Planning Generated Images In Stages: Meta improves image models by plotting and revising generations step-by-step
Text-to-image generators that use diffusion or flow-matching typically compose a whole image at once (although they refine the whole image in steps).
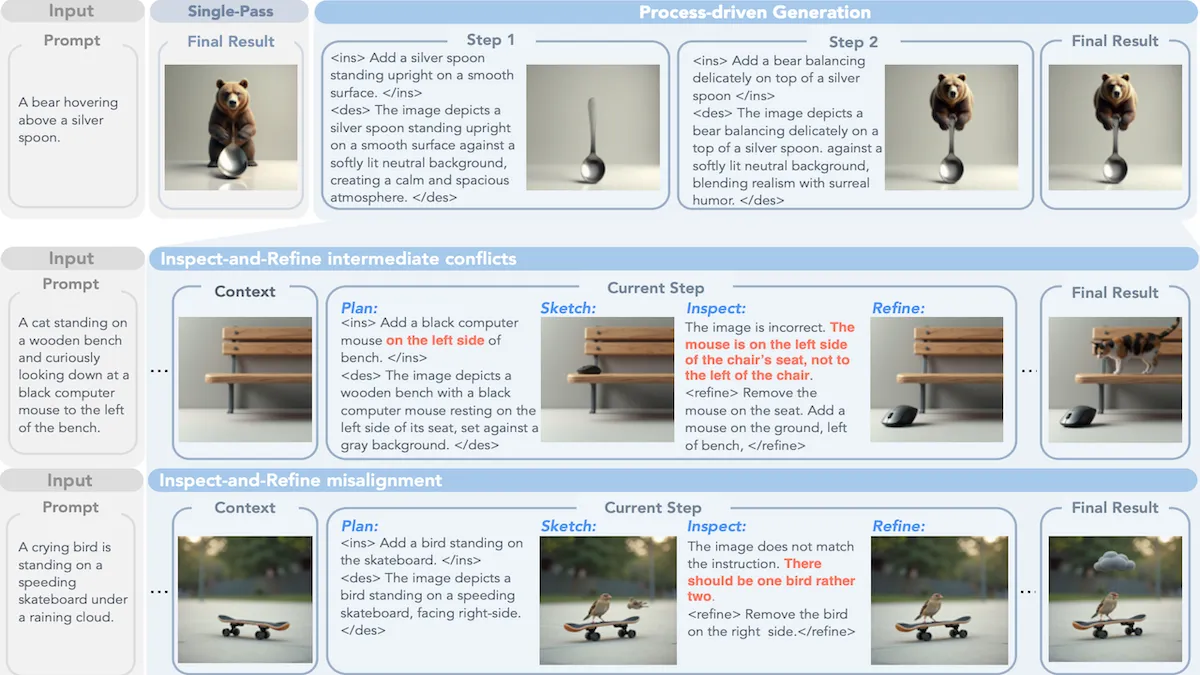
Text-to-image generators that use diffusion or flow-matching typically compose a whole image at once (although they refine the whole image in steps). Researchers got better results by breaking image composition into discrete stages, then checking and revising interim results.
What’s new: Lei Zhang and colleagues at Meta, University of California San Diego, Worcester Polytechnic Institute, and Northwestern University proposed a fine-tuning method for image generators that trains a model to compose images by planning, generating an element, checking whether it matches the prompt, correcting if necessary, generating another element, and so on.
Key insight: Text-to-image models often fail to represent spatial relationships (such as whether one element is above, below, in front of, or behind another) and object attributes (such as numbers of fingers, arms, or legs). The generation process becomes easier to control when the model learns to complete the image by looping through a staged process. Given a prompt like “a bear hovering above a silver spoon”, the stages can be:
- Plan. Write an instruction for the next change to be made (iteration 1: “draw a bear”; iteration 2 “add a spoon under a bear”; and so on) and a description of the image after the change.
- Sketch. Generate an updated version of the image so far (iteration 1: an image of a bear; iteration 2: the bear and a spoon).
- Inspect. Check the instruction and the description against the prompt, and check the image against the instruction.
- Refine. Issue a command to correct it if needed (iteration 2: “the spoon was in front of the bear, draw it under the bear”) and produce a new image.
Training on data that represents this process can teach the model not only to generate an image based on a prompt but also to build up the image composition and correct it.
How it works: The authors started with BAGEL-7B, a pretrained multimodal model that takes images and text (say, two images and an instruction to combine them) and produces images and text (say, the combined image and a description of how the input image was changed). They fine-tuned it to generate images by cycling through stages to plan, sketch, inspect, and refine the composition.
- Fine-tuning to plan and sketch: To create a dataset for fine-tuning the plan and sketch stages, the authors generated 32,000 examples, each containing about three to five intermediate images and a final image. They did this by prompting GPT-4o to transform prompts from two datasets into text-based scene graphs. The graph nodes were objects (for example, “cat” or “bear”) or attributes of objects (“furry”), and edges encoded relationships between them (a cat “is” furry). From each graph, they randomly selected parts that contained objects, attributes, and relationships. They asked GPT-4o to turn the parts into incremental prompts to add those objects, attributes, and relationships to an image. They generated an image for each incremental change using FLUX.1 Kontext and kept only results that GPT-4o deemed consistent with the incremental prompts. The authors fine-tuned the model on the text-image examples. The model learned (i) to generate the next text tokens of the examples and (ii) to generate the next image by adjusting the pixel values of the current image over several flow-matching steps.
- Fine-tuning to inspect: To produce a dataset for fine-tuning the inspect stage, they used the model after fine-tuning to plan and sketch, they generated examples of incremental instructions and images and then asked GPT-4o to judge whether an intermediate text description conflicted with the original prompt. Finally, they prompted GPT-4o to produce critiques and corrective instructions. The authors produced nearly 7,000 examples that stayed consistent with the original prompt and nearly 8,300 inconsistent examples. By learning to reproduce the GPT-4o critiques and instructions, the model learned to either accept the current plan as consistent with the original prompt or describe how to fix inconsistencies.
- Fine-tuning to refine: The authors fine-tuned the model on a dataset of images, text reflections about how an image can be improved, and improved images.
- Finally, they fine-tuned the model on all three datasets together using the same loss terms as before.
Results: The authors’ fine-tuning method improved BAGEL-7B on tasks that require generating images in which object relationships match a text prompt (for example, placing a bear on a spoon instead of behind a spoon). It also improved BAGEL-7B’s ability to generate images based on real-world knowledge, such as scenes of a particular time of day or historical era.
- On GenEval, which measures the percentage of details mentioned in a prompt that appear in the resulting generated image, the authors’ method raised BAGEL-7B from 77 percent to 83 percent after fine-tuning on 62,000 examples; it used 131 flow-matching steps. In contrast, PARM, a method that improves image-generation by critiquing intermediate noisy diffusion states, achieved 77 percent after fine-tuning on 688,000 examples; PARM used 1,000 flow-matching steps.
- On WISE, which uses GPT-4o to rate realism, aesthetic quality and consistency between a generated image and its prompt (0 to 1, higher is better), the method raised BAGEL from 0.7 to 0.76 on average. The fine-tuned model more often placed scenes in the correct era or temporal context. Tested on a chemistry dataset, it more often generated chemically plausible structures, substances, and laboratory scenes.
Why it matters: Image generators frequently produce good-looking images, but their output is often at odds with the prompt. For instance, objects may be out of place and have the wrong attributes. This work offers a way to make such systems more dependable beyond simply scaling training data.
We’re thinking: An image generator that composes images in stages is analogous to an LLM that reasons over its input step by step. Both approaches direct the model to break down requests into pieces, and both improve the output.