U.S. to Evaluate Upcoming Models: U.S. Government Will Test AI Models for National Security Risks, Other Hazards Prior to Release
The U.S. government said it will evaluate cutting-edge models before they’re available to the public, a sharp reversal of the White House’s earlier hands-off policy.
The U.S. government said it will evaluate cutting-edge models before they’re available to the public, a sharp reversal of the White House’s earlier hands-off policy.
What’s new: The National Institute of Standards and Technology (NIST), an office of the U.S. Department of Commerce, announced that a new multi-agency task force will assess national-security risks posed by AI models prior to their deployment. Leading U.S. AI companies agreed to submit models for evaluation prior to release. In addition, the White House is considering an executive order that would require AI models to gain approval before they can be deployed.
How it works: NIST said the tests will focus on demonstrable risks to cybersecurity, biosecurity, and chemical weapons. The administration did not disclose details of its agreements with AI companies or any controls it expects to impose on models in light of test results.
- Models will be evaluated by Testing Risks of AI for National Security (TRAINS), a group overseen by the Center for AI Standards and Innovation (CAISI), a division of NIST. TRAINS differs from other NIST groups that have been disclosed insofar as it is designed for rapid response and draws on multiple federal agencies, including the Departments of Commerce, Defense, Energy, and Homeland Security; the National Security Administration and the National Institutes of Health.
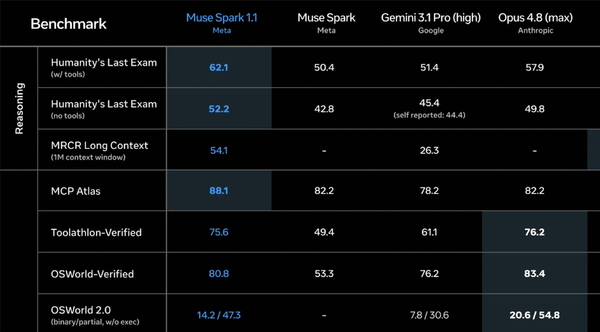
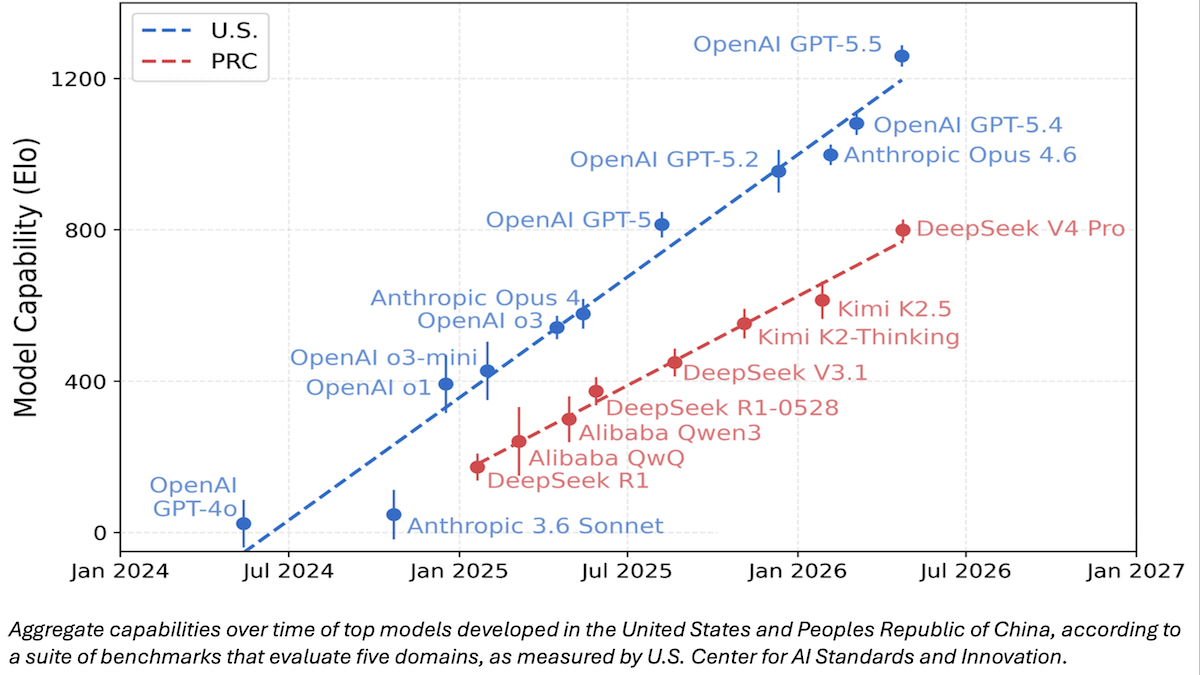
- TRAINS has not disclosed the benchmarks it intends to use. However, NIST has shared CAISI’s earlier comparison of DeepSeek V4 Pro with other large language models. CAISI ranked model capabilities according to an aggregate of nine widely used public benchmarks that span cybersecurity, coding, mathematics, natural sciences, and abstract reasoning plus an internal test called PortBench (porting command-line interface tools between different programming languages).
- Google, Microsoft, and xAI agreed to provide models that have limited or absent guardrails, and Anthropic and OpenAI had agreed to similar terms in 2024. The agreements will enable collaborative private-public research into evaluations of capabilities and risks, as well as mitigation of risks.
Behind the news: The abrupt policy change marks a major departure from the Trump Administration’s focus on removing Biden-era regulatory barriers to AI innovation. It comes roughly one month after Anthropic attracted the government’s attention by announcing that its Claude Mythos Preview model, which is not yet widely available, could exploit vulnerabilities in widely used software.
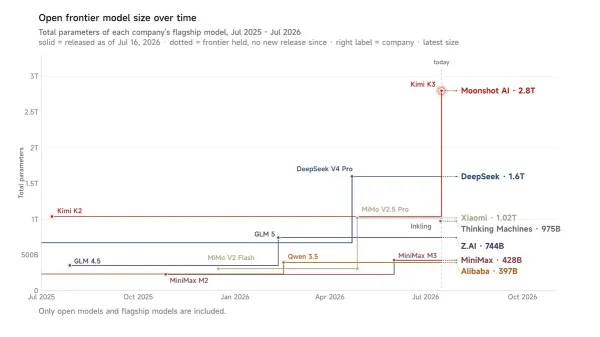
- Immediately after taking office in January 2025, President Trump assigned three key advisors to craft an AI Action Plan that would “sustain and enhance America’s global AI dominance” by suspending or eliminating regulatory policies created by President Biden. In 2023, the Biden Administration had issued an executive order that required developers to notify the government when they train a model whose processing requirements corresponded roughly to 1 trillion parameters.
- In March 2026, Anthropic tried to limit military use of Claude for surveillance and autonomous weapons. The White House rejected any limitations and banned the model from military use entirely.
- The following month, Anthropic announced that Claude Mythos Preview could autonomously exploit vulnerabilities in major operating systems and applications. The company had shared Mythos with 50 organizations that are using it to detect and patch their software.
- Last week, the White House said it opposes the company’s plan to expand the preview to another 70 organizations, citing concerns about national security and whether Anthropic has access to sufficient computational power to serve both existing Mythos users and the government. The company has not stated whether it intends to challenge the administration’s authority to limit the distribution of the preview model.
Why it matters: The White House’s shift from laissez-faire to pre-release scrutiny of AI models reflects a dawning reality that AI models have become powerful enough to pose immediate risks to national security. Requiring AI developers to test advanced models prior to public availability could give the government advance warning of potential issues and motivate AI developers to manage them proactively. It would also enable the government to decide which models are fit for wider distribution, and which must be withheld or altered (for reasons that may not be transparent). AI companies aren’t yet required to submit new models for government testing, and those who have agreed to do so have agreed voluntarily. However, officials are considering an executive order that would make such testing mandatory.
We’re thinking: A standardized battery of benchmark tests, applied comprehensively and according to consistent procedures, would be beneficial to the AI industry, but we think the right way to come up with these tests would be via the free market, rather than be imposed by government. Further, requiring government tests ahead of release would slow down U.S. developers, putting them at a competitive disadvantage relative to their peers in other countries, and potentially help them thwart open-source competitors through regulatory capture.