
More-Efficient Agentic Search: Researchers fine-tune models to search their own parameters to boost recall
Large language models may have learned knowledge that’s relevant to a given prompt, but they don’t always recall it consistently. Fine-tuning a model to search its parameters as though it were searching the web can help it find knowledge in its own weights.
Large language models may have learned knowledge that’s relevant to a given prompt, but they don’t always recall it consistently. Fine-tuning a model to search its parameters as though it were searching the web can help it find knowledge in its own weights.
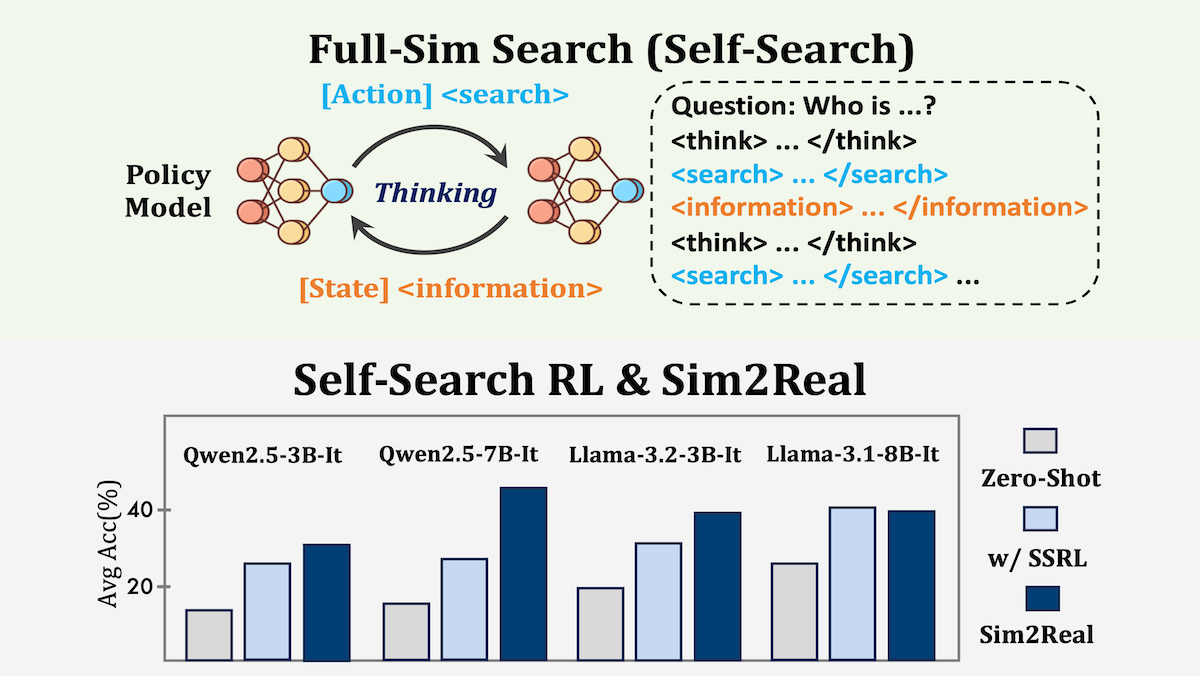
What’s new: Yuchen Fan and colleagues at Tsinghua University, Shanghai Jiao Tong University, Shanghai AI Laboratory, University College London, China State Construction Engineering Corporation Third Bureau, and WeChat AI introduced Self-Search Reinforcement Learning (SSRL). SSRL trains a large language model (LLM) to answer questions by simulating the search process, from generating a query to providing the answer. In the authors’ tests, it improved the performance of models with and without access to web-search tools.
Key insight: The authors found that an LLM is more likely to return a correct answer among 1,000 responses than it does in smaller numbers of responses. This shows that LLMs don’t always respond with knowledge they have. Simulating search — by asking a model to generate a query followed by a response to the query, as though it were searching the web — during fine-tuning via reinforcement learning can refine the model’s ability to retrieve information from its weights.
How it works: The authors used the reinforcement learning algorithm Group Relative Policy Optimization (GRPO) to fine-tune Llama-3.1-8B, Qwen2.5-7B, and other pretrained models to answer questions in the Natural Questions and HotpotQA datasets by following a sequence of actions that included reasoning and simulated searches. The models learned to produce a sequence of thoughts, queries, and self-generated information, cycling through the sequence multiple times if necessary, before arriving at a final answer.
- The model generated text following a specific format, using
<think>, <search>, <information> (self-generated search responses), and <answer> tags to structure its reasoning process. - The authors rewarded the model for producing final answers correctly and for following the designated format.
- The system ignored the tokens between the <information> tags for the loss calculation. This encouraged the model to focus on the query and the reasoning process rather than memorize any erroneous information it generated.
Results: The team evaluated SSRL on 6 question-answering benchmarks (Natural Questions, HotpotQA, and four others) and compared it to methods that use external search engines. Models trained via SSRL tended to outperform baselines that rely on search. The skills learned via SSRL also improved the model’s performance when it was equipped to call an external search engine.
- Across the benchmarks, a Llama-3.1-8B model trained using SSRL exactly matched the correct answer 43.1 percent of the time on average. ZeroSearch, a model that uses a separate, fine-tuned Qwen-2.5-14B-Instruct to answer queries during training and Google to answer queries during testing, exactly matched the correct answer 41.5 percent of the time, and Search-R1, a model that’s trained to use Google search, exactly matched the right answer 40.4 percent of the time.
- Of four models trained with SSRL, three showed improved performance using Google Search instead of self-generating responses. For instance, a Qwen2.5-7B model’s performance improved from an average of 30.2 percent with SSRL to 46.8 percent with SSRL and Google search.
Why it matters: The gap between training in a simulation and performance in the real world can be a challenge for AI agents based on LLMs. In this case, LLMs that were trained to simulate web searches were able to perform actual web searches more effectively. This result demonstrates that, for knowledge-based tasks, an LLM’s own parameters can serve as a cost-effective, high-fidelity simulator.
We’re thinking: Agents can be more judicious with respect to when they need to search the web. This work suggests a hybrid approach, in which an agent first consults its internal knowledge and searches the web only when it detects a gap.



