Nvidia’s enterprise-focused NemoClaw gives OpenClaw a security boost: Claude Dispatch lets paid users authorize remote work
GPT-5.4 Mini and Nano, optimized for speed. Nvidia’s own tiny-sized open-weights model. Midjourney updates to v8 in Alpha. Mamba releases third version of its state space language model.

Welcome back! In today’s edition of Data Points, you’ll learn more about:
- GPT-5.4 Mini and Nano, optimized for speed
- Nvidia’s own tiny-sized open-weights model
- Midjourney updates to v8 in Alpha
- Mamba releases third version of its state space language model
But first:
Nvidia embraces OpenClaw (but adds a security wrapper)
Nvidia unveiled NemoClaw at GTC 2026, an enterprise-focused software stack that integrates with OpenClaw to add security, governance, and scalability for production environments. The stack includes Nvidia Nemotron open models that run locally on dedicated hardware, and OpenShell, an open-source security runtime that isolates each agent in a configurable sandbox with YAML-defined policies controlling file access, network connections, and API calls. The system uses a privacy router architecture that keeps sensitive data local while routing queries requiring higher capability to frontier cloud models only when needed. Launch partners include Box, Cisco, Atlassian, Salesforce, SAP, and CrowdStrike, with integrations already demonstrating use cases like automated security incident response and contract lifecycle management. The architecture lets organizations deploy “claws” (autonomous agents that can plan, execute multi-step tasks, and run continuously without human input) while maintaining audit trails and enforcing the same permissions models that govern human employees. (VentureBeat)
Claude Cowork Dispatch, an OpenClaw-like remote work feature
Anthropic introduced a research preview feature in Cowork that maintains a single continuous conversation with Claude on both desktop and mobile. Users can assign tasks from their phone (including reading local spreadsheets, searching email and Slack, or organizing files), and Claude executes them on the desktop computer using configured connectors, plugins, and file access, then messages back the results. The feature requires the latest Claude Desktop app (macOS or Windows) and Claude mobile app, both kept active with an internet connection, and is available to Max and Pro subscribers. (Anthropic)
GPT-5.4’s smaller, speedier models in the family
OpenAI released GPT-5.4 mini and nano, smaller variants of its flagship GPT-5.4 model optimized for speed-sensitive applications. GPT-5.4 mini runs more than twice as fast as GPT-5 mini while approaching GPT-5.4 performance on benchmarks like SWE-Bench Pro (54.4 percent) and OSWorld-Verified (72.1 percent). It supports coding, reasoning, multimodal understanding, tool use, and computer-based automation tasks with a 400k context window at $0.75 per million input tokens and $4.50 per million output tokens. GPT-5.4 nano is the most cost-effective option at $0.20 per million input tokens and $1.25 per million output tokens, designed for simpler classification, data extraction, and supporting subagent tasks. Both models are immediately available through the API, Codex IDE, and ChatGPT. The mini variant uses only 30 percent of GPT-5.4’s quota in Codex, enabling developers to handle routine tasks at roughly one-third the cost while maintaining strong performance. GPT-5.4’s pricing and performance structure gives developers incentives to build distributed architectures where larger models coordinate and smaller models execute specialized subtasks. (OpenAI)
Nvidia’s hybrid on-device Nemotron 3 Nano 4B
Nvidia released Nemotron 3 Nano 4B, a 4 billion parameter model designed for on-device inference. The model uses a hybrid Mamba-Transformer architecture and achieves state-of-the-art (in its size class) instruction following, tool use, and gaming agency performance while maintaining the lowest VRAM footprint and latency. The model was created by pruning and distilling Nvidia’s larger Nemotron Nano 9B v2 using the Nemotron Elastic framework, which uses a router to determine optimal pruning decisions across depth, Mamba heads, FFN channels, and hidden dimensions simultaneously, instead of requiring separate compression stages. Nvidia released the model in three quantized formats: BF16 for maximum accuracy, FP8 using selective quantization that achieves one point eight times latency improvement, and GGUF Q4_K_M for Llama.cpp compatibility. (Hugging Face)
Midjourney’s new version sticks with diffusion for thick and thin
Midjourney released an early version of V8 for community testing, delivering roughly five times faster image generation and a new high definition mode that renders natively at 2K resolution. The model follows detailed instructions more accurately than its predecessor, produces more coherent images, and handles in-image text more reliably when text is wrapped in quotation marks. However, V8 remains a pure diffusion-based model and struggles with complex, abstract prompts where competitors using hybrid autoregressive architectures excel, a gap that early testing suggests hasn’t fully closed. Premium features like high definition, improved image coherence, style references, and mood boards cost four times as much as standard generation, and Midjourney’s popular Relax mode is unavailable at launch. As competitors adopt mixed architectures for better prompt control, Midjourney’s diffusion-only approach risks becoming a harder sell for production workflows requiring precise prompt adherence. (Midjourney and The Decoder)
Mamba update slithers ahead with improved speed and accuracy
Researchers at Carnegie Mellon, Together.AI, and other institutions introduced Mamba-3, an updated version of the state space language model. At 1.5 billion parameters, Mamba-3 MIMO improves downstream accuracy by 1.8 percentage points over Gated DeltaNet and 1.9 points over Mamba-2 while matching Mamba-2’s perplexity using only half the state size (64 versus 128). The MIMO variant increases decoding FLOPs by up to four times relative to Mamba-2 at fixed state size while maintaining similar latency. Mamba’s innovations have begun to be widely used in hybrid architectures like Nvidia’s Nemotron, and the updated model is likely to see similar adoption. (arXiv)
Still want to know more about what matters in AI right now?
Read the latest issue of The Batch for in-depth analysis of news and research.
Last week, Andrew Ng talked about the introduction of the Context Hub (chub) to offer current API documentation to coding agents, the idea of a Stack Overflow-style platform for AI agents to exchange feedback, and the swift expansion of Moltbook, a social network for agents.
“Social sharing isn’t only for humans. It’s also for agents! As we navigate ways for many agents to learn from each other — being careful to provide strong safeguards for privacy and security — we will make both AI agents and the humans they serve better off.”
Read Andrew’s letter here.
Other top AI news and research stories covered in depth:
- OpenAI’s GPT-5.4 Pro and GPT-5.4 Thinking challenged Google’s Gemini 3.1 Pro Preview as the best all-around AI model, boasting higher performance at a higher price.
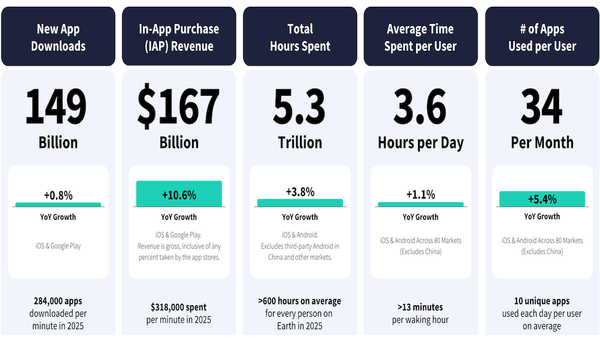
- The State of Mobile 2026 Report revealed that AI chatbot, search, and assistant growth was skyrocketing, outpacing traditional mobile sectors like gaming and social media.
- AI companies are building their own power plants to create data centers that operate off the grid, reducing reliance on public utilities.
- Researchers introduced the Feature Auto-Encoder, a diffusion image generator that shrunk embeddings for faster processing and enabled lightning-fast diffusion learning.
Attention!
A special event for our community
Andrew Ng and DeepLearning.AI are hosting AI Dev 26 × San Francisco, a two-day conference for AI developers taking place April 28–29 at Pier 48.
Join 3,000+ engineers, researchers, and builders working on modern AI systems.
The program includes top speakers, developer relations experts, and engineers from companies including Google, AMD, Oracle, Neo4j, and Snowflake (and of course DeepLearning.AI), all sharing their latest technologies and explaining how they’re building and deploying AI systems today.
At AI Dev 26, you’ll find:
- Technical talks from engineers building AI systems in production
- Hands-on workshops exploring new tools and techniques
- Live demos from startups and AI builders
- Opportunities to meet other developers and companies in the space
Get your ticket with a special discount!
Data Points is produced by human editors with AI assistance.