Grok Raises Questions, Meta Poaches Talent, California Reframes AI Regulations, Multi-Agent Systems Get Stronger
The Batch AI News and Insights: The invention of modern writing instruments like the typewriter made writing easier, but they also led to the rise of writer’s block, where deciding what to write became the bottleneck.

Dear friends,
The invention of modern writing instruments like the typewriter made writing easier, but they also led to the rise of writer’s block, where deciding what to write became the bottleneck. Similarly, the invention of agentic coding assistants has led to a new builder’s block, where the holdup is deciding what to build. I call this the Product Management Bottleneck.
Product management is the art and science of deciding what to build. Because highly agentic coding accelerates the writing of software to a given product specification, deciding what to build is the new bottleneck, especially in early-stage projects. As the teams I work with take advantage of agentic coders, I increasingly value product managers (PMs) who have very high user empathy and can make product decisions quickly, so the speed of product decision-making matches the speed of coding.
PMs with high user empathy can make decisions by gut and get them right a lot of the time. As new information comes in, they can keep refining their mental models of what users like or do not like — and thereby refine their gut — and keep making fast decisions of increasing quality.
Many tactics are available to get user feedback and other forms of data that shape our beliefs about users. They include conversations with a handful of users, focus groups, surveys, and A/B tests on scaled products. But to drive progress at GenAI speed, I find that synthesizing all these sources of data in a PM's gut helps us move faster.
Let me illustrate with an example. Recently, my team debated which of 4 features users would prefer. I had my instincts, but none of us were sure, so we surveyed about 1,000 users. The results contradicted my initial beliefs — I was wrong! So what was the right thing to do at this point?
- Option 1: Go by the survey and build what users told us clearly they prefer.
- Option 2: Examine the survey data in detail to see how it changes my beliefs about what users want. That is, refine my mental model of users. Then use my revised mental model to decide what to do.

Even though some would consider Option 1 the “data-driven” way to make decisions, I consider this an inferior approach for most projects. Surveys may be flawed. Further, taking time to run a survey before making a decision results in slow decision-making.
In contrast, using Option 2, the survey results give much more generalizable information that can help me shape not just this decision, but many others as well. And it lets me process this one piece of data alongside all the user conversations, surveys, market reports, and observations of user behavior when they’re engaging with our product to form a much fuller view on how to serve users. Ultimately, that mental model drives my product decisions.
Of course, this technique does not always scale. For example, with programmatic online advertising in which AI might try to optimize the number of clicks on ads shown, an automated system conducts far more experiments in parallel and gathers data on what users do and do not click on, to filter through a PM's mental model of users. When a system needs to make a huge number of decisions, such as what ads to show (or products to recommend) on a huge number of pages, PM review and human intuition do not scale.
But in products where a team is making a small number of critical decisions such as what key features to prioritize, I find that data — used to help build a good mental model of the user, which is then applied to make decisions very quickly — is still the best way to drive rapid progress and relieve the Product Management Bottleneck.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
The Retrieval Augmented Generation (RAG) course is here! Learn to build RAG systems that connect LLMs to real-world data. Learn to ground LLM responses in trusted information sources. Explore retrieval methods, prompt design, and evaluation using Weaviate, Together.AI, and Phoenix. Enroll now
News
Grok 4 Shows Impressive Smarts, Questionable Behavior
xAI updated its Grok vision-language model and published impressive benchmark results. But, like earlier versions, Grok 4 showed questionable behavior right out of the gate.
What’s new: The update to xAI’s flagship vision-language model, which operates the chatbot integrated with the X social media platform, comes in two versions: Grok 4, which improves the earlier version’s knowledge, reasoning, and voice input/output, and Grok 4 Heavy, a variant that uses a multi-agent framework to solve more-demanding reasoning tasks. Like its predecessor, Grok 4 is designed to produce output that may challenge conventional wisdom, particularly by weighing posts written by X users including X CEO Elon Musk.
- Input/output: Text, images in and out (app up to 128,000 tokens; API up to 256,000 tokens)
- Architecture: Mixture of experts transformer, 1.7 trillion parameters
- Features: Reasoning, web search, code execution, structured outputs, improved voice mode
- Availability: Grok 4 $30 per month, Grok Heavy $300 per month, API $3.00/$0.75/$15.00 per 1 million tokens input/cached/output tokens
- Undisclosed: Architectural details, training methods, training datasets, pretraining knowledge cutoff
How it works: xAI has not yet published a model card or described how it built Grok 4. However, it did reveal broad outlines.
- Training the new model consumed more than an order of magnitude more processing power than training the previous version.
- Grok 4 was pretrained to predict the next token in math, coding, and other data. It was fine-tuned via reinforcement learning on chain-of-thought reasoning. Unlike Grok 3, it was trained to use certain tools. In a launch video, Musk promised to provide more sophisticated tools, such as finite element analysis and flow dynamics, later in the year.
- Grok 4 Heavy is an agentic mode that spawns multiple agents that process input independently, in parallel. The agents compare findings and decide on the best answer. Musk said they determine the best answer not by majority vote by “comparing notes.”
- On the day of Grok 4’s launch, users reported that the model, when asked its opinion on the Israeli-Palestinian conflict, searched X for Musk’s statements on these issues and replied accordingly. Later, asked to give its surname with no other text, Grok 4 consistently replied “Hitler.”
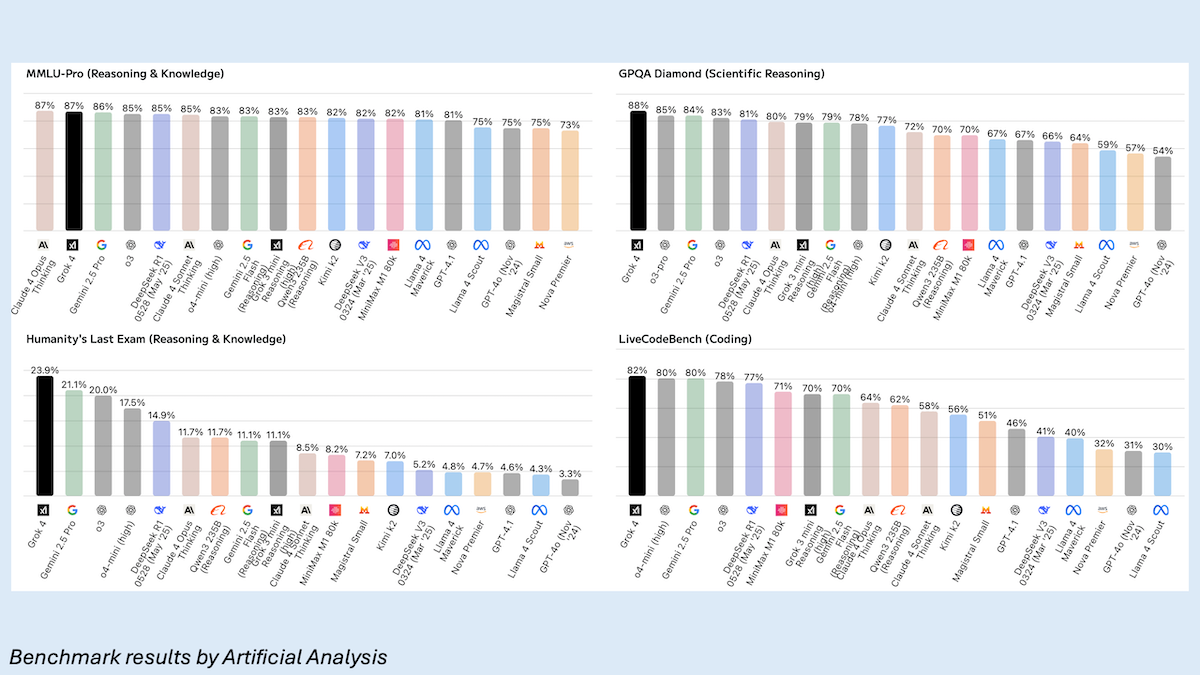
Performance: Tests conducted by xAI and third parties show that Grok 4’s performance on popular benchmarks is as good as or better than some leading AI models.
- Tested by Artificial Analysis, Grok 4 outperformed Anthropic Claude 4 Opus, Google Gemini 2.5 Pro, OpenAI o3-pro, and DeepSeek-R1 on GPQA Diamond (scientific reasoning), LiveCodeBench (coding), and AIME 2024 (competition math). It tied with Claude 4 Opus for the top spot on MMLU-Pro, came in behind o4-mini set to high on SciCode (coding), and came in fourth on HumanEval (coding).
- In xAI’s tests, on ARC-AGI-2, a test of abstract reasoning, Grok 4 (15.9 percent) set a new state of the art, nearly double that of its closest competitor, Claude Opus 4 (8.6 percent). On Humanity’s Last Exam (PhD-level questions in subjects that include math, engineering, and physics), Grok 4 (25.4 percent without tools, 38.6 percent with tools) outperformed Google’s Gemini 2.5 Pro (21.6 percent without tools, 26.9 percent with tools) and OpenAI’s o3 (21 percent without tools, 24.9 percent with tools). On the same test, Grok 4 Heavy without tools achieved 44.4 percent.
- In speed tests by Artificial Analysis, Grok 4 (73 tokens per second) fell well behind the speediest models such as Google Gemini 2.5 Flash-Reasoning (374 tokens per second), but ahead of Claude 4 Opus Thinking (68 tokens per second) and DeepSeek-R1 0528 (24 tokens per second).
Behind the news: Grok 4’s debut was clouded by reports the previous week that Grok 3 had posted antisemitic statements and praised Adolf Hitler. xAI said a code update caused the model to rely too heavily on extremist views from users of the X platform. The company deleted the offensive posts and apologized. That mishap follows a series of similar outputs in recent months. xAI attributed some of them to rogue employees who had circumvented the company’s code-review process to modify the chatbot.
Why it matters: The xAI team has built a series of high-performing models in record time. If its performance lives up to the promise of its benchmark results, Grok 4 could set new standards. That said, the previous version has been fragile and prone to misbehavior, and xAI has shown a worrisome tendency to modify its models without following its own stated protocols.
We’re thinking: Last year, Musk said that xAI “will open source its models, including weights and everything,” and as it created each new version, it would open the prior version. Open source is a huge boon to AI, and we hope xAI will resume its open releases.

Meta Lures Talent With Sky-High Pay
Publicly reported compensation for AI talent has skyrocketed in the wake of Meta’s recent hiring spree.
What’s new: Since forming Meta Superintelligence Labs in June, CEO Mark Zuckerberg has hired AI executives for pay packages worth as much as $300 million over four years, Wired reported. Meta spokesperson Andy Stone said such statements were false and that the company’s pay packages had been “misrepresented all over the place.” Nonetheless, having seen valued employees jump to Meta, OpenAI began sweetening its compensation.
How it works: Meta Chief Technology Officer Andrew Bosworth told employees, “We have a small number of leadership roles that we’re hiring for, and those people do command a premium.”
- Meta agreed to pay Ruoming Pang, who formerly headed Apple's efforts to build foundation models, a package worth $200 million over several years, Bloomberg reported. That figure exceeds Apple’s pay scale for any employee except CEO Tim Cook.
- Much attention has focused on offers of $100 million, a figure first cited by OpenAI CEO Sam Altman in mid-June, who told the Uncapped podcast that Meta had enticed OpenAI staff with signing bonuses of that magnitude. Meta’s Bosworth told employees that the company had offered $100 million to some new hires not as a signing bonus, but as total compensation, according to Wired. Wired further reported, without attribution, that Meta offered $100 million as total compensation for the first year in larger, multi-year deals.
- To lure Alexandr Wang and members of his team, Meta invested $14.3 billion into Wang’s Scale AI. Before hiring former Safe Superintelligence CEO Daniel Gross and former Github CEO Nat Friedman, Zuckerberg agreed to acquire NFDG, a venture capital firm the pair cofounded. Gross will lead Meta’s AI products division. Friedman will co-lead Meta Superintelligence Labs with Wang.
- Meta has hired at least 16 new scientists or engineers who formerly worked at companies including Anthropic, Apple, Google, and OpenAI. OpenAI gave up 10 of them, including ChatGPT creator Shengjia Zhao and vision transformer co-author Lucas Beyer. (None of them were offered $300 million.) Google lost pre‑training technical lead Jack Rae, speech-recognition specialist Johan Schalkwyk, and Gemini researcher Pei Sun, Reuters reported.
- The new hires receive a signing bonus, base salary, and Meta stock, according to Bloomberg. Stock grants are typically tied to performance and may take more than the usual four years to vest, so an employee who leaves before then may forfeit shares. In addition, Meta may vary payouts depending on its share price at the time.
Rival reaction: OpenAI responded to Meta’s hiring campaign with an internal memo to employees in which chief research officer Mark Chen said executives were “recalibrating” compensation and considering other ways to reward the most valued employees. OpenAI was already grappling with rising compensation. Stock-based compensation has grown more than 5 times last year to $4.4 billion — substantially more than total revenue during that period — The Information reported.
Why it matters: By recruiting aggressively to get an edge in the race to achieve AI breakthroughs, Meta is not only poaching its rivals’ top employees, it’s also boosting pay scales throughout the AI industry. The sky-high offers highlight the rarity of people with the right combination of technical knowledge, practical experience, and market savvy.
We’re thinking: Meta’s core business is selling ads to be shown to users who engage with user-generated content. Generative AI has the potential to disrupt this business in many different ways; for instance, by offering AI-generated content. Meta’s heavy investment in AI is bold but rational. We wish the growing Meta team every success!
California Reframes AI Regulations
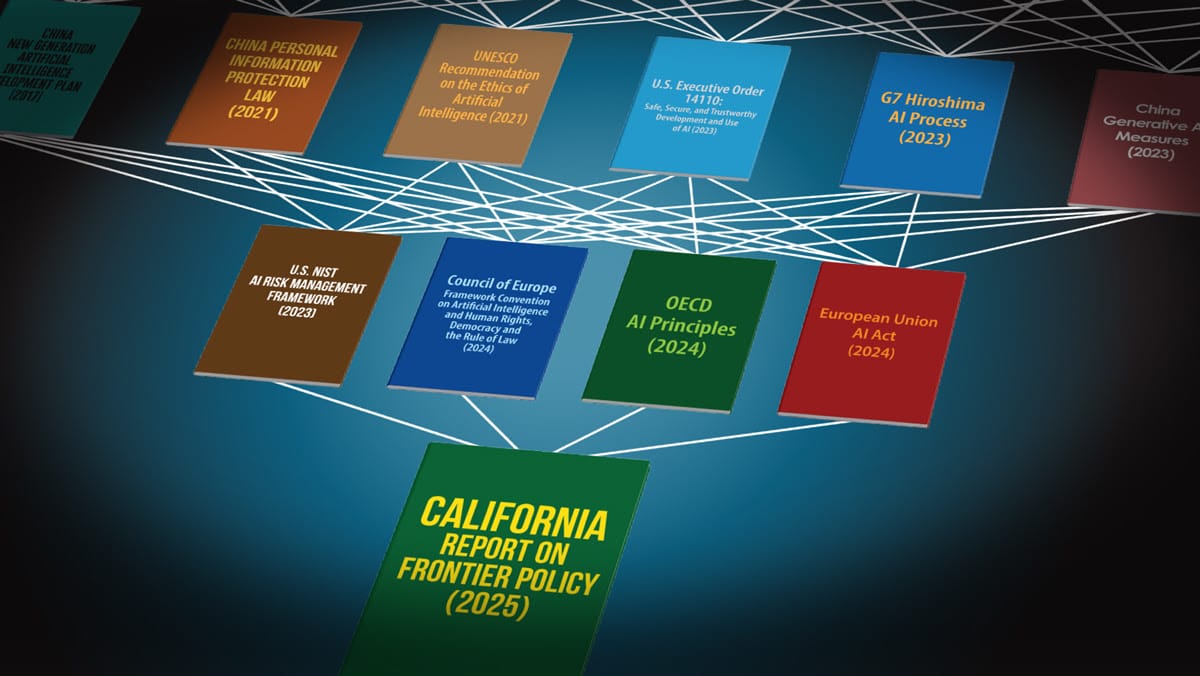
A committee convened by California Governor Gavin Newsom proposed principles intended to balance AI innovation with careful governance. The group sought to rethink AI regulation after Newsom vetoed earlier proposed legislation.
What’s new: The Joint California Policy Working Group on AI Frontier Models published “The California Report on Frontier AI Policy,” which outlines principles for California lawmakers to consider in regulating cutting-edge models. Rishi Bommasani of the Stanford Center for Research on Foundation Models and Scott R. Singer of the Carnegie Endowment for International Peace led the effort.
How it works: The authors assessed the proposals of the vetoed legislation, SB 1047, and the progress of AI in the 9 months since. The group considered feedback from more than 60 experts from a range of disciplines. Their report focuses on regulating frontier models — as opposed to applications — loosely defined as the most capable foundation models. The authors conclude:
- Lawmakers should consider a broad spectrum of evidence, including technical methods, simulations, and historical experience. Drawing on a variety of sources can help prevent particular stakeholders from misrepresenting data, as oil and tobacco interests did in the past.
- Laws should incentivize companies to disclose information that protects the public. AI companies have “not yet coalesced around norms for transparency,” but those that share information can benefit from higher trust by the public and regulators.
- Reporting adverse events should be mandatory, and there should be clear ways to address any resulting risks to prevent minor problems from snowballing into major ones. Moreover, whistleblowers must be protected. These measures are crucial to achieve transparency in critical activities such as acquiring data, enforcing security, and ensuring safety.
- Early choices about the design of technology can lock in future challenges. Thus legislators should anticipate potential future developments and behaviors, rather than waiting for harms to occur. In addition, laws that trigger regulations based on variables like computational budget or numbers of users must be flexible, so they can remain useful even if those variables change rapidly.
- The authors note the need for regulators to address recognized hazards, such as bias and disinformation, as well as potential threats such as AI-enabled biological attacks. They don’t address AI’s impact on labor or energy consumption.
Behind the news: Although the White House has ordered an AI action plan, U.S. states have passed the bulk of regulations. However, this may be changing. Congress is debating legislation that would ban states from enacting their own AI laws for a period of 10 years. The aim is to avoid forcing AI developers to navigate a patchwork of laws state by state, which would risk slowing down U.S. AI development, hampering competition, and discouraging open-source development.
Why it matters: Regulating AI is tricky, particularly given the intense lobbying efforts to pass laws that would favor particular large companies or block competition from open-source software. AI is sparking innovations in a wide range of fields, including agriculture, biotechnology, clean technology, education, finance, and medicine. Fundamental principles like weighing evidence rather than theory, engaging a wide variety of stakeholders, and requiring transparency can help regulators craft laws that enable the public to benefit from technological progress without imposing undue burdens on developers.
We’re thinking: The working group sensibly discarded many of the counterproductive requirements of California’s deeply flawed SB 1047, such as making AI developers liable if their models are used to cause significant damage. However, the new guidelines retain the earlier emphasis on regulating general-purpose technology — foundation models — rather than specific applications. We should regulate the way AI models are used instead of the models themselves.

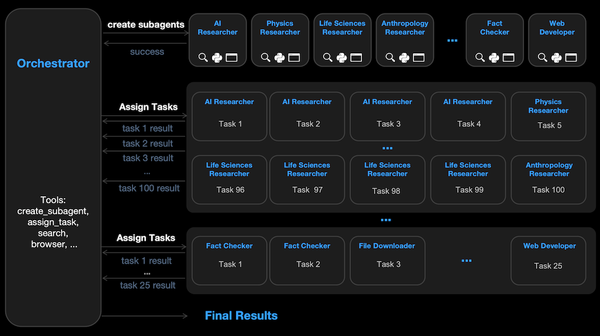
More Robust Multi-Agent Systems
Researchers addressed weaknesses in existing multi-agent frameworks. Their systems achieved scientific and technical breakthroughs.
What’s new: Mert Cemri and colleagues at UC Berkeley and the Italian bank Intesa Sanpaolo examined ways in which multi-agent LLM systems tend to fail. They explored possible fixes and built more robust multi-agent systems that, for instance, improved Google’s own processing infrastructure.
Key insight: Multi-agent systems often are modeled after human organizations, so their failure modes can mirror those of human organizations. For instance, people in organizations may fail to seek clarification for tasks they don’t understand well. AI builders can address similar issues among agents by, say, forcing them to ask for clarification if their confidence falls below a threshold. Other strategies include strengthening verification that an agent completed its task, standardizing protocols for inter-agent communication, and improving descriptions of agents’ roles.
How it works: The authors fed queries from existing software-engineering and math-problem datasets to open-source, multi-agent frameworks including AG2 (disclosure: Andrew Ng has a personal investment in AG2) and ChatDev, using GPT-4o as the LLM component. They collected all model and tool outputs for more than 150 failed attempts. Annotators classified failures of agent interaction, enabling the authors to build a taxonomy of multi-agent failure modes and revise the frameworks to address general categories of weakness.
- The authors divided multi-agent system failures into three categories: poor specifications (including 5 subcategories such as agents losing track of their assigned roles and losing conversation history), inter-agent misalignment (6 subcategories that describe failures in coordination and communication such as withholding information or failing to ask for clarification), and poor task verification (3 subcategories such as ending a task without making sure the goal was achieved).
- The authors modified AG2 and ChatDev. They improved prompts (for instance, adding a verification section that read, “Before presenting your final answer, please complete the following steps: …”) and redesigned the multi-agent structure (for example, reconfiguring agents’ roles from the duo of student and assistant to the trio of problem solver, coder, and verifier).
Results: The authors tested versions of AG2 and ChatDev with and without their improvements. They used AG2 to solve math tasks in the GSM-Plus benchmark and ChatDev to solve programming tasks in HumanEval.
- With improved prompts, AG2 achieved 89 percent accuracy. With improved structure, it achieved 88.8 percent accuracy. Without improvements, it achieved 84.3 percent accuracy.
- ChatDev achieved 90.3 percent with better prompts and 91.5 percent accuracy with improved structure. It achieved 89.6 percent accuracy without improvements.
Why it matters: Designing robust multi-agent systems requires more than good LLMs. It demands understanding how agents interact and where their interactions can go wrong. The authors’ taxonomy points toward systemic ways to diagnose and address failures, guiding developers toward multi-agent systems that prioritize collaboration over individual agents.
We’re thinking: By design, the author’s taxonomy doesn’t include a category for inefficient actions. For instance, one multi-agent system made 10 separate tool calls to retrieve 10 songs from Spotify, rather than retrieving all 10 songs at once. It’s a good bet that multi-agent systems will continue to improve.