
Cybersecurity for Agents: Meta releases LlamaFirewall, an open-source defense against AI hijacking
Autonomous agents built on large language models introduce distinct security concerns. Researchers designed a system to protect agents from common vulnerabilities.
Autonomous agents built on large language models introduce distinct security concerns. Researchers designed a system to protect agents from common vulnerabilities.
What’s new: Sahana Chennabasappa and colleagues at Meta released LlamaFirewall, an open-source system designed to mitigate three lines of attack: (i) jailbreaking (prompts that bypass an LLM’s built-in safeguards), (ii) goal hijacking (inputs that aim to change an LLM’s prompted goal), and (iii) exploiting vulnerabilities in generated code. The code and models are freely available for projects that have up to 700 million monthly active users.
Key insight: Security for LLMs typically focuses on filtering inputs and fine-tuning outputs. But agentic LLMs retain vulnerabilities that aren’t addressed by those techniques and present new ones as well. Receiving instructions exposes them to jailbreaking, tool use makes them vulnerable to goal hijacking (for instance, when an agent conducts a web search and encounters malicious data), and output code may open security holes outside the agent itself. To defend against these weaknesses, a security system can filter malicious prompts, monitor chains of thought for deviations from prompted goals, and check generated code for flaws.
How it works: LlamaFirewall integrates three modules:
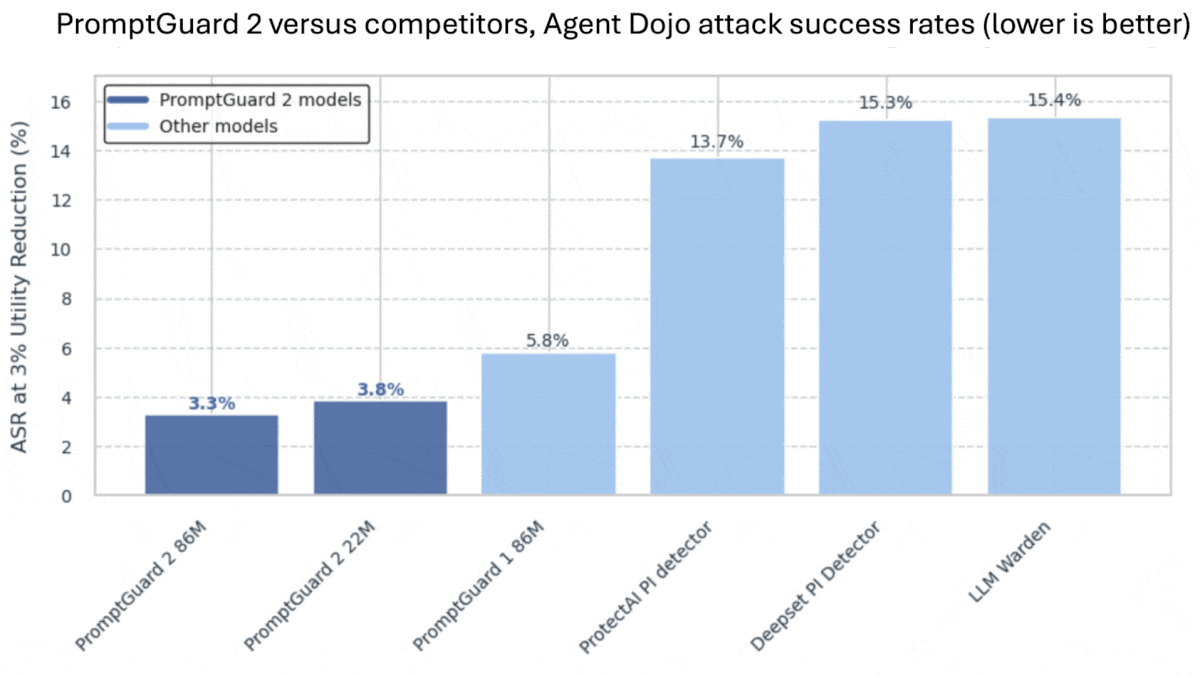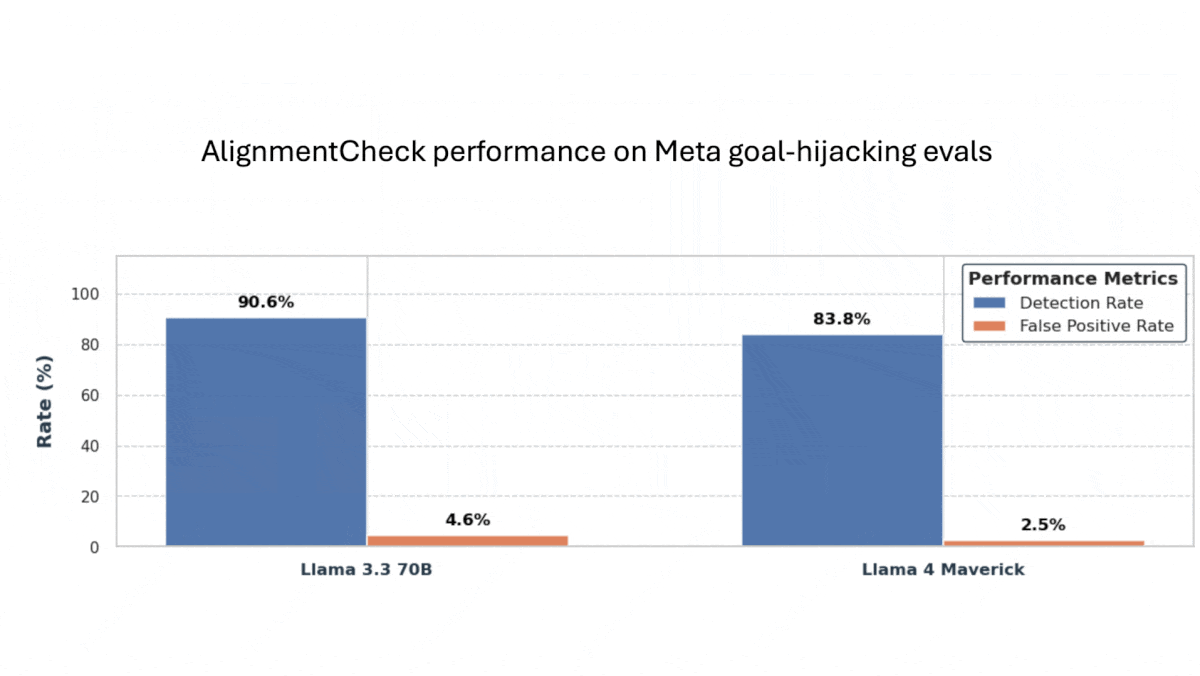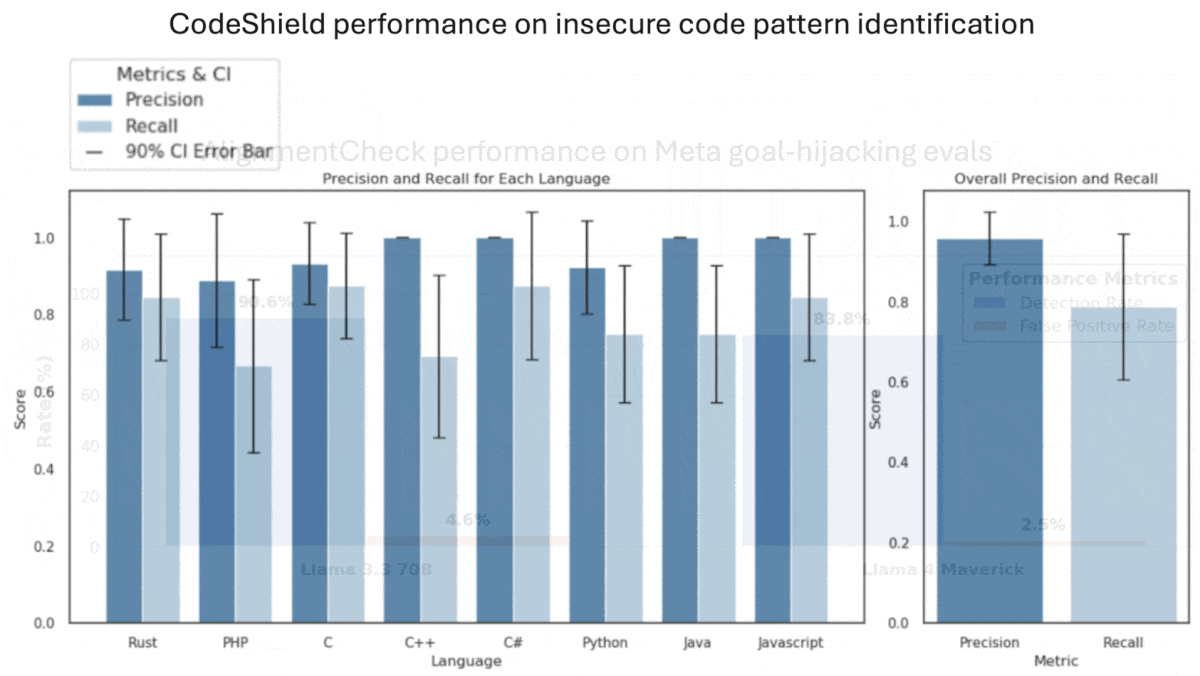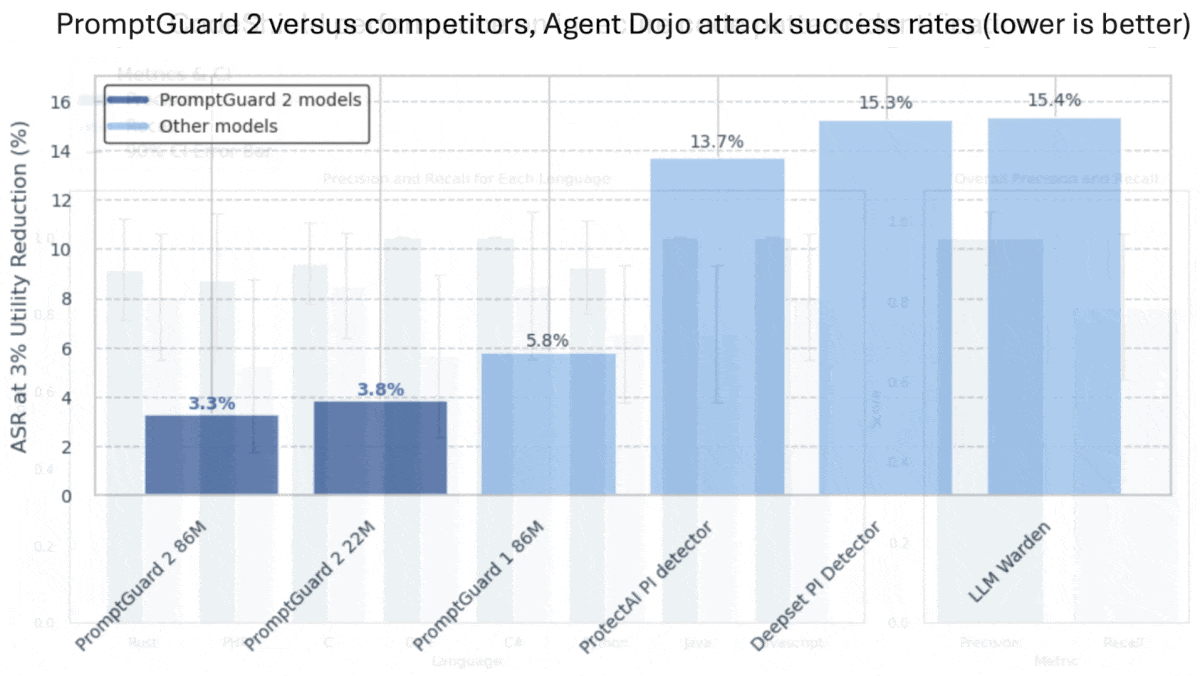
- PromptGuard 2: To block malicious inputs, DeBERTa, an 86 million parameter transformer fine-tuned to classify prompts as benign or malicious, classifies incoming text from users or external tools.
- AlignmentCheck: To detect goal hijacking, Llama 4 Maverick compares chains of thought, tool calls, and output with the user’s objective as stated in the initial prompt. If the generated text or tool calls drift away from the user’s intended objective, LlamaFirewall stops the generation.
- CodeShield: To check generated code for flaws, this module uses rules to detect insecure patterns in generated code, such as vulnerability to SQL injections (like "SELECT * FROM users WHERE email LIKE '" + domain + "'", which allows SQL injections through the unsanitized input parameter “domain”). It prevents insecure code from being passed to users until the agent fixes the code and it passes review.
Results: The authors evaluated LlamaFirewall using AgentDojo, an environment that evaluates attacks against 10 agents (10 different LLMs coupled with the authors’ agentic framework).
- With LlamaFirewall, attacks were successful 1.7 percent of the time. Without it, they succeeded 17.6 percent of the time.
- AlignmentCheck detected 83 percent of attacks in a proprietary dataset with a false-positive rate of 2.5 percent.
- The authors tuned PromptGuard 2’s classification threshold to achieve a false-positive rate of 1 percent. At this rate, PromptGuard 2 detected 97.5 percent of attacks in a proprietary dataset.
- The authors also compared the performance of PromptGuard 2 to competing prompt classifiers using AgentDojo. With PromptGuard 2, 3.3 percent of jailbreak attempts were successful. Using the next-best competitor, ProtectAI, 13.7 percent succeeded.
Why it matters: The rise of agentic systems is opening new vectors of cyberattack, and security risks are likely to rise as agents operate with greater autonomy and perform more critical tasks. LlamaFirewall addresses a wide range of potential security issues in an open-source tool kit.
We’re thinking: This work is a helpful reminder that, while generative LLMs are all the rage, BERT-style classifiers remain useful when an application needs to classify text quickly.



