
Open-Weights Coding Leader: MiniMax-M2’s lightweight footprint and low costs belie that its top performance
An open-weights model from Shanghai-based MiniMax challenges top proprietary models on key benchmarks for coding and agentic tasks.
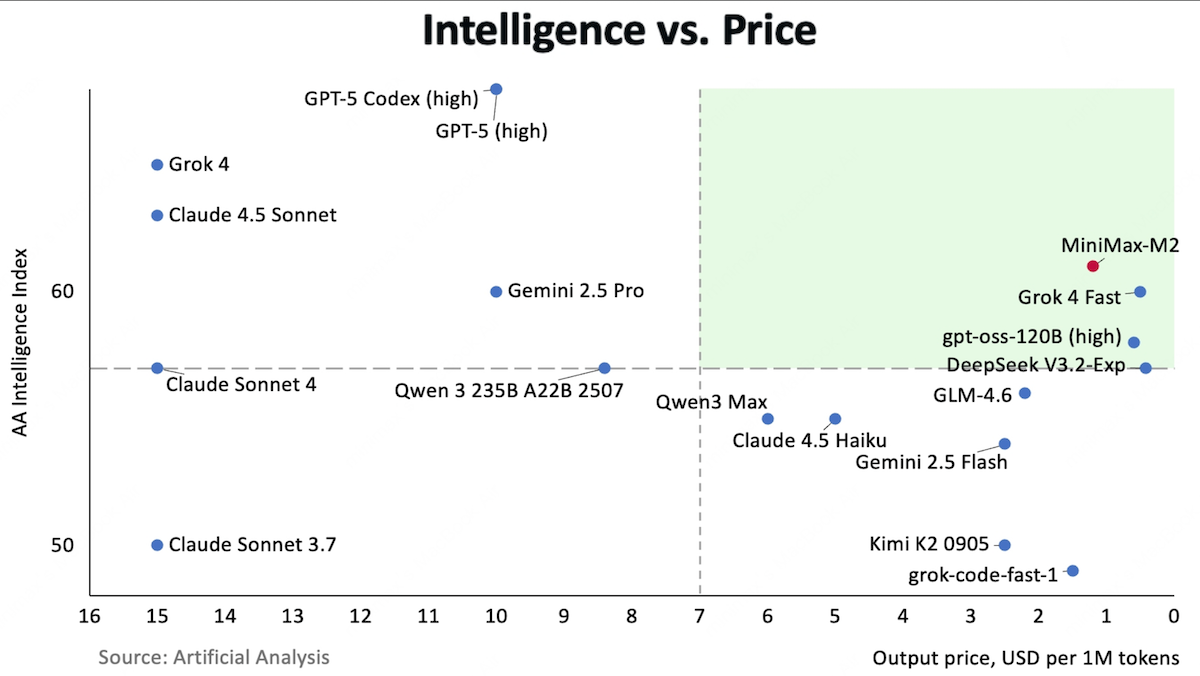
An open-weights model from Shanghai-based MiniMax challenges top proprietary models on key benchmarks for coding and agentic tasks.
What’s new: MiniMax, which provides voice-chat and image-generation services, released the weights for MiniMax-M2, a large language model that’s optimized for coding and agentic tasks.
- Input/output: Text in (up to 204,000 tokens), text out (up to 131,000 tokens, roughly 100 tokens per second)
- Architecture: Mixture-of-experts transformer, 230 billion parameters total, 10 billion parameters active per token
- Performance: First among open weights models on Artificial Analysis’ Intelligence Index
- Availability: Weights free to download from Hugging Face and ModelScope for commercial and noncommercial uses under MIT license, API $0.30/$1.20 per million input/output tokens via MiniMax
- Undisclosed: Training data, specific training methods
How it works: MiniMax has not published a technical report on MiniMax-M2, so little public information is available about how it built the model.
- Given a prompt, MiniMax-M2 interleaves reasoning steps (enclosed within <think>...</think> tags) within its output. This differs from models like DeepSeek-R1 that generate a block of reasoning steps prior to final output. It also differs from models like OpenAI GPT-5 and recent Anthropic Claude models that also generate reasoning steps prior to final output but hide or summarize them.
- MiniMax advises users to retain <think>...</think> tags in their conversation histories for optimal performance across multiple turns, because removing them (say, to economize on tokens) would degrade the model’s context.
Results: MiniMax-M2 achieved 61 on independent evaluator Artificial Analysis’ Intelligence Index (a weighted average of benchmark performance in mathematics, science, reasoning, and coding), a new high for open weights models, ahead of DeepSeek-V3.2 (57 points) and Kimi K2 (50 points). It trails proprietary models GPT-5 with thinking enabled (69 points) and Claude Sonnet 4.5 (63 points). Beyond that, it excelled in coding and agentic tasks but proved notably verbose. It consumed 120 million tokens to complete Artificial Analysis evaluations, tied for highest with Grok 4.
- On τ2-Bench, a test of agentic tool use, MiniMax-M2 (77.2 percent) ranked ahead of GLM-4.6 (75.9 percent) and Kimi K2 (70.3 percent) but behind Claude Sonnet 4.5 (84.7 percent) and GPT-5 with thinking enabled (80.1 percent).
- On IFBench, which tests the ability to follow instructions, MiniMax-M2 (72 percent) significantly outperformed Claude Sonnet 4.5 (57 percent) but narrowly trailed GPT-5 with thinking enabled (73 percent).
- On SWE-bench Verified, which evaluates software engineering tasks that require multi-file edits and test validation, MiniMax-M2 (69.4 percent) ranked in the middle tier ahead of Gemini 2.5 Pro (63.8 percent) and DeepSeek-V3.2 (67.8 percent) but behind Claude Sonnet 4.5 (77.2 percent) and GPT-5 with thinking enabled (74.9 percent).
- On Terminal-Bench, which measures command-line task execution, MiniMax-M2 (46.3 percent) ranked second only to Claude Sonnet 4.5 (50 percent), significantly ahead of Kimi K2 (44.5 percent), GPT-5 with thinking enabled (43.8 percent), and DeepSeek-V3.2 (37.7 percent).
Behind the news: In June, MiniMax published weights for MiniMax-M1, a reasoning model designed to support agentic workflows over long contexts (1 million tokens). The company had been developing agents for internal use in tasks like coding, processing user feedback, and screening resumes. However, it found that leading closed-weights models were too costly and slow, while open-weights alternatives were less capable. It says it built MiniMax-M2 to fill the gap.
Why it matters: Developing reliable agentic applications requires experimenting with combinations and permutations of prompts, tools, and task decompositions, which generates lots of tokens. Cost-effective models that are capable of agentic tasks, like MiniMax-M2, can help more small teams innovate with agents.
We’re thinking: MiniMax-M2’s visible reasoning traces make its decisions more auditable than models that hide or summarize their reasoning steps. As agents are applied increasingly to mission-critical applications, transparency in reasoning may matter as much as raw performance.



