Open-Source Speed Demon: Nvidia’s open Nemotron 3 Super 120B-A12B model sets new paces in its class
Nvidia, the dominant supplier of AI chips, released a competitive open-source large language model whose speed tops its size class — the first open-weights leader to come from the United States since last year, when Meta delivered Llama 4.
Nvidia, the dominant supplier of AI chips, released a competitive open-source large language model whose speed tops its size class — the first open-weights leader to come from the United States since last year, when Meta delivered Llama 4.
What’s new: Nvidia released Nemotron 3 Super 120B-A12B, a large language model designed for agentic applications, including not only weights but also training datasets and recipes. It is the second in a planned family of three: Nvidia released Nemotron 3 Nano-39B-A3B in December 2025, and Nemotron 3 Ultra-500B-A50B is forthcoming.
- Input/output: Text in (up to 1 million tokens), text out (up to 1 million tokens)
- Knowledge cutoff: June 2025 (pretraining data), February 2026 (fine-tuning data)
- Architecture: Hybrid mamba-2/transformer/mixture-of-experts with multi-token prediction layers (120 billion parameters, 12 billion active per token)
- Training data: 25 trillion tokens of curated data scraped from the web and synthesized in 20 natural languages and 43 programming languages
- Features: Tool calling, structured outputs, seven languages (Chinese, English, French, German, Italian, Japanese, Spanish), reasoning modes (off, low, regular)
- Performance: Fastest open-weights model of its size (442 output tokens per second), leads open-weights models on PinchBench test of agentic tasks
- Availability/price: Weights and datasets free to download under a license that permits noncommercial and commercial uses (rights terminate if safety guardrails are removed without replacement or if the user files patent or copyright litigation against Nvidia), free chat via Nvidia and OpenRouter, API around $0.30/$0.80 per 1 million tokens of input/output via third-party providers
How it works: Nemotron 3 Super’s hybrid architecture interleaves mamba-2, attention, and modified MoE layers with multi-token prediction heads that generate a number of tokens per forward pass.
- Most of Nemotron 3 Super’s layers are mamba-2 layers. Unlike attention layers, which consume quadratically more processing power as input length increases, mamba-2 layers compress earlier context into a compact representation at each step. Nemotron 3 Super interleaves attention layers selectively to handle tasks that require precise retrieval from distant parts of an input, which mamba-2 layers struggle with.
- The MoE layers use Nvidia’s LatentMoE design that compresses each token's representation to 1/4 its usual size before the MoE router decides which experts to activate. This compression enables the model to actiate 22 experts per token using roughly the same amount of processing power as five or six experts typically would require.
- Multi-token prediction (MTP) heads predict multiple output tokens per forward pass. During training, this encourages the model to learn longer-range patterns. During inference, the MTP heads accelerate output by drafting tokens that the model verifies in a single pass. It keeps those that are consistent with its probability distributions and discards the rest.
- The team pretrained in NVFP4, the 4-bit floating-point numerical format that’s built into Nvidia Blackwell GPU architecture, so the model learned to work with reduced precision rather than being quantized after training.
- The team fine-tuned the model on more than 7 million sequences that comprised a prompt, reasoning, tool calls, and final output. The sequences were generated by DeepSeek V3.2 and Kimi K2 for some tasks, including math, code, and multilingual queries, and by Qwen3-Coder-480B for software engineering tasks. Reinforcement learning followed in three stages: tasks with objectively verifiable outputs in domains such as math, coding, science, puzzles, and agentic tool use; a dedicated software engineering stage in which the model solved GitHub issues using test execution as a reward signal; and reinforcement learning from human feedback to improve conversational quality. The team described its PivotRL fine-tuning approach in a paper.
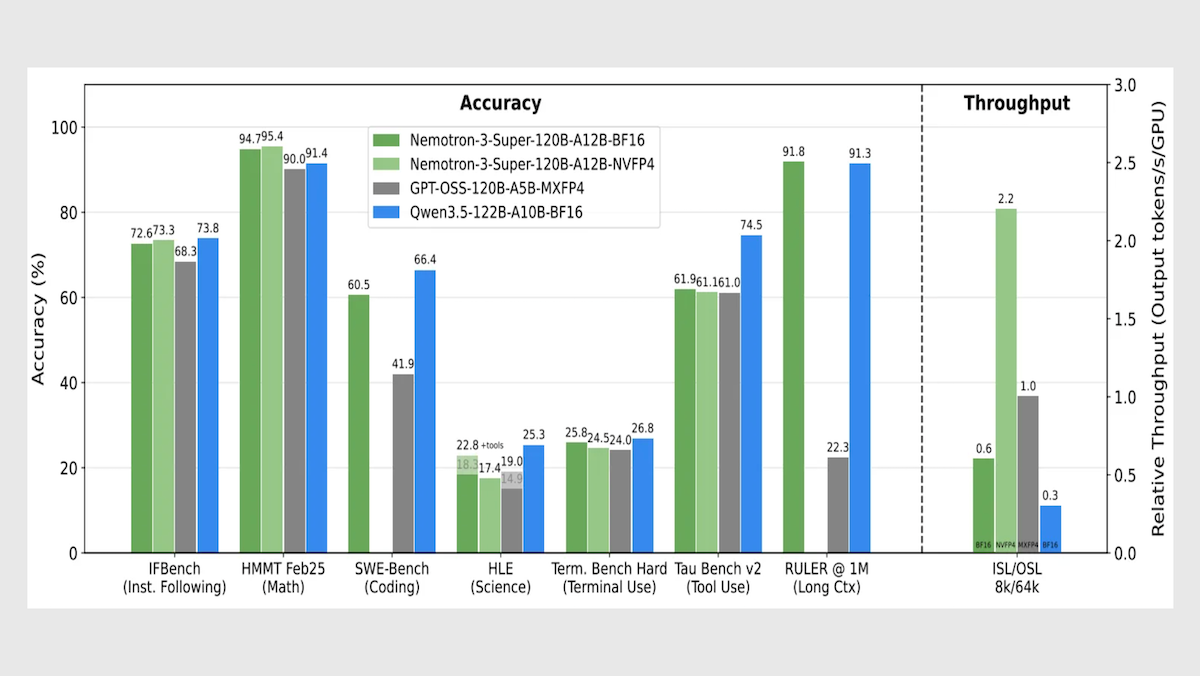
Performance: Nemotron 3 Super leads its size class in speed and processing long contexts, with competitive metrics in overall intelligence and agentic tasks.
- Nemotron 3 Super set to reasoning (level unspecified) generates roughly 442 tokens per second, well ahead of OpenAI gpt-oss-120b set to high reasoning (278 tokens per second) and Google Gemini 3.1 Flash-Lite set to reasoning (266 tokens per second).
- On Artificial Analysis’ Intelligence Index, a weighted average of 10 benchmarks that focus on economically useful work, Nemotron 3 Super set to reasoning (36) fell behind Qwen3.5-122B set to reasoning (42) but outperformed gpt-oss-120b set to high reasoning (33).
- On RULER, a long-context evaluation developed by Nvidia, given 1 million input tokens, Nemotron 3 Super (91.75 percent accuracy) slightly outperformed Qwen3.5-122B (91.33 percent accuracy) and came out well ahead of gpt-oss-120b (22.30 percent a accuracy).
- On PinchBench, which evaluates how well a model completes tasks as the decision-making core of an autonomous agent (OpenClaw), Nemotron 3 Super (85.6 percent) outperformed much larger open-weights contenders including the 1 trillion-parameter Kimi K2.5 (84.8 percent) and the 744 billion-parameter GLM-5 (84.1 percent), as well as the similarly sized Qwen3.5-122B (84.5 percent).
Behind the news: Nvidia plans to invest $26 billion over five years to develop open-weights models — a substantial commitment. The announcement coincides with shifts in the open-weights landscape that could affect Nvidia’s business. Chinese companies, including Alibaba, Moonshot AI, and Z.ai, lately have built the most capable open-weights models, and they are building alternatives to Nvidia GPUs and Cuda software. For instance, DeepSeek has reportedly trained an upcoming model entirely on Huawei’s Ascend chips and Cann software.
Why it matters: Nemotron 3 Super gives developers a fast, fully open model for agentic applications, with training data, recipes, and tools alongside the weights. This openness also serves Nvidia’s business goals. Chinese open-weights models are growing more capable and increasingly streamlined to run on non-Nvidia chips, creating a risk that developers who previously relied on Nvidia will look elsewhere. Nemotron gives them a reason not to.
We’re thinking: Who better to optimize a model for GPUs than the company that designs the GPUs? From custom numerical formats to inference software, Nvidia can co-design hardware and software in ways that few model developers can match. Nvidia is betting that building models will help sell chips and vice versa.