more than 40 other organizations. Anthropic is funding exclusive access for Glasswing members ($100 million worth of credits at $25/$125 per million input/output tokens) as well as $4 million in donations to organizations that are devoted to maintaining open source projects, so these organizations can discover and patch vulnerabilities in code they control before the model, or another one like it, becomes widely available. Anthropic promised to share what Glasswing does and learns.
Security risks: Anthropic didn’t train Claude Mythos Preview on security-related tasks. The model’s skills arose from training in coding, reasoning, and autonomous behavior.
- In tests over the past month, Claude Mythos Preview autonomously discovered “thousands” of “high-severity” vulnerabilities in popular operating systems, web browsers, and other code. 99 percent of them remain to be addressed. (Anthropic has not yet reported how many have been validated.)
- A flaw in the OpenBSD operating system made it possible to crash any OpenBSD host that responds over TCP, potentially shutting down corporate, government, and internet servers. It had gone undiscovered for 27 years before the model found it (among other OpenBSD vulnerabilities). It is now patched.
- Claude Mythos Preview also discovered a chain of bugs in the Linux kernel that enabled it to achieve root access and take control of the system. This, too, has been patched.
- Anthropic is concerned that bad actors will use next-generation models to attack software that controls critical systems of banking, medical care, logistics, energy, and transportation, posing serious risks to the individuals, the economy, and national defense. It envisions coordination among AI developers, software companies, security researchers, open source maintainers, and governments to discover and patch potential problems before users of next-generation models find them.
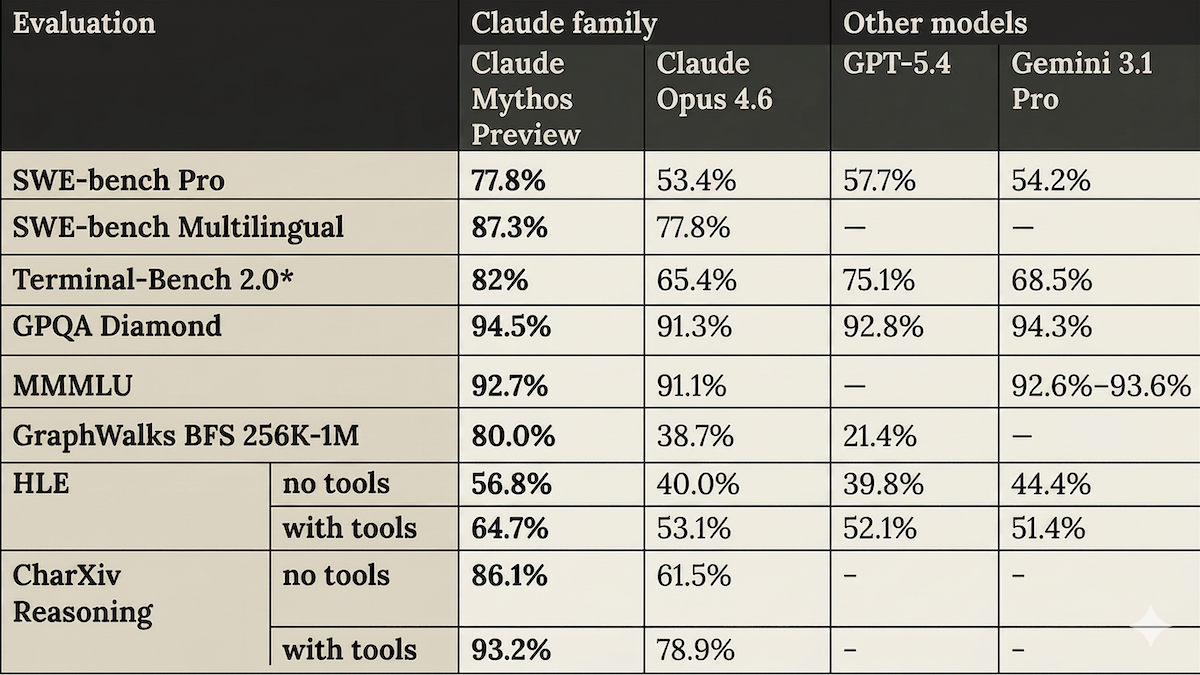
Performance: Claude Mythos Preview’s reported performance is impressive. In tests conducted by Anthropic, it substantially outperformed Claude Opus 4.6, OpenAI GPT-5.4, and Google Gemini 3.1 Pro on several popular benchmarks. The model card details the team’s efforts to minimize the impact of contamination of the model’s training data with benchmark test sets.
- Running CyberGym, a cybersecurity benchmark designed to assess the ability of AI agents to exploit real-world software vulnerabilities, Claude Mythos Preview (83.1 percent) outperformed Opus 4.6 (66.6 percent).
- On Terminal-Bench 2.0 (multi-step agentic coding tasks), Claude Mythos Preview (82 percent) exceeded next-best GPT-5.4 (75.1 percent).
- On GPQA Diamond (answering graduate-level science questions), Claude Mythos Preview (94.5 percent) edged out next-best Gemini 3.1 Pro (94.3 percent).
- On HLE (answering expert-level multidisciplinary questions designed to test reasoning), with access to tools, Claude Mythos Preview (64.7 percent) outdistanced next-best Claude Opus 4.6 (53.1 percent).
- On the GraphWalks test of long-context search between 256,000 tokens and 1 million tokens, Claude Mythos Preview (80 percent) vastly outperformed next-best Claude Opus 4.6 (38.7 percent). Anthropic didn’t publish results for Gemini Pro 3.1.
Yes, but: Anthropic’s way of introducing Claude Mythos Preview — promoting safety worries while withholding access from all but a small number of selected parties — comes right out of OpenAI’s early playbook. In 2019, that company promoted GPT-2’s ability to generate plausible text while keeping the model under wraps, citing the danger of its ability to produce disinformation and spam. Of course, the world greeted GPT-3 and subsequent iterations with unprecedented enthusiasm, and society has adjusted to the foibles and limitations of subsequent large language models. Anthropic’s caution may be justified but, like OpenAI’s product-release strategy, it has elements of a publicity stunt.
Why it matters: As large language models become more capable of coding, they also become more capable of finding bugs and exploiting them. Anthropic says the forthcoming Claude Mythos Preview does this dramatically better than its predecessors, posing risks to critical software that keeps society running. As long as the model outperforms top competitors, the company has little to lose — and potentially much to gain (say, avoiding damage to its brand after making the world less secure, if nothing else) — by creating a buzz while it prepares to deploy the model for commercial use.
We’re thinking: In the long term, as coding agents become more capable, defenders will gain the upper hand, as easy identification of vulnerabilities results in more-secure systems. But navigating this transition will be tricky, since advanced attackers may use tools that defenders have not yet gotten around to using.