More Robust Medical Diagnoses: Inside Dr Cabot, an agent trained to diagnose complex conditions
AI models that diagnose illnesses typically generate diagnoses based on descriptions of symptoms. In practice, though, doctors must be able to explain their reasoning and plan next steps. Researchers built a system that accomplishes these tasks.
AI models that diagnose illnesses typically generate diagnoses based on descriptions of symptoms. In practice, though, doctors must be able to explain their reasoning and plan next steps. Researchers built a system that accomplishes these tasks.
What’s new: Dr. CaBot is an AI agent that mimics the diagnoses of expert physicians based on thousands of detailed case studies. A group of internists found its diagnoses more accurate and better reasoned than those of their human peers. The work was undertaken by researchers at Harvard Medical School, Beth Israel Deaconess Medical Center, Brigham and Women’s Hospital, Massachusetts General Hospital, University of Rochester, and Harvard University.
Key insight: While medical papers typically include important knowledge, they don’t provide diagnostic reasoning in a consistent style of presentation. However, a unique body of literature offers this information. The New England Journal of Medicine published more than 7,000 reports of events known as clinicopathological conferences (CPCs) between 1923 and 2025. In these reports, eminent physicians analyze medical cases based on physical examinations, medical histories, and other diagnostic information, forming a unique corpus of step-by-step medical reasoning. Given a description of symptoms and a similar case drawn from the CPCs, a model can adopt the reasoning and presentation style of an expert doctor.
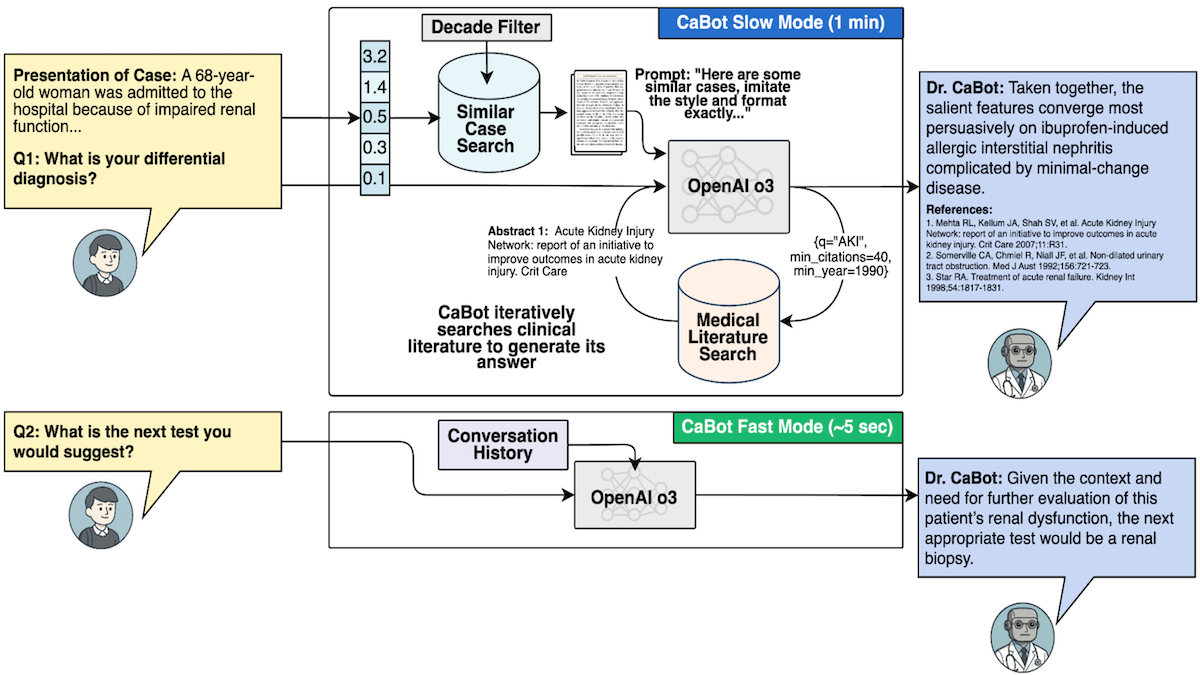
How it works: The authors digitized CPC reports of 7,102 cases published between 1923 and 2025. They built Dr. CaBot, an agentic system that uses OpenAI o3 to generate text. To test Dr.CaBot and other diagnostic systems, they developed CPC-Bench, 10 tasks that range from answering visual questions to generating treatment plans.
- OpenAI’s text-embedding-3-small model embedded the CPC case reports, and Dr. CaBot stored the embeddings in a database.
- The embedding model embedded 3 million abstracts of medical papers drawn from OpenAlex, an index of scientific literature.
- Given a description of symptoms, text-embedding-3-small embedded it. Dr. CaBot retrieved two CPC case reports with similar embeddings.
- To gather additional context, given the symptoms and the retrieved CPC case reports, o3 generated up to 25 search queries. Text-embedding-3-small embedded the queries, and Dr. CaBot used the embeddings to retrieve the most similar abstracts.
- Based on the symptoms, CPC case reports, queries, and retrieved abstracts, o3 generated a diagnosis and reasoning to support it.
Results: To evaluate Dr. CaBot quantitatively, the authors used their own CPC-Bench benchmark. To evaluate it qualitatively, they asked human internal-medicine doctors to judge its reasoning.
- CPC-Bench asks a model, given a description of symptoms, to produce a list of plausible diagnoses and rank them according to their likelihood. The benchmark uses GPT-4.1 to judge whether the output contains the correct diagnosis. Dr. CaBot ranked the correct diagnosis in first place 60 percent of the time, surpassing a baseline of 20 internists, who achieved 24 percent.
- In blind evaluations, five internal-medicine doctors awarded higher ratings to Dr. CaBot’s reasoning for its diagnoses than to human peers. Asked to identify whether the diagnosis and reasoning came from a human doctor or an AI system, they identified the source correctly 26 percent of the time (which suggests the model’s reasoning style often struck the judges more human-ish than humans themselves)!
Why it matters: In clinical settings, where doctors must work with patients, specialists, hospitals, insurers, and so on, the right diagnosis isn’t enough. It must be backed up by sound reasoning. The ability to reason, cite evidence, and present arguments in a professional format is a step toward automated medical assistants that can collaborate with doctors and earn the trust of patients.
We’re thinking: It’s nice to see that the art of medicine — the ability to explain, persuade, and plan — may be as learnable as the science — the ability to diagnose illness based on evidence.