
Llama’s Mixture of Vision-Language Experts: Meta releases Llama 4 models, claims edge over AI competitors
Meta updated its popular open-weights models, claiming performance superior to closed competitors in three size classes.
Meta updated its popular open-weights models, claiming performance superior to closed competitors in three size classes.
What’s new: Meta released two vision-language models in the Llama 4 family (Llama 4 Scout and Llama 4 Maverick) and teased a third (Llama 4 Behemoth). All three models are based on the increasingly popular mixture-of-experts (MoE) architecture, which activates only a portion of parameters during inference for more efficient processing. Llama 4 Scout boasts the industry's biggest input context window so far — 10 million tokens! — but Meta says processing 1.4 million tokens of context requires eight Nvidia H100 GPUs, and early users on Reddit reported that its effective context began to degrade at 32,000 tokens.
- Input/output: Text, image, and video in (Llama 4 Scout up to 10 million tokens, Llama 4 Maverick up to 1 million tokens). Text out (Llama 4 Scout 120.5 tokens per second, 0.39 seconds to first token; Llama 4 Maverick 124.2 tokens per second, 0.34 seconds to first token).
- Architecture: Llama 4 Scout 109 billion parameters, 17 billion parameters activated. Llama 4 Maverick 400 billion parameters, 17 billion activated. Llama 4 Behemoth nearly 2 trillion parameters, 288 billion parameters activated.
- Features: 12 officially supported languages
- Undisclosed: Distillation details, Llama 4 Behemoth details including release date
- Availability: Weights free to download under a license that allows noncommercial uses and limits commercial uses to businesses with fewer than 700 million monthly users under Meta’s terms of use
- API price: Llama 4 Scout $0.15/$0.50 per 1 million tokens input/output. Llama 4 Maverick $0.22/$0.85 per 1 million tokens input/output.
How it works: The team pretrained Llama 4 models on images and text in over 200 languages from publicly available and licensed data, including data from publicly shared posts on Facebook and Instagram. They trained Llama 4 Scout on 40 trillion tokens and Llama 4 Maverick on 22 trillion tokens.
- The team removed the 50 percent of training examples that are easiest to predict (as judged by unnamed Llama models). For Llama 4 Behemoth, they removed 95 percent of an unspecified data set.
- They fine-tuned the models using supervised learning, then reinforcement learning, then direct preference optimization.
- Llama 4 Maverick was “co-distilled” on outputs from Llama 4 Behemoth. The other teachers undisclosed.
Results: In tests performed by Meta, Llama 4 models showed strong performance relative to competing models — mostly not mixtures of experts, but some that are known to have higher parameter counts relative to Llama 4 models’ active parameters.
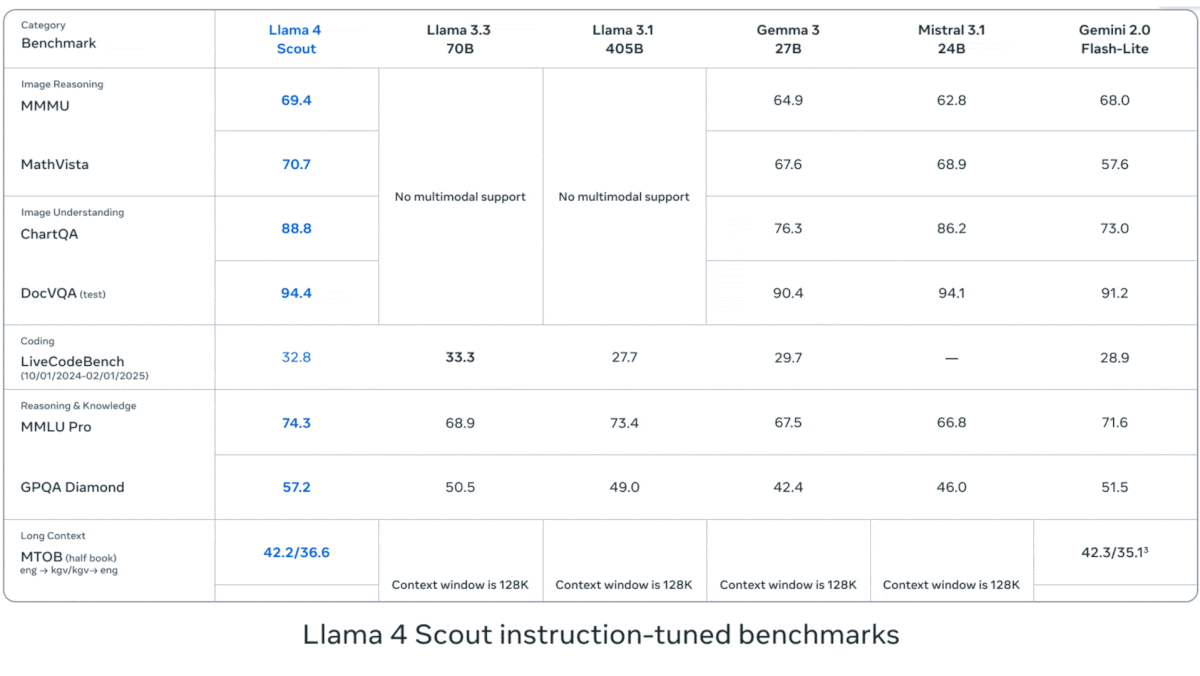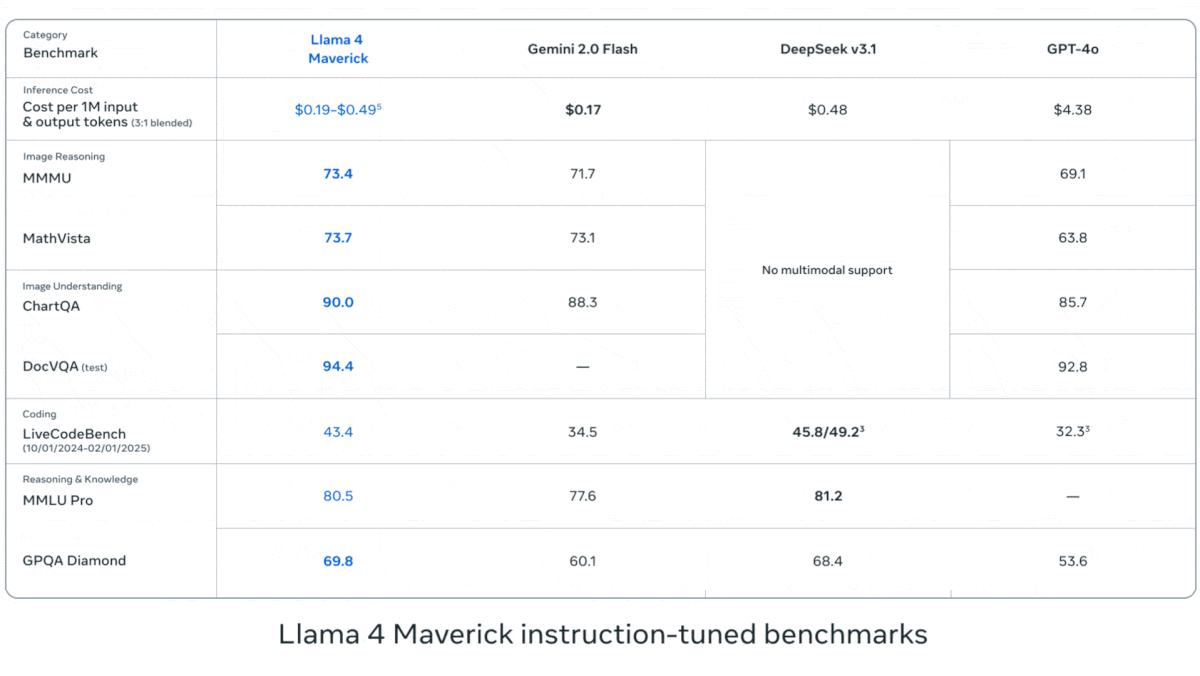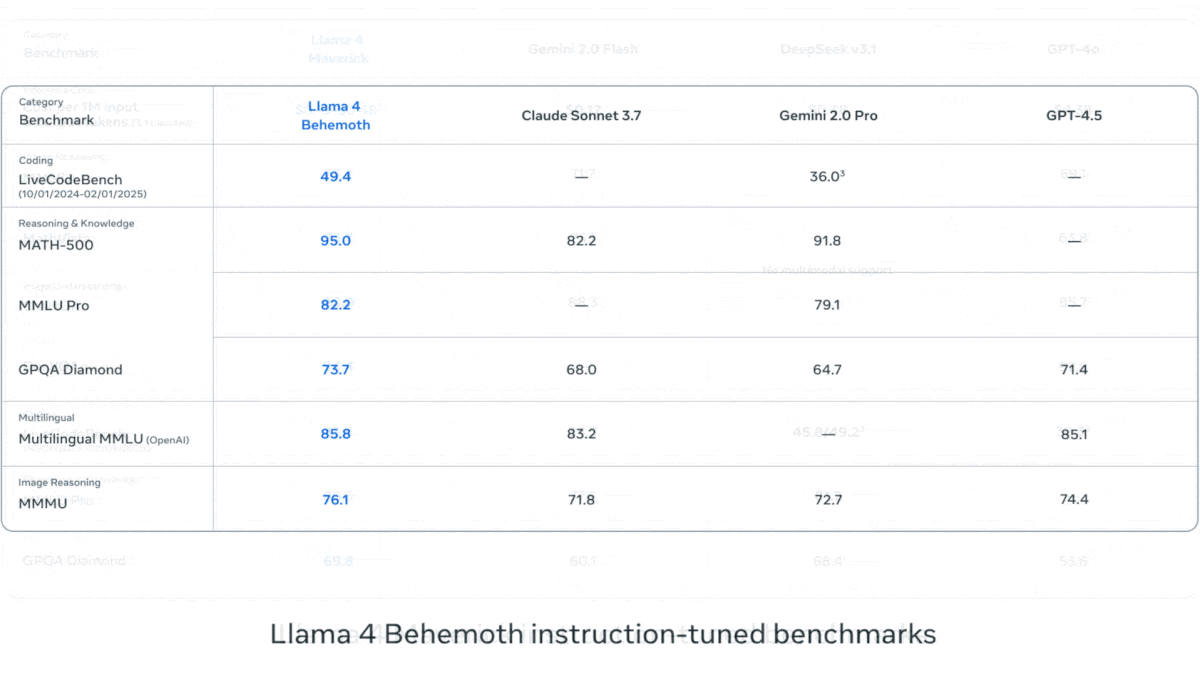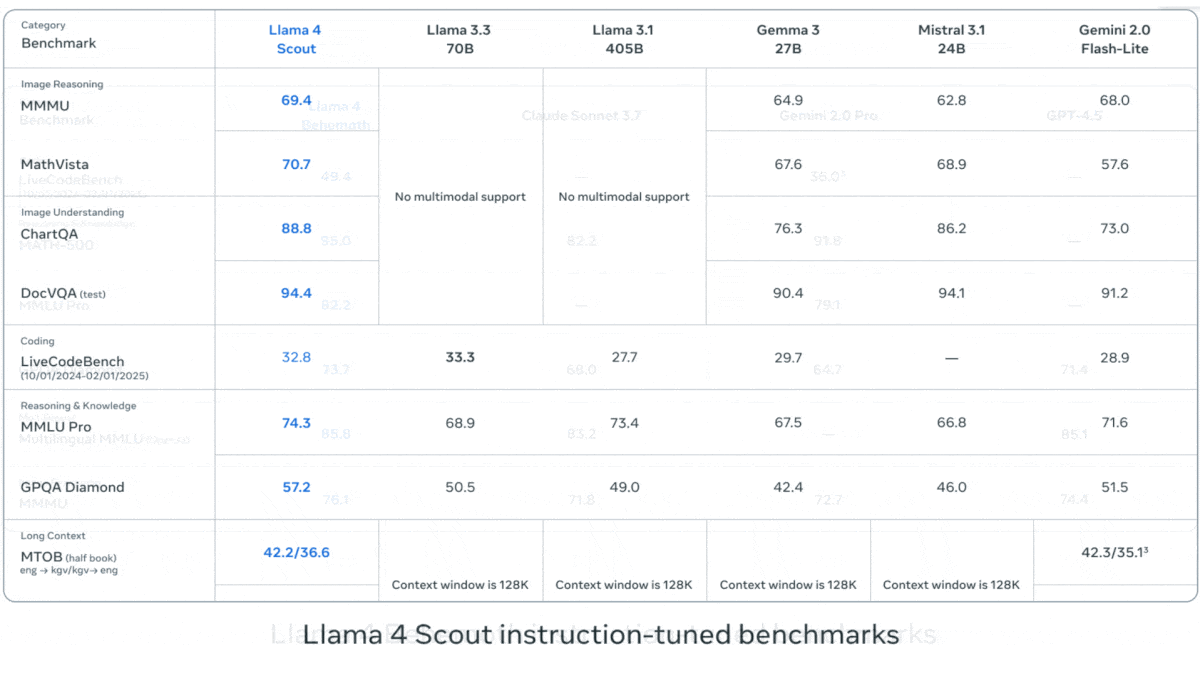
- Llama 4 Scout outperformed Google Gemma 3 27B, Mistral 3.1 24B, and Gemini 2.0 Flash-Lite on most of seven benchmarks that test vision (MMMU, Chart QA), coding (LiveCodeBench), and knowledge and reasoning tasks (MMLU Pro, GPQA Diamond).
- Llama 4 Maverick outperformed OpenAI GPT-4o and Google Gemini 2.0 Flash across the same benchmarks.
- On multiple benchmarks including tests of mathematics, coding, domain knowledge, and multimedia reasoning, an early version of Llama 4 Behemoth outperformed OpenAI GPT-4.5, Anthropic Claude 3.7 Sonnet, and Google Gemini 2.0 Pro but fell behind OpenAI o1, DeepSeek-R1, and Google Gemini 2.5 Pro. (The parameter counts of these models are undisclosed except DeepSeek-R1, a MoE model with 671 billion parameters, 37 billion of which are active at any given time.)
Yes, but: An experimental version of Llama 4 Maverick reached second place in Chatbot Arena behind Gemini 2.5 Pro. However, it was a variation optimized for conversation, not the currently available version. AI researchers accused Meta of attempting to manipulate the leaderboard.
Why it matters: Although the version of Llama 4 Maverick that nearly topped the Chatbot Arena is not the released version, its accomplishment says a lot about the growing power of open weights. Open models are quickly reaching parity with closed competitors — a boon to developers, businesses, and society at large.
We’re thinking: According to Meta, Behemoth beats GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro, topping all but the best reasoning models — but it isn’t available yet. Something to look forward to!



