LoRA Adapters On Tap: Text-to-LoRA generates task-specific LoRA adapters directly from natural language descriptions
The approach known as LoRA streamlines fine-tuning by training a small adapter that modifies a pretrained model’s weights at inference. Researchers built a model that generates such adapters directly.
The approach known as LoRA streamlines fine-tuning by training a small adapter that modifies a pretrained model’s weights at inference. Researchers built a model that generates such adapters directly.
What’s new: Rujikorn Charakorn and colleagues at the Tokyo-based startup Sakana AI introduced Text-to-LoRA, a model that produces task-specific LoRA adapters based on natural language descriptions of tasks to be performed by a separate large language model.
Key insight: Typically, a LoRA adapter is trained for a particular task. However, a model can learn, given a description of a task, to generate a suitable adapter for tasks it may not have encountered in its training.
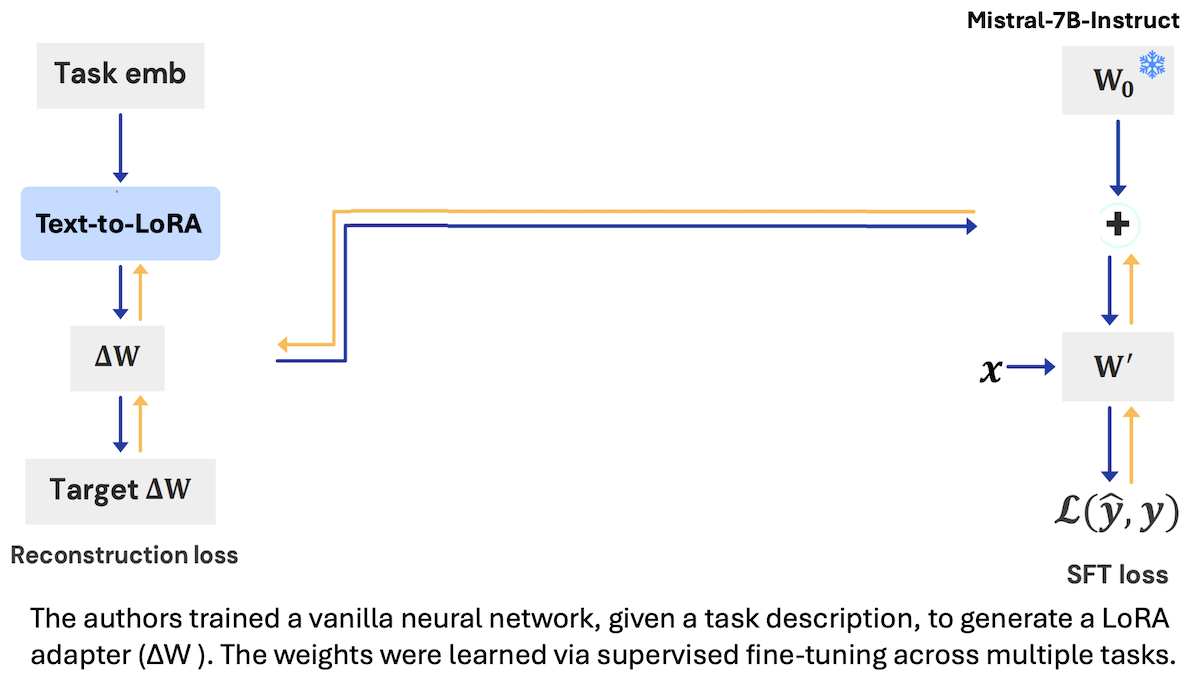
How it works: The authors trained a vanilla neural network, given text that describes a task, to produce a task-specific LoRA adapter for the large language model Mistral-7B-Instruct.
- The authors trained the network on 479 tasks such as answering questions about physics and solving math word problems. Each task consisted of 128 example input-output pairs and a description like this one for solving math word problems: “This task challenges your problem-solving abilities through mathematical reasoning. You must carefully read each scenario and systematically work through the data to compute the final outcome.”
- They generated embeddings of task descriptions by passing them to gte-large-en-v1.5, a pretrained embedding model.
- Given an embedding of a task description and embeddings that specified layers of Mistral-7B-Instruct to adapt, Text-to-LoRA learned to generate a LoRA adapter. Specifically, it learned to minimize the difference between the outputs of the LoRA-adapted Mistral-7B-Instruct and the ground truth outputs.
Results: The authors evaluated Mistral-7B-Instruct with Text-to-LoRA on 10 reasoning benchmarks (such as BoolQ, Hellaswag, and WinoGrande). They compared the results to Mistral-7B-Instruct (i) with conventional task-specific adapters, (ii) with a single adapter trained on all 479 training tasks simultaneously, (iii) unadapted but with the task description prepended to the prompt, and (iv) unadapted but with a plain prompt.
- Across all benchmarks, Mistral-7B-Instruct with Text-to-LoRA achieved 67.7 percent average accuracy. The LLM with the multi-task adapter achieved 66.3 percent. The unadapted LLM with the task description prepended to the prompt achieved 60.6 percent average accuracy, while a plain prompt yielded 55.8 percent.
- Comparing their work against conventional LoRA adapters, the authors reported results on 8 tasks (excluding GSM8K and HumanEval). Mistral-7B-Instruct with conventional adapters did best (75.8 percent). The LLM with Text-to-LoRA achieved 73.9 percent average accuracy, with the 479-task adapter 71.9 percent, and with no adapter 60.0 percent.
Why it matters: The demands placed on a model often change over time, and training new LoRA adapters to match is cumbersome. In effect, Text-to-LoRA compresses a library of LoRA adapters into a parameter-efficient hypernetwork that generalizes to arbitrary tasks. Because it generates them based on text descriptions, different descriptive phrasing can produce different styles of adaptation to emphasize, say, reasoning, format, or other constraints. In this way, Text-to-LoRA makes it easy, quick, and inexpensive to produce new adapters for idiosyncratic or shifting tasks.
We’re thinking: Training LoRA adaptors typically involves a tradeoff between specialization and generalization, and ensembles or mixtures of adapters can improve generalization. This approach offers an efficient, low-cost way to produce LoRA ensembles, which typically are expensive to train and maintain.