A New Generation Studies AI, Apple's Recipe for On-Device Models, GLM5.2 Tackles Open-Ended Problems
The Batch News & Insights: “Loop engineering” is a hot buzzphrase after Boris Cherney (Claude Code’s creator) and Peter Steinberger (OpenClaw's creator) both mentioned it on social media.
Dear friends,
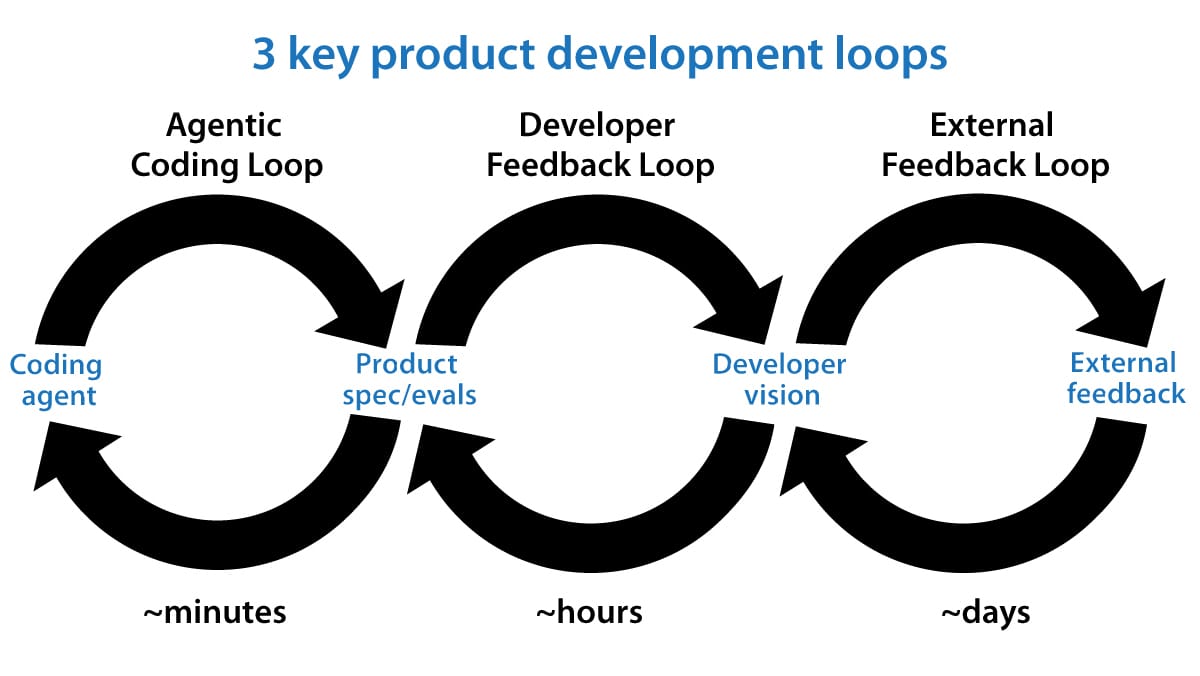
“Loop engineering” is a hot buzzphrase after mentions of it by Boris Cherny (Claude Code’s creator) and Peter Steinberger (OpenClaw's creator) went viral on social media. Loops are now a key part of how we get AI agents to iterate at length to build software. In this letter, I’d like to share my 3 key loops, shown in the image below, for building 0-to-1 products. These loops guide not just how I build software, but also how I decide what software to build.
Agentic coding loop: Given a product specification and optionally a set of evals (that is, a dataset against which to measure performance), we can have an AI agent write code, test its work, and keep iterating until the code is bug-free and meets its specification. This idea of closing the loop took off around the end of last year, and it has been a game changer in enabling coding agents to work longer productively without human intervention. For example, over the weekend, I was building an app for my daughter to practice typing, and my coding agent could easily work for around an hour, using a web browser to check what it had built multiple times before getting back to me, without needing my intervention.
The engineering loop executes quickly. Every few minutes, the coding agent might build and test a new version of the software. I hear frequently from developers who are finding new ways to engineer more effective engineering loops. This is an active area of invention!
Developer feedback loop: In this loop, a developer examines the current product and steers the coding agent to improve it. Last year, a lot of developers (including me) were acting as the QA (quality assurance) function for our coding agents, manually finding bugs and then asking the agent to fix them. But with coding agents much more able to test their own code, the amount of time we need to spend on this function has decreased significantly. This allows us to make higher-level product decisions, such as what key features to offer, where the UI needs improvement, and so on.
The developer-feedback loop operates over time intervals between tens of minutes and hours — that's how frequently a developer might review a product and give feedback. In the case of the typing app, I changed my mind a few times about the visual design, what cat costumes she can unlock as she learns (she loves cats), and the user flow for a grown-up to log in and steer the child's learning experience.
When a developer has a clear vision for what to build, it is still a lot of work to translate that vision into a specification for a coding agent to implement. Further, after the developer has seen an implementation, they might update (or perhaps clarify) the spec to steer it toward what they want. If you find that the system repeatedly runs into certain problems, building a set of evals for the agent becomes useful.
AI-native teams are increasingly using AI to help shape product direction, for example, automating the gathering and analysis of usage data, summarizing written and verbal customer feedback, or carrying out competitive analysis. However, for pretty much all the products I’m involved in, I see humans as having a significant context advantage over current AI systems — we know a lot more than the AI system about the users and the context the product has to operate in — and thus humans play a critical role. Many people describe this human contribution as “taste,” but I prefer to think of it as humans having a context advantage, since that gives us a clearer path to helping AI systems get better. This also speaks to why this step can’t be automated: So long as the human knows something the AI does not, human-in-the-loop is needed to to inject that knowledge into the system.
External feedback loop: This includes a wide range of tactics like asking a few friends for feedback, launching to alpha testers, or putting the code into production with A/B testing. These tactics are usually slow, rarely taking less than hours and sometimes taking days or even weeks. This data informs the developer vision, which in turn continues to drive the detailed product spec, which in turn drives the coding agent.
With coding agents speeding up software development, more engineers are starting to play a partial product management role. For many engineers who are growing into this role, the hardest part is shaping the product vision and striking a balance between building (bridging the gap between vision and spec) and getting user feedback to evolve the vision. It is important to do both!
I will write more about how to do this in future letters, but for now, I find it encouraging that engineers are playing an expanded role (just as product managers and designers now do more engineering).
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Stop watching your terminal. Learn to teach your agent to call you when it needs your input. Join the free 7-Day Voice AI Builder Challenge today.
News
Top Agentic Performance, Low Cost
Z.ai released an open-weights model that rivals proprietary leaders for autonomous agentic tasks.
What’s new: GLM-5.2, the latest in a series of large language models that are optimized for coding, including an input context far larger than its predecessor’s.
- Input/output: Text in (up to 1 million tokens), text out (up to 128,000 tokens, 103 tokens per second)
- Architecture: Mixture-of-experts transformer, 753 billion parameters total, 40 billion parameters active per token
- Features: Two reasoning levels (high, max), function calling, structured output, context caching (reuses inputs so repeated parts of prompts are not recomputed)
- Performance: First among open models (third among all currently available models) on Artificial Analysis’s Intelligence Index v4.1, leads all models on PostTrainBench (a test of long-running agentic coding), second on Arena.ai Code Arena WebDev leaderboard
- Availability/price: Weights available for commercial and noncommercial uses under MIT license via Hugging Face, API $1.40/$0.26/$4.40 per million input/cached/output tokens, GLM Coding Plans $12.60 to $112 per month
- Undisclosed: Training data and methods specific to GLM-5.2
How it works: GLM-5.2 builds on GLM-5. The team modified the earlier model’s implementation of DeepSeek sparse attention to reduce the processing required, making it practical to expand the input context to 1 million tokens from GLM-5’s 200,000 tokens.
- Z.ai trained GLM-5.2 specifically on long-running agentic tasks such as deep research, code deployment and performance optimization, and complex debugging.
- Earlier GLM models learned via Group Relative Policy Optimization, a reinforcement learning method that dispenses greater rewards for attempts to complete a task that outperform the average of several attempts. However, GLM-5.2’s tasks ran long enough that the team divided individual attempts into pieces, so they couldn’t average them easily. Instead, the team switched to Proximal Policy Optimization, which judges each attempt individually via a critic model.
- During reinforcement learning, a coding task usually is graded based on a pass-fail check. But an agentic process, instead of solving a problem, can pass such tests by using tools to, for instance, fetch reference solutions from GitHub. GLM-5.2 resorted to such reward hacking more frequently than GLM-5.1 did. To address this, the team added a rule-based filter that flagged suspect tool calls, used a separate language model to judge whether each flagged call shortcutted the task, and blocked such calls by feeding GLM-5.2 dummy data so training could continue.
- To reduce the computation required to process attention over longer contexts, the model uses a sparse attention indexer — a component that, for each new token, selects which earlier tokens to attend to — once every four layers instead of every layer, reusing its output for the other three layers. The company says this cuts per-token computation by 2.9 times within 1-million-token context. This approach modifies an earlier method called IndexCache.
- To generate tokens faster, a small draft model proposes several tokens at once and the main model accepts or rejects them in a process called speculative decoding. GLM-5.2 accepts 5.47 tokens compared to GLM-5.1’s 4.56, a 20 percent gain.
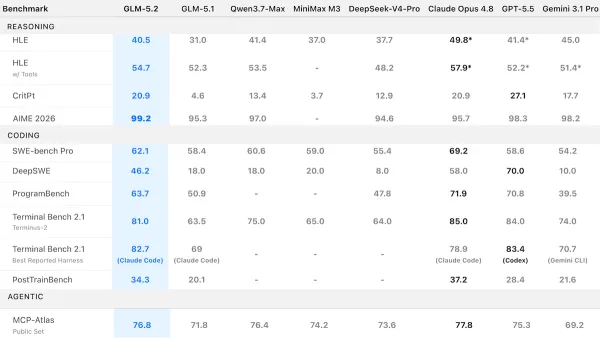
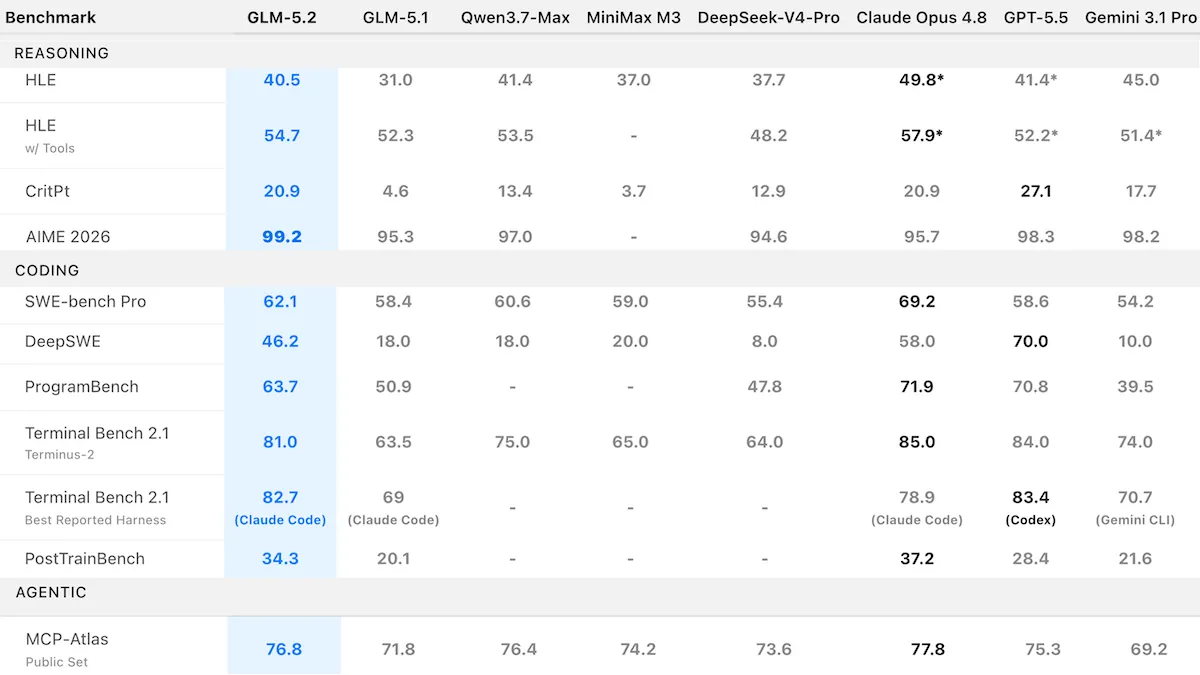
Performance: GLM-5.2 posted the strongest performance of any open-weights model in Artificial Analysis’s tests. It ran close to the leading proprietary models from Anthropic and OpenAI on several agentic benchmarks, edging ahead of some and trailing others narrowly.
- On Artificial Analysis’s Intelligence Index, a composite of 9 evaluations of economically useful tasks, GLM-5.2 set to max reasoning (51) ranked first among open-weights models, behind Claude Opus 4.8 set to max reasoning (56) and GPT-5.5 set to xhigh reasoning (55) but well ahead of DeepSeek V4 Pro set to max reasoning and MiniMax-M3 set to unspecified reasoning (tied at 44).
- On the Arena.ai Code Arena’s WebDev leaderboard, which ranks models according to human votes on web development tasks, GLM-5.2 set to max reasoning (1,593 Elo) ranked second behind Claude Fable 5 (1,654 Elo) and ahead of all variants of Claude Opus 4 and GPT-5.5.
- On PostTrainBench, a test that asks an agent to fine-tune four large language models and evaluates their performance on seven benchmarks, GLM-5.2 set to max reasoning (34.3 percent) narrowly topped Claude Opus 4.8 set to max reasoning (34.1 percent) and Claude Fable 5 set to max reasoning (30.7 percent).
- On AA-Briefcase, an Artificial Analysis benchmark introduced in June 2026 that scores agents’ ability to generate business documents such as spreadsheets, presentations, and memos, GLM-5.2 set to max reasoning (1,266 Elo) led all open-weights models and placed third overall behind Claude Fable 5 (1,587 Elo) and Claude Opus 4.8 set to max reasoning (1,356 Elo).
Behind the news: High-performance, open-weights models become more attractive as the U.S. government and U.S. companies tighten the screws on AI technology developed within the country. Z.ai released GLM-5.2 only one day after the U.S. government restricted access to Anthropic’s Claude Fable 5 and Claude Mythos 5 to citizens, and Anthropic suspended access to Claude Fable 5.
Why it matters: Beyond GLM-5.2’s open license, the low cost of Z.ai’s API gives developers an additional incentive to adopt it. Developers who find Claude Opus 4.8 or GPT-5.5 too pricey can obtain similar agentic and coding capabilities for as little as a quarter of the cost, according to Artificial Analysis’ assessment of cost per intelligence.
We’re thinking: Open weights continue to close in on top closed models. GLM-5.2’s outstanding performance on web-dev and post-training tasks suggests that advanced agentic capabilities are available to anyone with sufficiently advanced hardware, free of charge.
AI Degrees on the Rise
Universities in the U.S. are rapidly rolling out undergraduate majors, minors, and specializations in artificial intelligence to meet the growing demand for AI expertise.
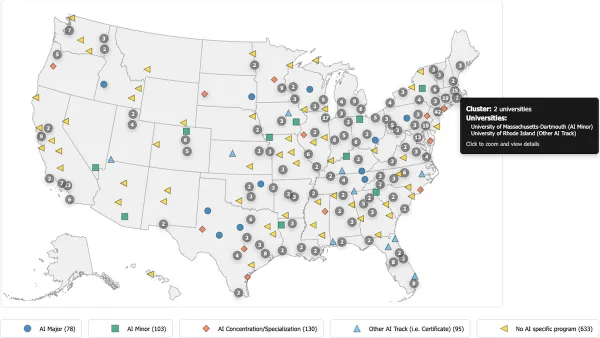
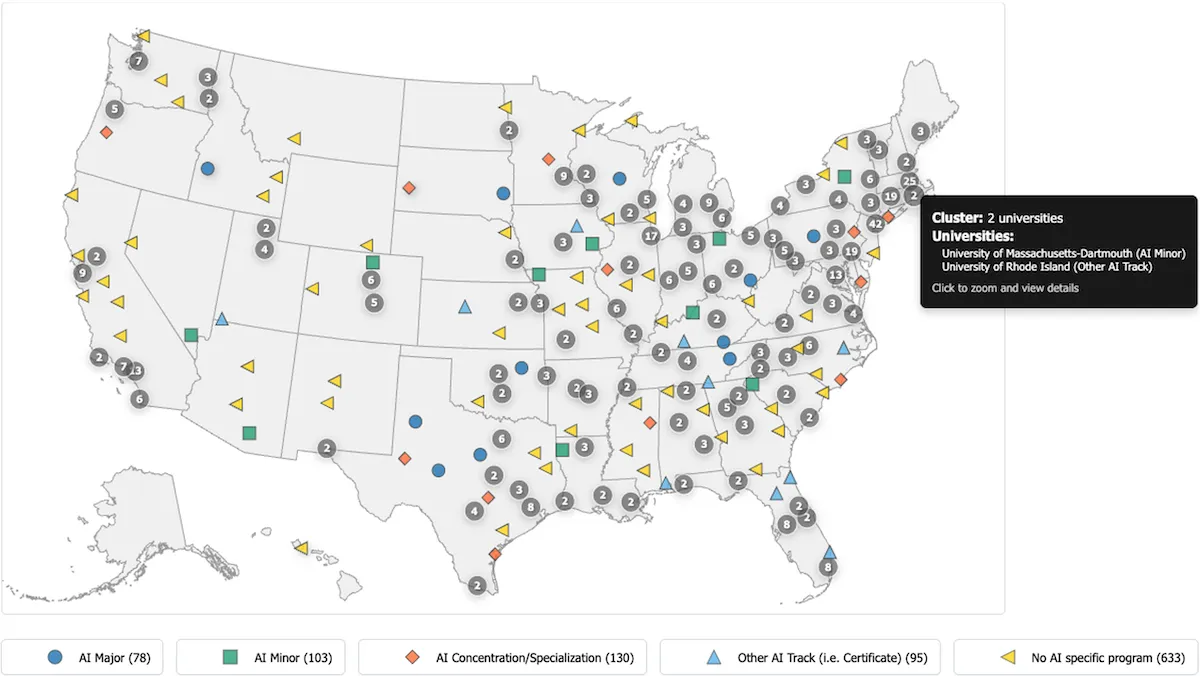
What’s new: There are at least 1,000 AI programs across nearly 584 U.S. colleges and universities, including 78 majors and 103 minors as of April, according to the Center for Inclusive Computing at Northeastern University. These numbers have risen dramatically. In 2021, just five schools offered majors in AI, The New York Times reported.
How it works: Course requirements for a bachelor’s degree in artificial intelligence run the gamut. Some programs are highly technical and math-intensive, while others take a broader, interdisciplinary approach that includes courses in ethics, policy, or domain-specific applications. Some emphasize the theoretical foundations of AI, while others focus on how to build and deploy AI systems in practice.
- Carnegie Mellon University, a university in the state of Pennsylvania with one of the country’s top Computer Science programs, became the first U.S. university to offer a bachelor’s degree in artificial intelligence in 2018. Its curriculum emphasizes mathematical rigor, requiring seven courses in mathematics and statistics, five in computer science and principles of computing and programming, three in artificial intelligence, one in ethics, and additional courses spanning human cognition, perception and language, machine learning, and human-computer interaction.
- The University of Oklahoma Polytechnic Institute’s applied AI degree focuses on practical knowledge. Apart from math and statistics requirements, it requires students to complete 15 AI and computing courses in subjects including robotics, machine learning, reinforcement learning, computer vision, cloud computing, and DevOps.
- Other AI degrees are more interdisciplinary. Drake University in Iowa offers a bachelor of arts in AI tailored to students in humanities and business. The course requirements are flexible, allowing students to choose from clusters of courses in philosophy, English, computer science, information systems, and psychology. Only two math classes are required for the degree.
- Many schools that don’t provide AI degrees offer specialized AI concentrations. Students on the AI track at Stanford University take seven qualifying courses in fields such as natural language processing, computer vision, and robotics. (Disclosure: Andrew Ng serves as an adjunct professor in Stanford’s Computer Science department.)
Behind the news: Some commentators argue that universities have moved too slowly to prepare students for employers that expect AI competency. Others dismiss AI degrees as a fad. However, even some proponents warn that specialized AI degrees may come at the expense of broader computer science foundations, which students may need to adapt in a rapidly evolving field.
Why it matters: Today’s curricula could shape who enters the profession and what skills the next generation of AI engineers brings with them. It’s only natural to expect a standardized, one-size-fits-all education in a field as varied as AI. Some roles in industry resemble traditional software engineering jobs with AI components; others require deeper expertise in machine learning research, distributed systems, or data engineering. There will also always be large gaps between programs designed to prepare students for graduate work and others that assume the bachelor’s will be a terminal degree.
We’re thinking: AI is moving so quickly that many universities are struggling to adapt. The established pace of change in academic curricula — in which the faculty learns a topic, proposes new courses, gets approval from a curriculum committee, and perhaps modifies degree requirements — is poorly matched to the rapid pace of change of AI. However, we are glad that universities are moving in this direction, and that a number of innovative faculty and administrators are finding ways to move faster. This will be important to prepare students not only for the jobs of 2026, but for those in many years beyond.
Large-Model AI for Apple Devices
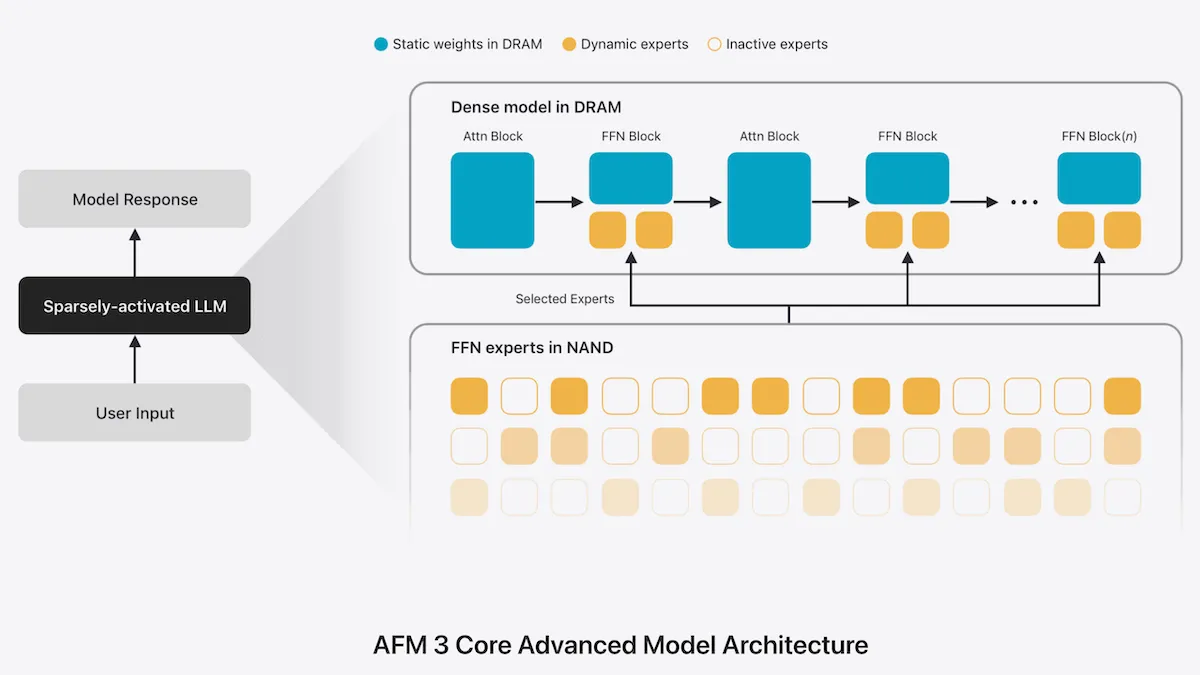
The third generation of Apple Foundation Models — fruit of Apple’s collaboration with Google — introduces a variation on the mixture-of-experts architecture that runs on local devices.
What’s new: AFM 3 Core Advanced, a model designed to generate text and speech on some Apple devices, exceeds the processing efficiency of the popular mixture-of-experts architecture while occupying substantially less working memory. (Other models in the AFM 3 family, all of which are custom-built and distilled from unspecified Google Gemini models, include AFM 3 Core, which also runs on Apple devices, and AFM 3 Cloud, AFM 3 Cloud Image, and AFM 3 Cloud Pro, which run on servers.)
- Input/output: Text, images, speech in; text, speech out
- Architecture: Modified mixture-of-experts transformer (20 billion parameters total, 1 to 4 billion parameters active)
- Availability: Available in fall 2026 with Apple operating system updates to Macs and iPhone 17 Pro/Max/Air phones
- Features: Text understanding and generation, speech understanding and generation, image understanding, tool use, skills, reasoning, 25 languages
- Undisclosed: input/output size limits, benchmark performance, specific training data and methods
How it works: AFM 3 Core Advanced is optimized to run on Apple silicon.
- Like other models in its family, AFM 3 Core Advanced was trained on a mixture of publicly available information, licensed data, data collected from studies, and generated data. No user data or user interactions with models was included. The training process included pretraining, supervised fine-tuning, and reinforcement learning.
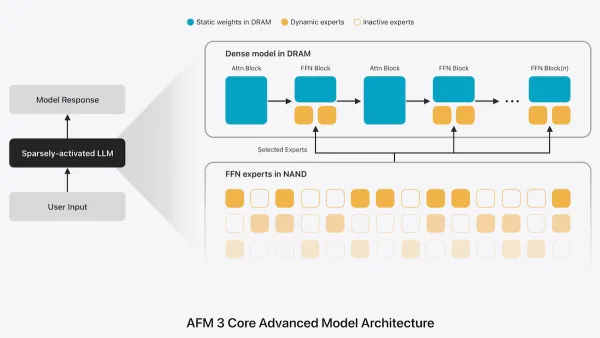
- An alternative to MoE called Instruction-Following Pruning enables AFM 3 Core Advanced to run more quickly and memory-efficiently. A typical mixture-of-experts model uses routing layers within the model to choose which parts of the network (experts) to activate for each output token. Instead of using routing layers within the model, AFM 3 Core Advanced uses a separate transformer to choose which experts to activate for some or all output tokens. Since the network doesn’t switch experts for every token, it can achieve faster inference than typical mixture-of-experts models of the same size.
Results: Apple has not yet published any benchmark results for AFM 3 models yet. It says it will release results later in the year. Like other AFM 3 models, AFM 3 Core Advanced outperformed the previous generation in proprietary measurements of human preference.
Behind the news: In January, Apple struck a multi-year agreement with Google to use Gemini models as the basis of its AI models. As part of the AFM 3 launch, Apple Vice President of AI Amar Subramanya revealed that the models were "distillation-based, not a wholesale adoption of Gemini.” Concurrently, Apple announced plans for its Foundation Models Framework to accommodate models from other companies. Developers who are building on Apple hardware will be able to choose between AFM 3 models and alternatives that implement Apple’s LanguageModel protocol, including Anthropic Claude or Google Gemini families.
Why it matters: AFM 3 Core Advanced’s architecture is a notable accomplishment. A typical mixture of experts requires loading the whole model into active memory (RAM or VRAM), since loading the experts token by token from flash-memory storage is slow. AFM 3 Core Advanced uses the same experts across multiple tokens. This makes it practical to store the model in flash memory — a larger, more capable model that can run on local devices.
We’re thinking: Constraints on memory and bandwidth make it impractical for most apps to download and run multi-billion-parameter models. So iOS developers have ample incentive to use streamlined models that are designed to run on iOS hardware. Moreover, Apple’s partnership with Google lets it tap into the latter’s expertise at running such models on phones.
Biological Molecules as Language
Google’s AlphaFold models pioneered the task of finding the shapes of biologically active molecules, opening new pathways for drug development. An open-source team refined AlphaFold 3’s architecture using insights drawn from large language models.
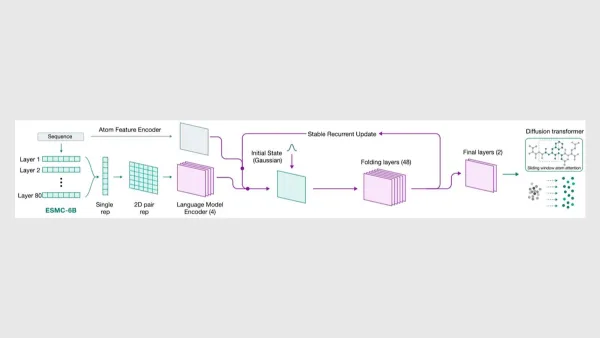
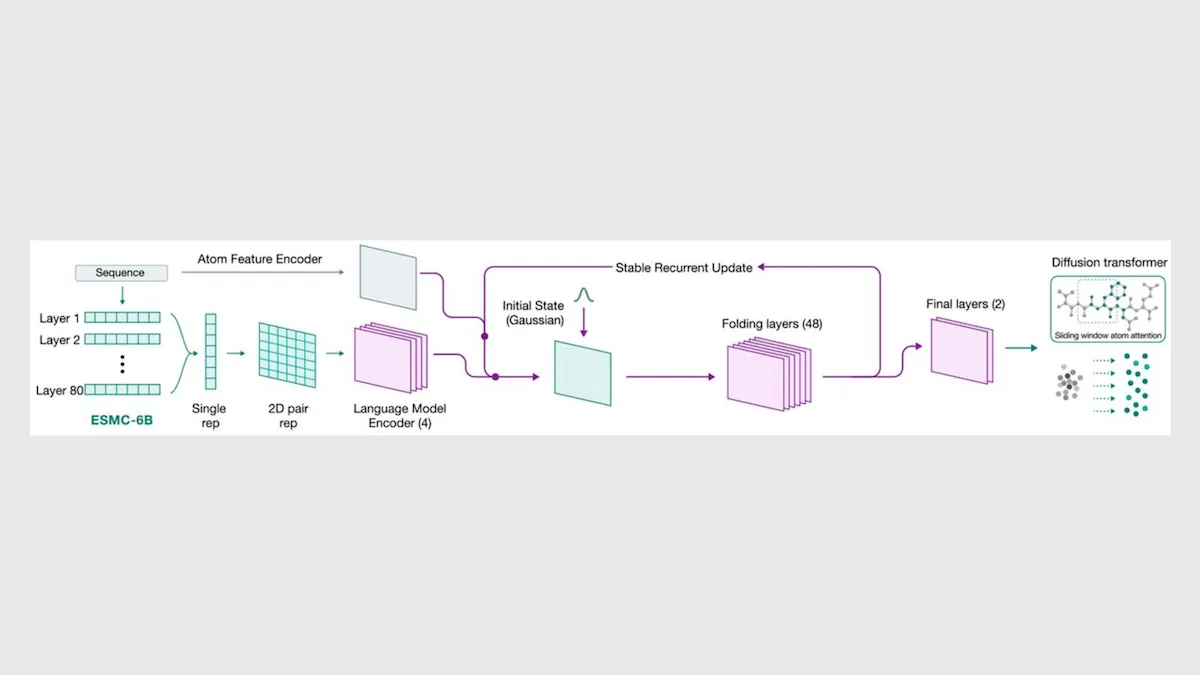
What’s new: A team at the non-profit biomedical research organization Biohub and the independent AI-for-biology lab EvolutionaryScale released ESMFold2, which infers the shapes of biologically active molecules — including proteins, DNA, RNA, and molecules that bind to them — by treating their components like a natural language. Where AlphaFold 3 and ESMFold2 infer molecular shapes by considering characteristics of multiple related molecules that have been aligned for comparison, ESMFold2 can also use a separate transformer to embed individual molecules directly, in the manner of a large language model. In addition to ESMFold2, the team released its embedding model, which is called ESMC.
- Input/output: Input is an amino-acid sequence that defines proteins, base-pair sequence that defines DNA or RNA, standardized text description (SMILES) of other biologically active molecules, or multiple sequence alignment (MSA) that aligns related amino-acid or base-pair sequences; output is molecular shape and error estimates
- Architecture: Mixed (6.2 billion parameters)
- Performance: Outperforms AlphaFold 3 and other competing models when inputs are not MSAs, comparable to AlphaFold and other competing models when inputs are MSAs
- Availability: Free via website, weights available for download via HuggingFace, API via Biohub
Key insight: To analyze a given molecule, AlphaFold3 and similar models must also receive an MSA, which requires finding related molecules in existing databases and aligning them properly. But transformer-based large language models are good at producing embeddings based on large amounts of training data, and databases are available to provide vast numbers of sequences and standardized text descriptions of bioactive molecules. A transformer can be trained to embed individual molecules, and the embedding can serve as input instead of an MSA.
How it works: Given a protein, DNA, or RNA sequence or description of a bioactive molecule, ESMFold2 (i) embeds the input in three different ways, including (a) the sequence, (b) its atoms, and (c) an MSA if it receives one. (ii) It produces an embedding that represents the physical distances between amino acids, base pairs, or atoms in a molecule. (iii) It estimates the coordinates of the atoms in the input. And (iv) it estimates its error in those coordinates. It learned to perform these steps using two datasets that match existing sequences and descriptions to their shapes.
- Given an input, the system produced three embeddings. (a) To embed amino-acid or base-pair sequences, the system uses ESMC, a transformer model. This model was trained to fill in masked tokens in roughly 2.8 billion sequences in three protein databases.
- (b) A separate transformer embedded the atoms. (c) To embed MSAs, the system uses a pairmixer model that updates each element in a matrix based on the elements in the same row or column of the matrix. In this model, the matrix represents an MSA.
- Given these embeddings, another pairmixer produces an embedding that represents the pairwise distances between amino acids, base pairs, and atoms. The embedding starts as pure noise. During training, it was refined by cycling through the model up to 6 times. (At inference, it cycles 10 times, as this delivered the best performance.)
- Given the embedding of distances, embeddings of sequences and atoms, and a noisy point cloud of atoms, the diffusion model removes the noise to deduce the atoms’ positions.
- Given the embeddings of distance, sequences, and atoms and the point cloud, a third pairmixer estimates various errors, including the error between the predicted distances and actual distances between pairs of atoms.
Results: The authors tested ESMFold2 using FoldBench, which includes tests of finding the shapes of biologically active molecules in various combinations. Given only proteins as input, ESMFold2 outperformed Chai-1, a molecular model that doesn’t accept MSAs. Given MSAs, it performed similarly to competing models that use MSAs, including AlphaFold3.
- The team evaluated the ability, given a protein sequence, to deduce its shape according to Local Distance Difference Test (lDDT), which measures similarity between estimated inter-atom distances and ground truth, higher is better. ESMFold2 achieved 0.85 lDDT, while Chai-1 achieved 0.81 lDDT.
- Testing the same capability given an MSA, ESMFold2 achieved 0.89 lDDT, the same as AlphaFold3 and Protenix-v1.
- Given a protein and a DNA molecule that were bound together, the team evaluated the DockQ pass rate, or the similarity between estimated inter-atom distances and ground truth at the points where the molecules touch, higher is better. ESMFold2 (80 percent) slightly outperformed Chai-1 (71 percent). Given the same molecules plus an MSA, ESMFold2 (79 percent) matched Protenix-v1 but underperformed AlphaFold3 (82 percent).
Behind the news: ESMFold2 is an update to Biohub’s 2022 ESMFold. It’s bigger and trained on more data. In addition, its architecture incorporates top-performing components proposed in other work, notably AlphaFold3, such as a diffusion model that predicts atom coordinates and a model that estimates error in the system’s output.
Why it matters: Using a transformer — essentially a large language model — to embed molecules gives ESMFold2 the ability to process input molecules without requiring an aligned set of biologically related molecules. This capability reduces friction in biological research. It's especially important if a molecule is novel (such as a rapidly evolving viral protein) or synthetic (such as a product of synthetic biology) and if information about related molecules is scarce. Moreover, since the system has open weights, it’s freely available to scientists whatever their means or affiliation.
We're thinking: LLMs have proven the value of applying more processing at inference. ESMFold2’s distance-estimation model uses the same principle, improving performance by cycling its embedding through the model multiple times.