
Top Agentic Results, Open Weights: Kimi K2 Thinking outperforms proprietary models with new techniques for agentic tool use
The latest open-weights large language model from Moonshot AI challenges top proprietary LLMs at agentic tasks by executing hundreds of tool calls sequentially and pausing to think between each.
The latest open-weights large language model from Moonshot AI challenges top proprietary LLMs at agentic tasks by executing hundreds of tool calls sequentially and pausing to think between each.
What’s new: Kimi K2 Thinking and the faster Kimi K2 Thinking Turbo are trillion-parameter reasoning versions of Moonshot’s earlier LLM Kimi K2. They were fine-tuned at 4-bit (INT4) precision, so they can run at lower cost and on lower-cost hardware than other LLMs of similar size.
- Input/output: Text in (up to 256,000 tokens), text out (size limit undisclosed, Kimi K2 Thinking 14 tokens per second, Kimi K2 Thinking Turbo 86 tokens per second)
- Architecture: Mixture-of-experts transformer, 1 trillion parameters total, 32 billion parameters active per token.
- Performance: Outperforms top closed LLMs in the τ²-Bench Telecom agentic benchmark, outperforms other open LLMs generally.
- Availability: Free web user interface with limited tool access, weights freely available for noncommercial and commercial uses up to 100 million monthly active users or monthly revenue of $20,000,000 under modified MIT license.
- API: Kimi K2 Thinking ($0.60/$0.15/$2.50 per million input/cached/output tokens), Kimi K2 Thinking Turbo ($1.15/$0.15/$8.00 per million input/cached/output tokens) via Moonshot AI and other vendors
- Features: Tool use including search, code interpreter, web browsing, “heavy” reasoning mode
- Undisclosed: Specific training methods and datasets, output size limit
How it works: Rather than completing all reasoning steps before acting, Kimi K2 Thinking executes cycles of reasoning and tool use. This enables it to adjust continually depending on interim reasoning steps or results of tool calls.
- Given a prompt, Kimi K2 Thinking interleaves reasoning, tool use (up to 300 calls), and planning. First it reasons about the task and then calls tools, interprets the results, plans the next step, and repeats the cycle. This investment at inference yields better results in tasks that require multiple steps. For example, the model correctly solved an advanced mathematical probability problem by alternating between 23 reasoning and tool-use steps.
- A “heavy” mode simultaneously runs 8 independent reasoning paths and combines their outputs to produce final output. This mode can improve accuracy on difficult problems at eight times the usual cost in computation.
- Moonshot fine-tuned Kimi K2 Thinking at INT4 precision (using integers encoded in 4 bits instead of 16 or 32 bits), roughly doubling output speed and reducing the model’s file size to 594 gigabytes (compared to Kimi K2 Instruct’s 1 terabyte). Kimi K2 Thinking used quantization aware training (or QAT), a technique that simulates low-precision arithmetic during fine-tuning. Training steps used low-precision math, but the weights were maintained in full precision, making later quantization more accurate.
- Kimi K2 Thinking cost $4.6 million to train, according to CNBC. That’s $1 million less than DeepSeek’s reported cost to train DeepSeek-V3.
Results: Kimi K2 Thinking leads open-weights LLMs in several benchmarks and achieves state-of-the-art results on some agentic tasks. However, it generates many more tokens than most competitors to achieve a comparable performance.
- On Artificial Analysis' Agentic Index, which measures multi-step problem-solving with tools, Kimi K2 Thinking ranked third (67 points) among LLMs tested, trailing only GPT-5 set to high reasoning and GPT-5 Codex set to high reasoning (68 points).
- On τ²-Bench Telecom, a test of agentic tool use, Kimi K2 Thinking achieved 93 percent accuracy, the highest score independently measured by Artificial Analysis and 6 percentage points ahead of the nearest contenders, GPT-5 Codex (87 percent accuracy) set to high reasoning and MiniMax-M2 (87 percent accuracy).
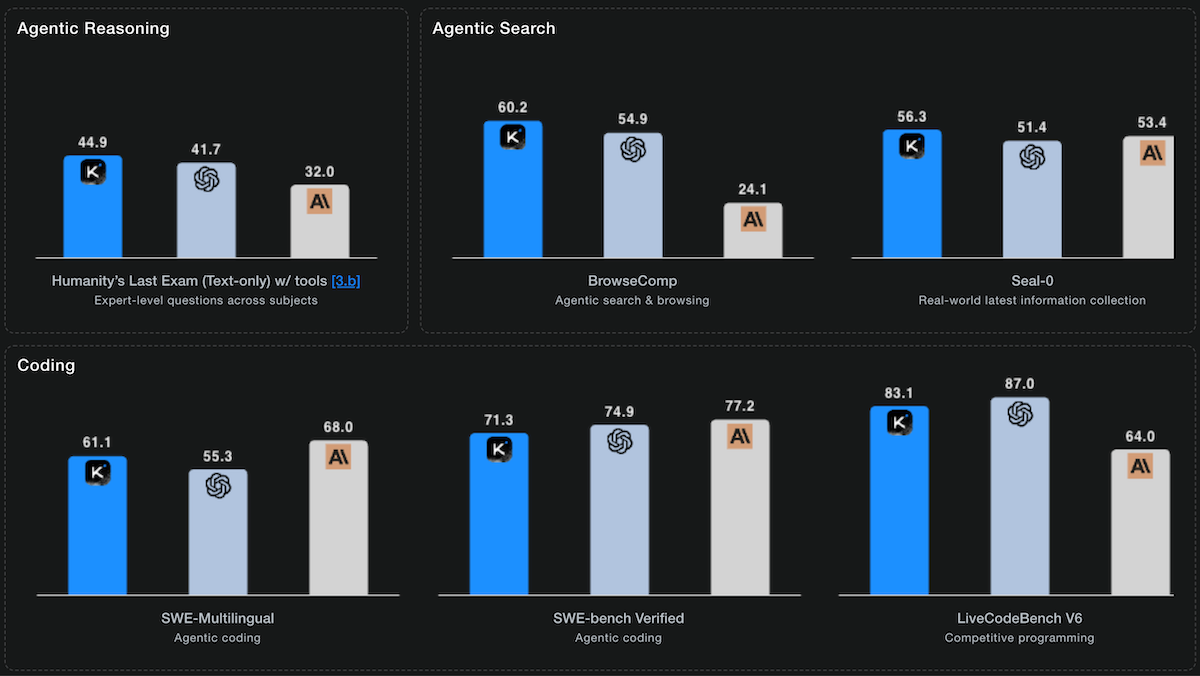
- On Humanity's Last Exam, a test of multi-domain, graduate-level reasoning, Artificial Analysis measured Kimi K2 Thinking (22.3 percent accuracy without tools) outperformed other open-weights LLMs but trailed GPT-5 set to high reasoning (26.5 percent) and Grok 4 (23.9 percent). With tools enabled, Moonshot reports the model achieved 44.9 percent, a state-of-the-art result higher than that of GPT-5 set to high reasoning (41.7 percent accuracy) and Anthropic Claude Sonnet 4.5 Thinking (32.0 percent accuracy).
- On coding benchmarks, Kimi K2 Thinking ranked first or tied for first among open-weights LLMs on Terminal-Bench Hard, SciCode, and LiveCodeBench, but trailed proprietary LLMs. On SWE-bench Verified, a test of software engineering, Moonshot reports Kimi K2 Thinking (71.3 percent accuracy) fell short of Claude Sonnet 4.5 Thinking (77.2 percent) and GPT-5 (high) (74.9 percent).
Yes, but: Kimi K2 Thinking used 140 million tokens to complete Artificial Analysis’ Intelligence Index evaluations, more than any other LLM tested, roughly 2.5 times the number used by DeepSeek-V3.2 Exp (62 million) and double that of GPT-5 Codex set to high reasoning (77 million). To run the Intelligence Index tests, Kimi K2 Thinking ($356) was around 2.5 times less expensive than GPT-5 set to high reasoning ($913), but roughly 9 times pricier than DeepSeek-V3.2 Exp ($41).
Behind the news: In July, Moonshot released the weights for Kimi K2, a non-reasoning version optimized for agentic tasks like tool use and solving problems that require multiple steps.
Why it matters: Agentic applications benefit from the ability to reason across many tool calls without human intervention. Kimi K2 Thinking is designed specifically for multi-step tasks like research, coding, and web navigation. INT4 precision enables the model to run on less expensive, more widely available chips — a boon especially in China, where access to the most advanced hardware is restricted — or at very high speeds.
We’re thinking: LLMs are getting smarter about when to think, when to grab a tool, and when to let either inform the other. According to early reports, Kimi K2 Thinking’s ability to plan and react helps in applications from science to web browsing and even creative writing — a task that reasoning models often don’t accomplish as well as their non-reasoning counterparts.



