
Born To Be Agentic: Moonshot releases Kimi K2, a trillion-parameter model fine-tuned for agentic tool use
An agent’s performance depends not only on an effective workflow but also on a large language model that excels at agentic activities. A new open-weights model focuses on those capabilities.
An agent’s performance depends not only on an effective workflow but also on a large language model that excels at agentic activities. A new open-weights model focuses on those capabilities.
What’s new: Beijing-based Moonshot AI released the Kimi K2 family of 1 trillion-parameter large language models (LLMs). The family includes the pretrained Kimi-K2-Base and Kimi-K2-Instruct, which is fine-tuned for core agentic tasks, notably tool use. Bucking the recent trend in LLMs, Kimi K2 models are not trained for chain-of-thought reasoning.
- Input/output: Text in (up to around 128,000 tokens), text out (up to around 16,000 tokens)
- Architecture: Mixture-of-experts transformer, 1 trillion parameters total, 32 billion parameters active
- Performance: Outperforms other open-weights, non-reasoning models in tool use, coding, math, and general-knowledge benchmarks
- Availability: Web interface (free), API ($0.60/$0.15/$2.50 per million input/cached/output tokens), weights available for non-commercial and commercial uses up to 100 million monthly active users or monthly revenue of $20,000,000 under “modified MIT license”
- Features: Tool use including web search and arbitrary tools
- Undisclosed: Specific training methods, training datasets
How it works: Moonshot pretrained the models on 15.5 trillion tokens from undisclosed sources. It fine-tuned Kimi-K2-Instruct via reinforcement learning using a proprietary dataset.
- To enable Kimi-K2-Instruct to use tools, the team generated a large dataset of examples in which models used tools, both real-world and synthetic, that implement model context protocol (MCP). Unidentified models acted as users, and other unidentified models acted as agents that solved tasks assigned by the users. A further model acted as a judge to filter out unsuccessful examples.
- The team fine-tuned Kimi-K2-Instruct via reinforcement learning. The model evaluated its own performance, used its evaluation as a reward, and iteratively improved its performance.
- The team also fine-tuned Kimi-K2-Instruct to solve coding and math problems via reinforcement learning. The model did not evaluate its own performance on these problems; it determined rewards according to pre-existing solutions or unit tests.
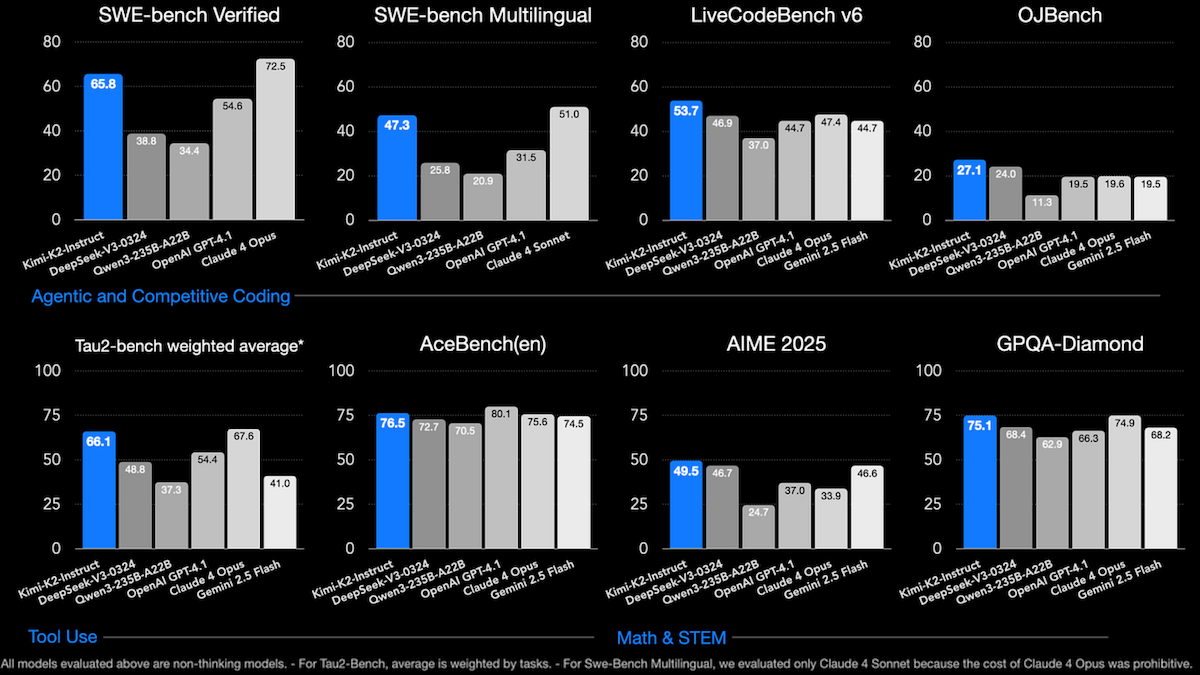
Results: Moonshot compared Kimi-K2-Instruct to two open-weights, non-reasoning models (DeepSeek-V3 and Qwen3-235B-A22B with reasoning switched off) and four closed, non-reasoning models.
- Kimi-K2-Instruct outperformed the open-weights models across a range of benchmarks for tool use, coding, math, reasoning, and general knowledge.
- It achieved middling performance relative to the closed models, though it did relatively well in math and science tasks.
- Compared to all models tested, on LiveCodeBench (coding tasks), Kimi K2 (53 percent) achieved the best performance, ahead of Claude Sonnet 4 with extended thinking mode switched off (48.5 percent).
- Among all models tested, on AceBench (tool use), Kimi K2 (76.5 percent accuracy) placed second behind GPT 4.1 (80.1 percent accuracy).
- On 8 out of 11 math and science benchmarks, Kimi K2 achieved the best performance of all models tested.
Behind the news: Third-party vendors have been quick to implement Kimi-K2-Instruct.
- The Groq platform accelerates Kimi-K2-Instruct’s output to about 200 tokens per second ($1/$3 per million input/output tokens) compared to 45 tokens per second reported by Artificial Analysis.
- The fine-tuning platform Unsloth released quantized versions that run on local devices that have 250 gigabytes of combined hard-disk capacity, RAM, and VRAM.
Why it matters: Demand is growing for LLMs that carry out agentic workflows accurately, as these workflows lead to better performance. Kimi-K2-Instruct gives developers a strong option for fine-tuning models for their own agentic tasks.
We’re thinking: Early LLMs were built to generate output for human consumption. But the rise of agentic workflows means that more and more LLM output is consumed by computers, so it makes good sense to put more research and training effort into building LLMs that generate output for computers. A leading LLM optimized for agentic workflows is a boon to developers!



