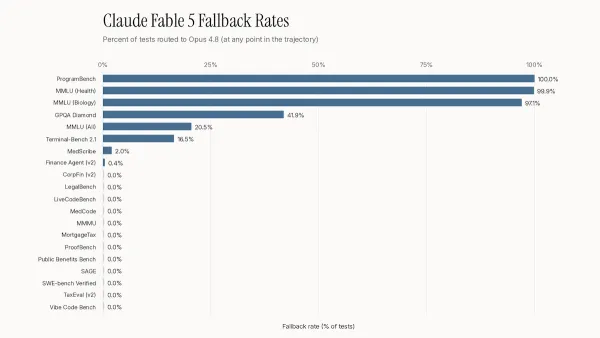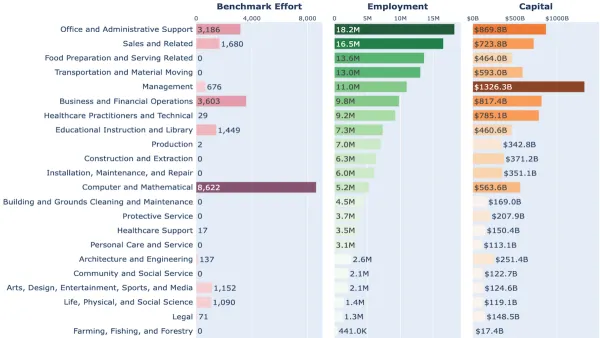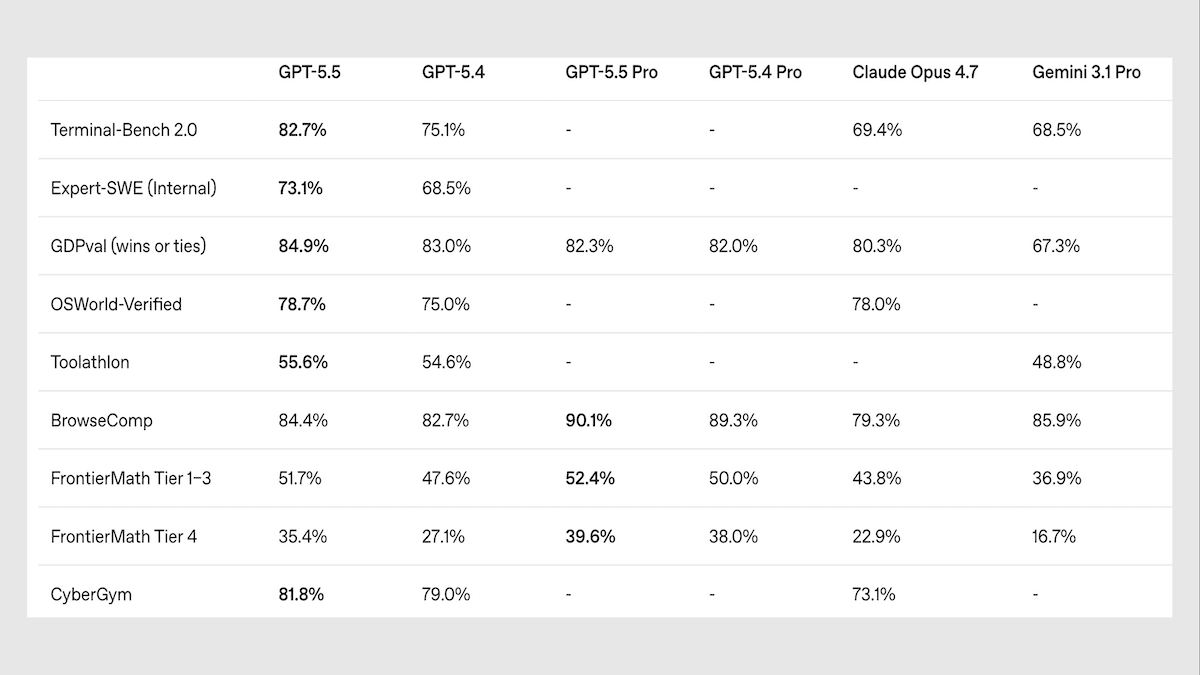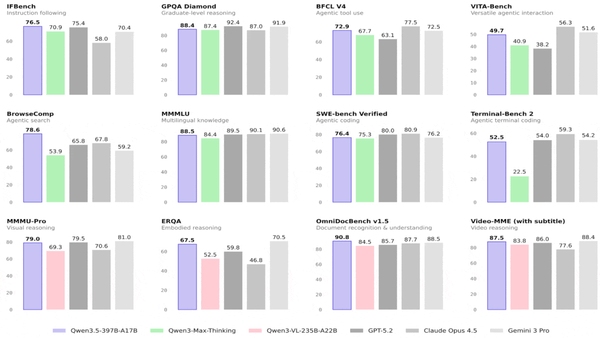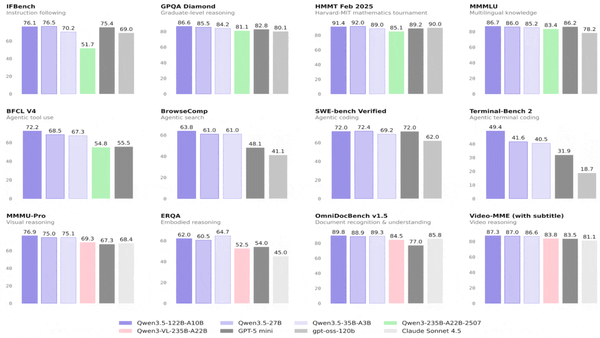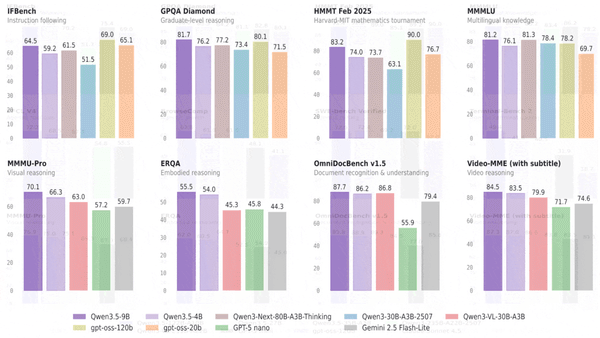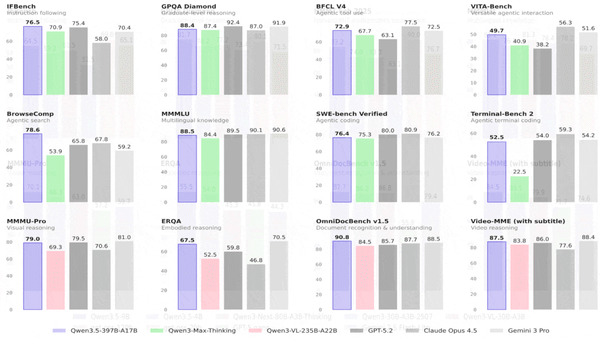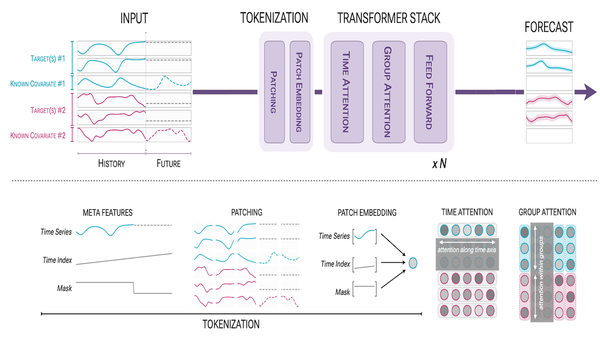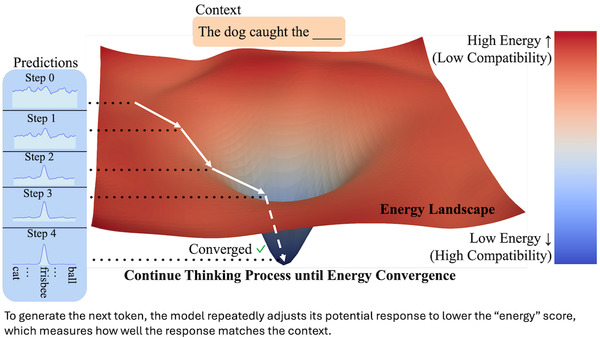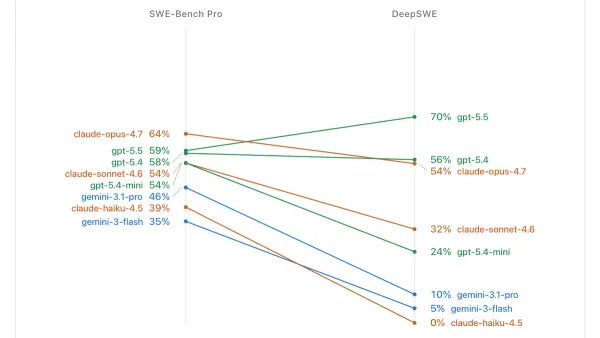
Machine Learning Research
Agentic Tests Beyond the Bug Hunt: DeepSWE, ProgramBench, and ITBench-AA push agents harder than SWE-bench
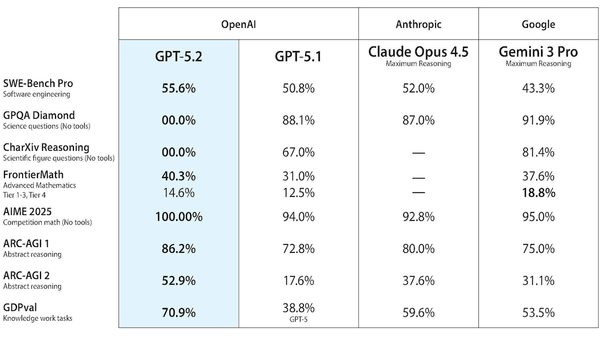
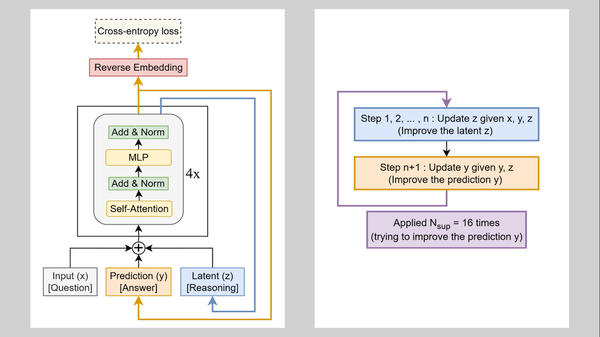
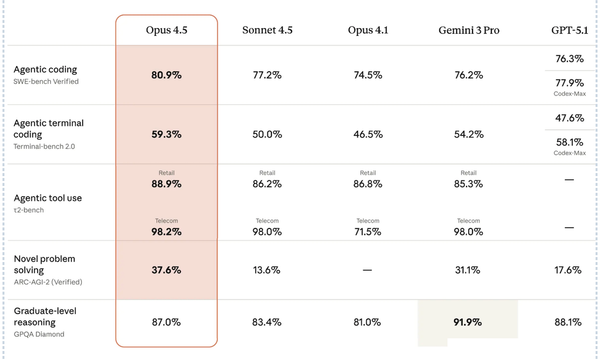
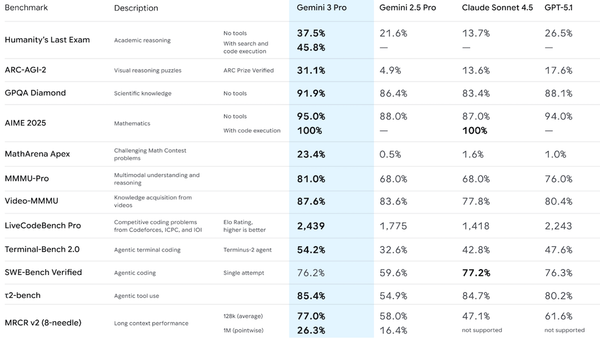
SWE-bench, a family of benchmarks that focuses on an LLM’s ability to fix software bugs, is giving way to new tests that evaluate agent software-engineering performance in more challenging ways.