Gemini Seizes the Lead, Investors Panic Over Agentic AI, Optimism at Global AI Summit, Local Versus Cloud
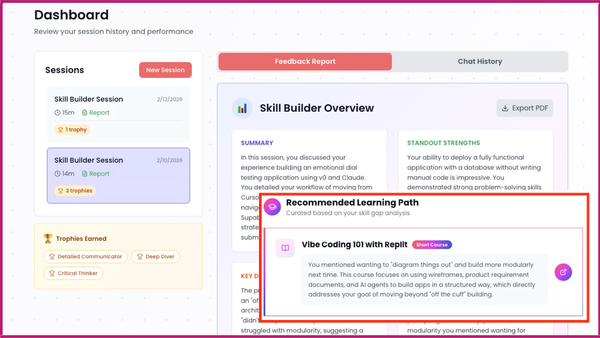
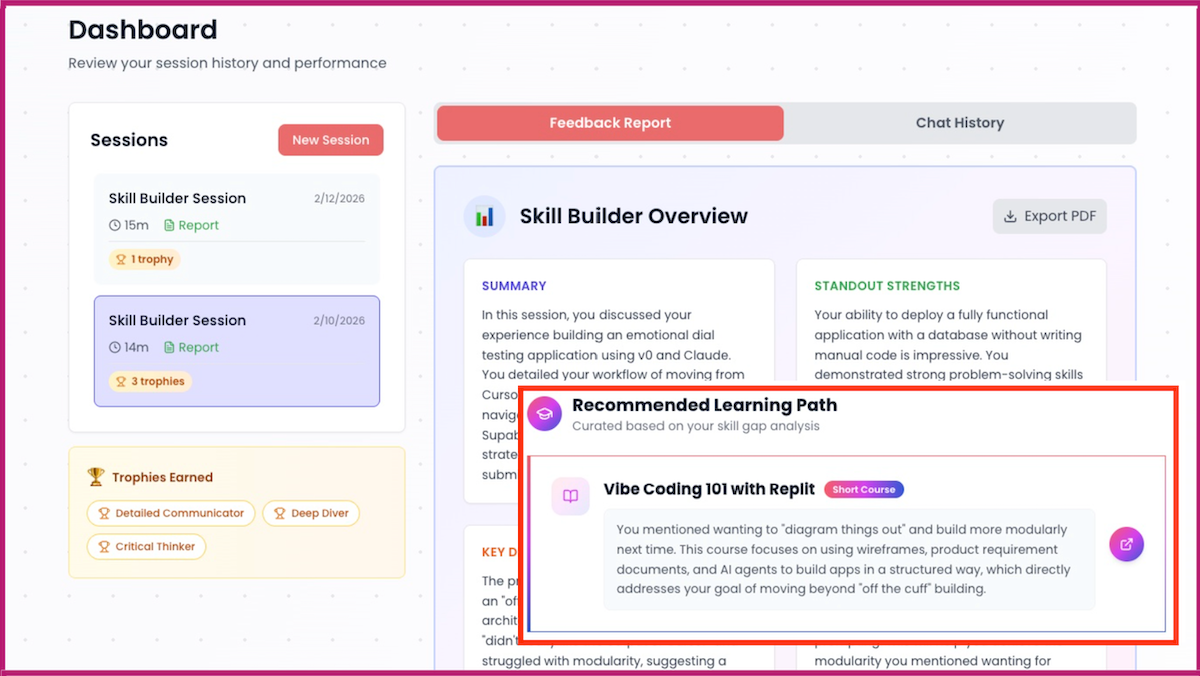
The Batch AI News and Insights: We just released a Skill Builder tool to help you understand in which areas of AI you’re strong, where you can learn more, and what to do next to keep building your skills.
Dear friends,
We just released a Skill Builder tool to help you understand in which areas of AI you’re strong, where you can learn more, and what to do next to keep building your skills. I invite you to have a conversation with it.
There are many job opportunities in AI! Employers are eager to hire people with AI skills. But the landscape of AI technology is large, growing, and rapidly changing. To navigate this landscape, many people find that occasional conversations with a knowledgeable, trusted mentor are helpful for deciding where to go next.
Our Skill Builder serves this role. Tell it about your AI projects, and it will provide personalized feedback on where you are and suggest ways to take your AI skills to the next level. This is designed for everyone, from beginners who use AI only by prompting ChatGPT to advanced users who are building complex agentic workflows with multiple AI building blocks and a sophisticated development process.
When I’m learning a new skill, I find it hard to understand where I stand in the field, since I don’t yet know what I don’t know. Skill Builder addresses this for AI skills. It’s free for everyone to use, and many have reported finding the conversations informative. Following the conversation, it will show everyone a summary report and recommend what to learn next. DeepLearning.AI Pro members additionally get more-detailed personalized feedback.
Whether you’re checking your skills, deciding what project to work on next, choosing which course to take, or preparing for job interviews, I hope Skill Builder will help you move forward with clarity.
Keep building your skills!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

You don’t need to learn how to code to build an app. In Build with Andrew, Andrew Ng shows how to turn ideas into working web apps using simple instructions. Perfect for beginners and easy to share with someone who has been waiting to start. Explore the course today!
News
Gemini Takes the Lead
Google updated its flagship Gemini model, topping several benchmarks while undercutting competitors on performance per dollar.
What’s new: Google launched Gemini 3.1 Pro Preview at the same price as its predecessor Gemini 3 Pro Preview. Gemini 3.1 Pro Preview is the basis of recent performance gains by Gemini 3 Deep Think, a specialized reasoning mode separate from the three reasoning levels available via API.
- Input/output: Text, images, PDFs, audio, video in (up to 1 million tokens), text out (up to 64,000 tokens, 108.6 tokens per second)
- Architecture: Mixture-of-experts transformer
- Features: Tool use (Google search, Python code execution, file search, function calling), structured outputs, adjustable reasoning (low, medium, high)
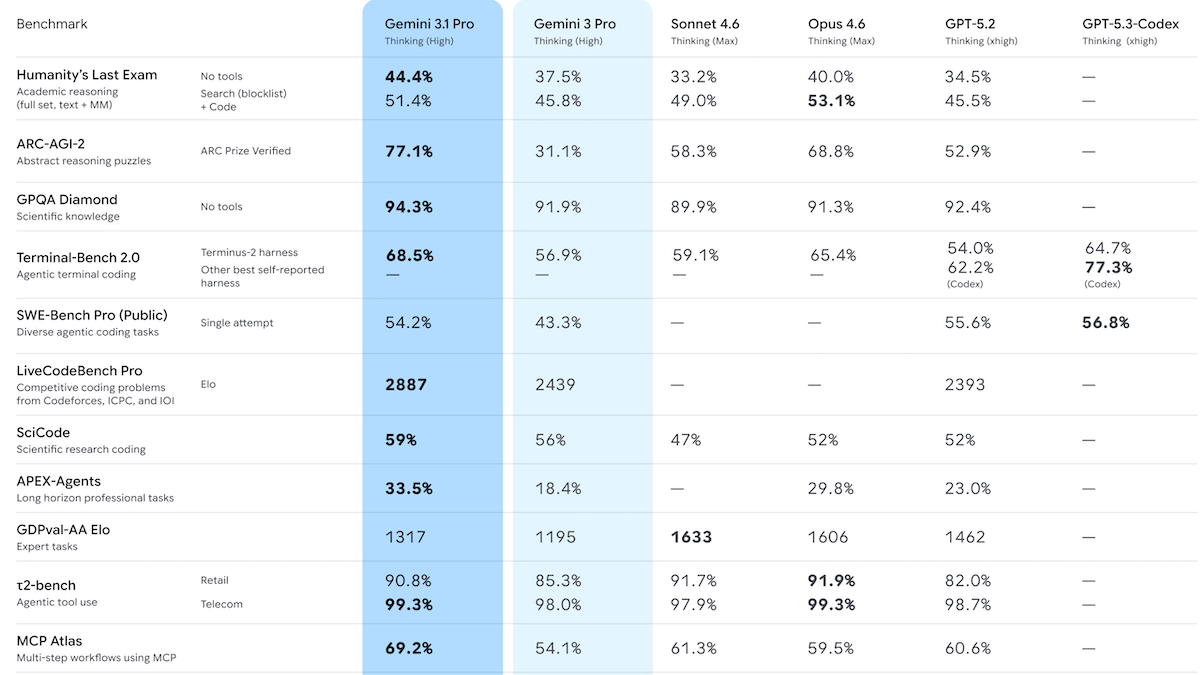
- Performance: Gemini 3.1 Pro Preview with reasoning (level unspecified) topped Artificial Analysis Intelligence Index; achieved state of the art on ARC-AGI-2, GPQA Diamond, Humanity’s Last Exam, MCP Atlas, BrowseComp, Terminal-Bench 2.0, MathArena Apex, MMLU-Pro
- Availability/price: Available to Google AI Pro and Ultra subscribers via Gemini app; integrated with the paid services Google AI Studio, Vertex AI, Gemini CLI, and third-party tools including Microsoft Visual Studio and GitHub CoPilot; API $2/$0.20/$12 per million input/cached/output tokens for input contexts under 200,000 tokens, $4/$0.40/$18 per million input/cached/output tokens for input contexts greater than 200,000 tokens (plus $4.50 per million cached tokens per hour)
- Knowledge cutoff: January 2025
- Undisclosed: Parameter count, architecture details, training methods
How it works: Google disclosed few details about Gemini 3.1 Pro Preview. The model is a sparse mixture-of-experts transformer pretrained on text, code, images, audio, and video scraped from the web alongside licensed materials, Google user data, and synthetic data. It was fine-tuned via reinforcement learning on datasets that covered multi-step reasoning, solving problems, and proving theorems. Its model card points readers to the Gemini 3 Pro model card.
Performance: Gemini 3.1 Pro Preview achieved a variety of state-of-the-art metrics in tests performed by Artificial Analysis. However, it trailed on some measures of agentic behavior and user-preference rankings. Some sources of test results don’t specify a reasoning setting; API calls to Gemini 3.1 Pro Preview default to high reasoning.
- On the Artificial Analysis Intelligence Index, a weighted average of 10 benchmarks that focus on economically useful work, Gemini 3.1 Pro Preview with reasoning (57 points at a cost of $892) outperformed Claude Opus 4.6 set to max reasoning (53 points, $2,486), GPT-5.2 set to xhigh reasoning (51 points, $2,304), and the open-weights GLM-5 (50 points, $547). It led six of the index’s 10 component benchmarks.
- However, Gemini 3.1 Pro Preview (reasoning unspecified) placed seventh in coding on Arena, which ranks models by user preference in blind head-to-head comparisons.
- It also trailed on Artificial Analysis’ GDPval-AA agentic benchmark, where it achieved 40 percent, behind Claude Sonnet 4.6 set to max reasoning (57 percent) and GLM-5 (45 percent).
- On ARC-AGI-2 visual logic puzzles, Gemini 3.1 Pro Preview achieved 77.1 percent at $0.96 per task — more than double its predecessor’s 31.1 percent — and well above Claude Opus 4.6 set to high reasoning (69.2 percent at $3.47 per task).
Why it matters: Gemini 3.1 Pro’s gains appear to stem more from improved model quality than additional computation during inference: In completing the Artificial Analysis Intelligence Index, it consumed roughly the same number of tokens as its predecessor, yet it scored significantly higher. This suggests that refining models can still yield significant performance gains without inflating inference costs.
We’re thinking: On ARC-AGI-2, the performance of Gemini-3.1 Pro Preview — presumably set to high reasoning — is less than 10 percent shy of Gemini 3.1 Deep Think’s (77 percent versus 85 percent) but 13 times less expensive ($0.96 per task versus $13.62 per task). That’s an incentive to reserve Deep Think for the very hardest problems.

Global AI Summit Shows Optimism
The fourth global AI summit marked a decisive shift from focusing on theoretical hazards to spreading AI’s benefits throughout the world.
What’s new: The AI Impact Summit showcased India’s ambition to serve as a counterweight to the United States and China. This year’s gathering of government officials, business leaders, and researchers took place in New Delhi from February 16 to February 20.
How it works: Billed as the first global AI summit to be hosted in the global south, the conference attracted hundreds of thousands of participants and representatives of more than 100 countries. The leaders of India, Brazil, France, Spain, Bolivia, Mauritius and Sri Lanka were in attendance, as well as UN Secretary-General António Guterres, Director of the White House Office of Science and Technology Policy Michael Kratsios, and star CEOs including Alphabet’s Sundar Pichai, OpenAI’s Sam Altman, and Anthropic’s Dario Amodei. But one participant reported that “Chinese participation was almost nonexistent,” as the schedule overlapped with Chinese New Year celebrations.
- More than 85 countries including the U.S. and China endorsed the New Delhi Declaration on AI Impact, a non-binding agreement to harness AI for economic growth, social good, and shared global benefit rather than narrow national or corporate advantage. The declaration emphasizes seven principles: democratization of AI resources, social empowerment, economic growth and social good, secure and trusted AI, AI for science, nurturing of skills and education, and sustainable AI systems.
- In his summit appearance, Prime Minister Nerendra Modi promoted India as a force for affordable technology designed for a diverse audience. Modi touted India’s supply of tech talent, public technology infrastructure, and startup ecosystem (third largest in the world).
- Top AI companies expanded their presences in India. Anthropic and OpenAI opened offices in Bengaluru and Mumbai, respectively. OpenAI announced an agreement to use Tata Consultancy Services’ data centers and provide its ChatGPT Enterprise service. Google committed to building an AI hub in the southeastern port city of Visakhapatnam and promised to route additional subsea cables between India, the U.S., and other countries.
- Human-rights organizations criticized the summit for failing to address gaps in AI governance. For instance, Amnesty International said that AI in India contributes to “systems of mass surveillance . . . in an already pernicious context of civil rights abuses.” The organization called the summit “largely irrelevant and ineffective at advancing binding rights protections” and called for “regulations for a digitally safe future.”
Behind the news: India is in the spotlight as major AI companies have pledged to invest there and the national government ramps up its own AI spending.
- Google has committed $15 billion over five years to establish an artificial intelligence hub. Microsoft will invest $17.5 billion over four years in India’s cloud and AI infrastructure. Amazon plans to spend $35 billion by 2030 to build its business in India.
- As the conference opened, India allocated $1.1 billion to fund startups in AI and other high-tech fields.
- The government is funding domestic startups to build models that can process its 22 officially recognized languages while running on relatively small processing budgets.
Why it matters: Advancing AI is a global effort, and communication among national governments is an important part. This year’s summit focused on realistic issues like ensuring access to processing and connectivity and encouraging competition in the market — a welcome change from the unrealistic science-fiction worries that dominated the initial event in 2023. This year’s optimistic atmosphere signals that the 2024 and 2025 summits helped attendees recognize AI’s value. At the same time, critics highlighted the ongoing challenge of aligning AI’s rapid build-out with democratic values.
We’re thinking: It’s important that global leaders get together and keep talking. We’re glad to see that the AI summit remains ongoing and governments are aiming to use AI for the benefit of all.
Investors Panic Over Agentic AI
Makers of software that runs large companies saw their share prices plunge as investors worried that AI systems could undermine their businesses. This week, their stocks rebounded somewhat as Anthropic partnered with some of the same companies.
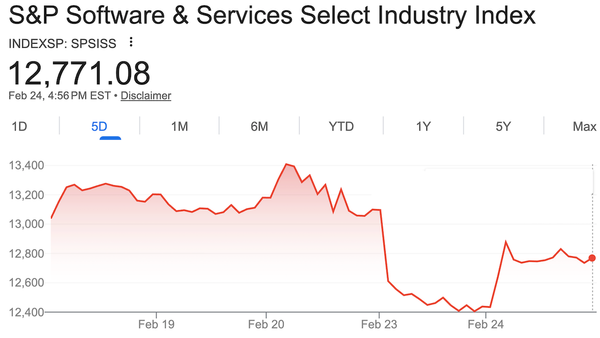
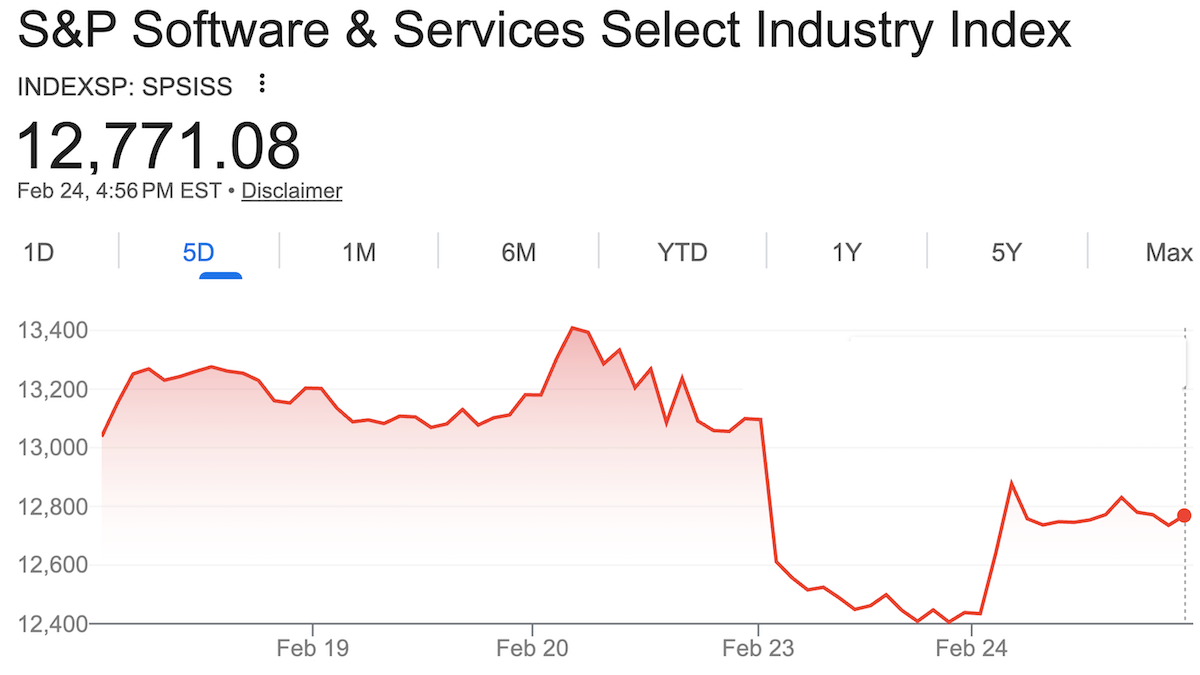
What’s new: Investors, alarmed by the prospect that AI-enabled coding systems could reproduce popular software tools, drove down the S&P Software & Services Index, which includes software giants such as Microsoft, Oracle, Salesforce, and Workday. The index lost 25 percent of its value between January 12, when Anthropic introduced Claude Cowork, an agent designed for professional work, and February 23, when it showed signs of recovering.
SaaSpocalypse now: The stock selloff affected mostly vendors of software subscriptions via the web, a business known as software as a service (SaaS). Jeffrey Favuzza, a strategist at the investment firm Jefferies Financial Group, dubbed the event the “SaaSpocalypse.”
- Anthropic poured fuel on the fire with further releases designed to take on tasks typically performed by SaaS offerings. On January 30, Anthropic released 11 open-source plugins, each targeting a white-collar job function. The functions include calendar management, document search and retrieval, sales, financial analysis, data queries and visualizations, legal review and compliance, marketing, customer support, product management, and biology research, plus a plugin that creates and customizes new plugins. Independent developers quickly contributed a wave of plugins that delivered functionality similar to other business software.
- Four days later, the S&P Software & Services Index dropped 4 percent to wipe out more than $285 billion in market capitalization. JPMorgan’s software index lost 7 percent. Shares of LegalZoom.com tumbled nearly 20 percent, Thompson Reuters 16 percent.
- On February 20, Anthropic unveiled Claude Code Security, a cybersecurity application designed to detect and patch software vulnerabilities after human review. A selloff of shares in security software companies followed. (Google’s CodeMender and OpenAI’s Aardvark similarly perform AI-powered security functions.)
- On February 24, Anthropic extended an olive branch to software companies when it announced integrations with some of the companies that Cowork threatens, including Docusign, FactSet, Google’s Gmail, Intuit, and Salesforce. Instead of bypassing their applications, a new wave of Cowork plugins connect to them directly. The new approach also gives companies more control over how the plugins are used and monitored. SaaS stocks jumped, although they did not recover their earlier losses.
Behind the news: With the rise of AI-assisted coding, observers have suggested that AI could disrupt traditional software either by replicating its capabilities or enabling agents to replace human users. In the latter scenario, AI would end the “lock-in” effect in which customers remain loyal to a particular service because they don’t want to adjust to a different vendor’s user interface or workflow. In December, Lee Robinson, vice president of developer education at Cursor, which makes AI-assisted coding tools, wrote that his company had completely replaced a content management system it previously paid for, Sanity, with a custom setup it built from scratch. The company now manages its web pages using git and saves tens of thousands of dollars in recurring fees. Sanity spokesman Knut Melvær wrote a public reply noting that Sanity’s product serves purposes, such as facilitating collaboration, that can’t easily be replicated using Cursor’s setup.
Why it matters: Investors may have panicked, but their attention isn’t misplaced: AI is changing the software market. Nonetheless, many SaaS companies will continue to thrive, and new opportunities will continue to emerge. Large language models can dissolve some competitive barriers, but others remain solid, as Fintool CEO Nicolas Bustamante explains in an insightful social media post. Agents can operate unfamiliar user interfaces, navigate complex business processes, access public datasets, and collapse expertise in multiple areas into one application. On the other hand, systems based on LLMs can’t necessarily replace SaaS offerings that rely on proprietary data, regulatory compliance, network effects, or embedded transactions. The message of the SaaSpocalypse is not that software is dead. It’s that small teams can build competitive products rapidly, and the products that have staying power will be built on resources that are beyond the reach of LLMs.
We’re thinking: SaaS isn’t dying, it’s becoming AI-native.
Can Local AI Stand In for the Cloud?
Projected demand for output from large language models is spurring a massive buildout of data centers. Researchers asked whether smaller models running on local devices could meaningfully lighten that load.
What’s new: Jon Saad-Falcon, Avanika Narayan, and colleagues at Stanford University and Together AI, a provider of software development and training, found that laptops are increasingly capable of substituting for cloud computing, based on a metric they call intelligence per watt.
Key insight: Cloud systems are typically more energy-efficient per user than local systems, but smaller, high-performance models increasingly enable local systems to run more efficiently. In a previous era, processing shifted from mainframes to personal computers when personal computers could perform well enough while using the same or less energy. Similarly, AI workloads can shift from data centers to personal devices if smaller models running on laptops can provide sufficient accuracy while using less energy per query. We can measure the viability of local versus cloud computing by computing intelligence per watt: the accuracy on a given task divided by the power consumed to achieve it. Assuming local and cloud systems achieve similar accuracy, the one with the higher intelligence per watt is a more efficient choice.
How it works: The authors ran various open-weights large language models on hardware designed for laptops and data-center servers. To measure the trend in intelligence per watt over time, they included both recent models (from the Qwen3, GPT-OSS, Gemma3, and IBM Granite 4.0 families, late-2025 vintage) and older models (Mixtral-8x7B and Llama -3.1-8B, circa 2023-2024), recent processors (including the Apple M4 Max laptop chip and Nvidia H100 data-center chip) and older processors (like the 2018-vintage Nvidia Quadro RTX 6000). They fed the models 1 million queries from real-world conversations, science, and academic disciplines.
- To measure accuracy, the authors compared fixed outputs to ground truth and used GPT-4o to evaluate open-ended responses.
- Simultaneously, they recorded power consumption.
- The authors used this data to simulate an ideal system for routing the queries to models: For each query, they tracked the model — whether hosted locally or in the cloud — that responded correctly while using the least power, and assumed that model processed the query.
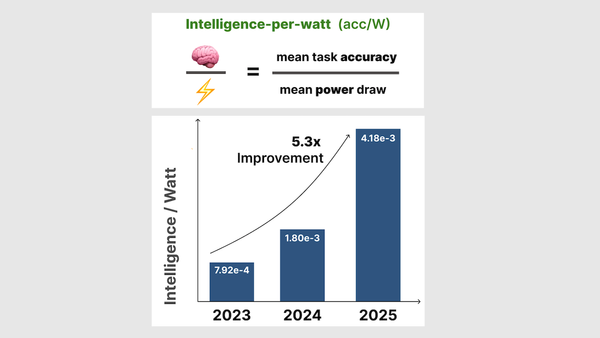
Results: Local systems don’t yet match cloud systems for intelligence per watt, but they are improving as researchers develop smaller models that achieve higher performance. If local systems are as accurate as cloud systems, routing queries to them could save substantial amounts of energy.
- Cloud-computing systems are more intelligent per watt. Smaller models that ran on the Nvidia B200 chip achieved at least 1.4x higher intelligence per watt than the same models running on local chips.
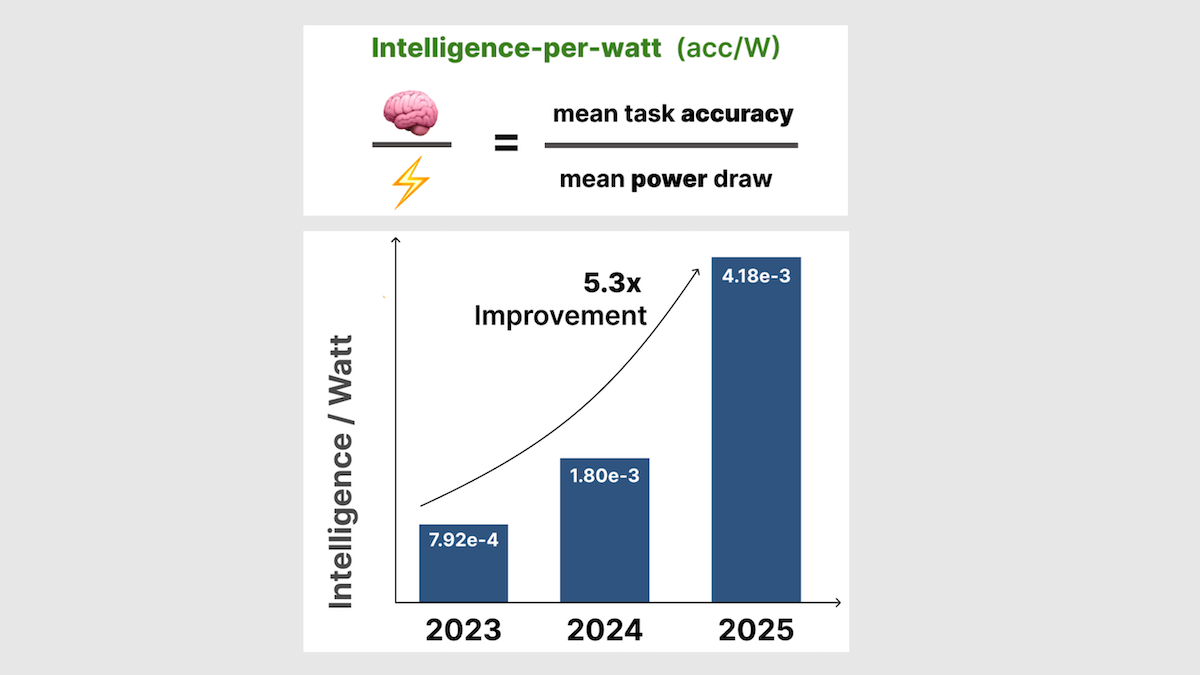
- However, in local systems, intelligence per watt has risen dramatically. Intelligence per watt rose 5.3 times between 2023 and 2025, driven by algorithmic advances and hardware improvements.
- In the authors’ analysis of single-turn chat and reasoning queries, local systems that ran smaller models were able to answer approximately 88.7 percent of queries correctly relative to cloud systems while consuming substantially less power. In simulated hybrid scenarios, power savings exceeded 80 percent.
Yes, but: The authors did not assess the intelligence per watt of proprietary models like OpenAI GPT-5, likely because it’s unclear how much power they use. However, they did compare the accuracy of proprietary models. The most accurate local model (Qwen3-14B) trailed behind GPT-5, Gemini-2.5-Pro, and Claude Sonnet 4.5 by 11 percent accuracy to 13 percent accuracy.
Why it matters: Researchers are improving large language models rapidly, making higher performing models for the same amount of power usage. Tracking this performance increase reveals the relative trade-off between power and performance over time. As that tradeoff tilts more and more towards low-power devices, people have more options. These options offer the potential to spread the computational load and enable machine intelligence to be distributed more widely.
We’re thinking: Privacy often drives the conversation around local AI. The prospect of rising intelligence per watt creates an intriguing economic argument.