
OpenAI Reorgs For Profit, MiniMax-M2 Leads Open Coding, Universal Music Group Embraces AI, LLMs Go Private
The Batch AI News and Insights: AI agents are getting better at looking at different types of data in businesses to spot patterns and create value. This is making data silos increasingly painful.

Dear friends,
AI agents are getting better at looking at different types of data in businesses to spot patterns and create value. This is making data silos increasingly painful. This is why I increasingly try to select software that lets me control my own data, so I can make it available to my AI agents.
Because of AI’s growing capabilities, the value you can now create from “connecting the dots” between different pieces of data is higher than ever. For example, if an email click is logged in one vendor’s system and a subsequent online purchase is logged in a different one, then it is valuable to build agents that can access both of these data sources to see how they correlate to make better decisions.
Unfortunately, many SaaS vendors try to create a data silo in their customer’s business. By making it hard for you to extract your data, they create high switching costs. This also allows them to steer you to buy their AI agent services — sometimes at high expense and/or of low quality — rather than build your own or buy from a different vendor. Unfortunately, some SaaS vendors are seeing AI agents coming for this data and working to make it harder for you (and your AI agents) to efficiently access it.
One of my teams just told me that a SaaS vendor we have been using to store our customer data wants to charge over $20,000 for an API key to get at our data. This high cost — no doubt intentionally designed to make it hard for customers to get their data out — is adding a barrier to implementing agentic workflows that take advantage of that data.

Through AI Aspire (an AI advisory firm), I occasionally advise businesses on their AI strategies. When it comes to buying SaaS, I often advise them to try to control their own data (which, sadly, some vendors mightily resist). This way, you can hire a SaaS vendor to record and operate on your data, but ultimately you decide how to route it to the appropriate human or AI system for processing.
Over the past decade, a lot of work has gone into organizing businesses’ structured data. Because AI can now process unstructured data much better than before, the value of organizing your unstructured data (including PDF files, which LandingAI’s Agentic Document Extraction specializes in!) is higher than ever before.
In the era of generative AI, businesses and individuals have important work ahead to organize their data to be AI-ready.
Keep building,
Andrew
P.S. As an individual, my favorite note-taking app is Obsidian. I am happy to “hire” Obsidian to operate on my notes files. And, all my notes are saved as Markdown files in my file system, and I have built AI agents that read from or write to my Obsidian files. This is a small example of how controlling my own notes data lets me do more with AI agents!
A MESSAGE FROM DEEPLEARNING.AI

In Jupyter AI: AI Coding in Notebooks, Andrew Ng and Brian Granger (co-founder of Project Jupyter) teach you to use Jupyter AI as your notebook coding partner. Learn to generate, refactor, and debug code through an integrated chat interface. Available now at DeepLearning.AI. Enroll today!
News

OpenAI Reorganizes For Profit
OpenAI completed its transition from nonprofit to for-profit in a feat of legal engineering that took an army of lawyers, investment bankers, and two state attorneys general 18 months to negotiate.
What’s new: The restructured OpenAI Group PBC is a public benefit corporation, a for-profit company with a mission to create a positive social impact. It can earn unlimited returns to its investors, which clears the way to attract further investments including a possible initial public offering. It remains overseen by a nonprofit foundation, the newly renamed Open AI Foundation, which owns a 26 percent stake in the corporation. Microsoft holds a 27 percent stake in OpenAI under new terms for the companies’ partnership.
How it works: The agreement frees OpenAI from the constraints of its 2015 nonprofit beginnings that have limited investors to a 100x maximum return since an earlier restructuring in 2019. The new structure aims to satisfy the concerns of state officials in California and Delaware that the old structure created conflicts of interest between serving the public and rewarding shareholders, even as it aims to preserve the company’s mission to ensure that artificial general intelligence (AGI), if and when OpenAI builds it, will benefit humanity.
- As a public benefit corporation, OpenAI must balance revenue and growth with providing social good. Among AI companies, Anthropic and GrokAI also are PBCs.
- OpenAI’s structure remains unusual in that a nonprofit organization is still in charge technically. OpenAI Foundation has the power to appoint and remove the corporation’s board members, and its directors sit on the for-profit’s board. Its safety-and-security committee can halt releases of new models.
- OpenAI’s nonprofit, whose stake in the company is worth $130 billion, is the wealthiest foundation in the U.S. For comparison, the Gates Foundation holds $86 billion. It committed an initial $25 billion to improving healthcare and fortifying AI guardrails.
- Microsoft will have rights to use OpenAI’s models until 2032, including models built after the companies agree that OpenAI has built an AGI. Microsoft will continue to receive 20 percent of OpenAI’s revenue and have an exclusive right to use its APIs, but it no longer has a right of first refusal on new cloud business, according to Bloomberg. The revenue-sharing and API agreements will remain in effect until an independent panel verifies that OpenAI has achieved AGI.
Behind the news: This isn’t the restructuring OpenAI originally wanted. A 2024 plan would have eliminated the nonprofit and turned the company into a traditional venture-backed entity. The California and Delaware attorneys general balked at that proposal, which led to a compromise that keeps the nonprofit in charge.
- OpenAI needed California’s and Delaware’s approvals to avoid losing a $40 billion investment from SoftBank, half of which was contingent on the restructuring and lifting of the cap on investor returns. It also needed Microsoft’s agreement. This gave Microsoft significant leverage over the terms.
- OpenAI committed to remaining in California, and thus to continue to be subject to the state’s oversight, as part of its negotiation with California’s attorney general.
Why it matters: OpenAI has achieved staggering growth in its user base and valuation in spite of its nonprofit status. The new restructure adds pressure to get on a road to profitability. The company’s annual revenue run rate reportedly is greater than $13 billion, but given its commitment to spend an estimated $1 trillion on computing infrastructure, further funding is necessary to finance its ambitions.
We’re thinking: Microsoft’s early investments in OpenAI have more than paid off. When Microsoft CEO Satya Nadella proposed his company’s initial $1 billion investment in 2019, Bill Gates warned, “You’re going to burn this billion dollars.” Microsoft’s total investment of $13 billion is now worth $135 billion.
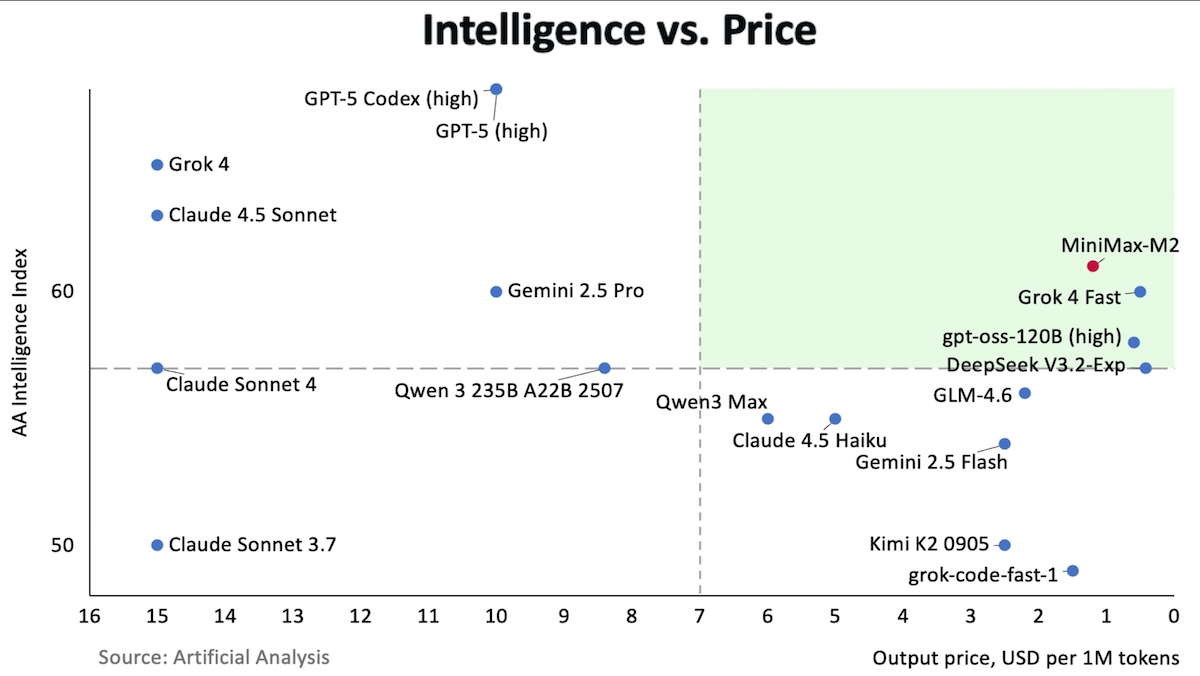
Open-Weights Coding Leader
An open-weights model from Shanghai-based MiniMax challenges top proprietary models on key benchmarks for coding and agentic tasks.
What’s new: MiniMax, which provides voice-chat and image-generation services, released the weights for MiniMax-M2, a large language model that’s optimized for coding and agentic tasks.
- Input/output: Text in (up to 204,000 tokens), text out (up to 131,000 tokens, roughly 100 tokens per second)
- Architecture: Mixture-of-experts transformer, 230 billion parameters total, 10 billion parameters active per token
- Performance: First among open weights models on Artificial Analysis’ Intelligence Index
- Availability: Weights free to download from Hugging Face and ModelScope for commercial and noncommercial uses under MIT license, API $0.30/$1.20 per million input/output tokens via MiniMax
- Undisclosed: Training data, specific training methods
How it works: MiniMax has not published a technical report on MiniMax-M2, so little public information is available about how it built the model.
- Given a prompt, MiniMax-M2 interleaves reasoning steps (enclosed within <think>...</think> tags) within its output. This differs from models like DeepSeek-R1 that generate a block of reasoning steps prior to final output. It also differs from models like OpenAI GPT-5 and recent Anthropic Claude models that also generate reasoning steps prior to final output but hide or summarize them.
- MiniMax advises users to retain <think>...</think> tags in their conversation histories for optimal performance across multiple turns, because removing them (say, to economize on tokens) would degrade the model’s context.
Results: MiniMax-M2 achieved 61 on independent evaluator Artificial Analysis’ Intelligence Index (a weighted average of benchmark performance in mathematics, science, reasoning, and coding), a new high for open weights models, ahead of DeepSeek-V3.2 (57 points) and Kimi K2 (50 points). It trails proprietary models GPT-5 with thinking enabled (69 points) and Claude Sonnet 4.5 (63 points). Beyond that, it excelled in coding and agentic tasks but proved notably verbose. It consumed 120 million tokens to complete Artificial Analysis evaluations, tied for highest with Grok 4.
- On τ2-Bench, a test of agentic tool use, MiniMax-M2 (77.2 percent) ranked ahead of GLM-4.6 (75.9 percent) and Kimi K2 (70.3 percent) but behind Claude Sonnet 4.5 (84.7 percent) and GPT-5 with thinking enabled (80.1 percent).
- On IFBench, which tests the ability to follow instructions, MiniMax-M2 (72 percent) significantly outperformed Claude Sonnet 4.5 (57 percent) but narrowly trailed GPT-5 with thinking enabled (73 percent).
- On SWE-bench Verified, which evaluates software engineering tasks that require multi-file edits and test validation, MiniMax-M2 (69.4 percent) ranked in the middle tier ahead of Gemini 2.5 Pro (63.8 percent) and DeepSeek-V3.2 (67.8 percent) but behind Claude Sonnet 4.5 (77.2 percent) and GPT-5 with thinking enabled (74.9 percent).
- On Terminal-Bench, which measures command-line task execution, MiniMax-M2 (46.3 percent) ranked second only to Claude Sonnet 4.5 (50 percent), significantly ahead of Kimi K2 (44.5 percent), GPT-5 with thinking enabled (43.8 percent), and DeepSeek-V3.2 (37.7 percent).
Behind the news: In June, MiniMax published weights for MiniMax-M1, a reasoning model designed to support agentic workflows over long contexts (1 million tokens). The company had been developing agents for internal use in tasks like coding, processing user feedback, and screening resumes. However, it found that leading closed-weights models were too costly and slow, while open-weights alternatives were less capable. It says it built MiniMax-M2 to fill the gap.
Why it matters: Developing reliable agentic applications requires experimenting with combinations and permutations of prompts, tools, and task decompositions, which generates lots of tokens. Cost-effective models that are capable of agentic tasks, like MiniMax-M2, can help more small teams innovate with agents.
We’re thinking: MiniMax-M2’s visible reasoning traces make its decisions more auditable than models that hide or summarize their reasoning steps. As agents are applied increasingly to mission-critical applications, transparency in reasoning may matter as much as raw performance.

AI Music With Major-Label Support
Music-generation service Udio will build an AI streaming platform in collaboration with the world’s biggest record label.
What’s new: Udio plans to launch a paid platform that enables fans to generate music based on recordings by artists on Universal Music Group (BMG) and its subsidiary labels. UMG artists include Taylor Swift, Olivia Rodrigo, Kendrick Lamar, and many other best-selling performers. The venture is part of an agreement to settle a lawsuit filed last year, in which UMG alleged that Udio had violated its copyrights when the AI company trained its music models. The financial terms, duration, and the remainder of the settlement are undisclosed. Udio is free to make similar arrangements with other music labels, the music-industry news publication Billboard reported.
How it works: The platform will allow paying customers to remix, customize, and combine existing recordings and share them with other subscribers.
- Artists must give permission for their recordings to be available on the platform, and they will control how recordings may be used; for instance, to mimic voices or musical styles, change from one style to another, combine one artist’s characteristics with those of another, and the like.
- Artists will receive payments for making their music available for training Udio models plus further compensation for uses of their recordings to produce generated music.
- The new platform will not allow users to download generated music or distribute it via other streaming services. As part of the agreement, Udio briefly terminated the ability to download generated music from its current service and offered subscribers additional credits to generate music to compensate for taking away this capability. After users complained, Udio temporarily restored downloads of existing generated music. The company said its existing service will remain available but with differences that include fingerprinting and other measures.
Other deals: In addition to Udio, UMG forged relationships with other AI music companies that supply tools and technology.
- UMG and Sony Music said they would use audio fingerprinting technology developed by SoundPatrol, which compares learned embeddings to identify generated output related to an original source.
- Stability AI, maker of the Stable Audio 2.5 music generator, announced a partnership with UMG to develop professional music-production tools.
Behind the news: Like book publishers and movie studios, recording companies have moved aggressively to stop AI companies from training models on materials they control and generating output that might compete with them.
- STIM, a Swedish organization that collects royalties on behalf of composers and recording artists, devised a license to compensate musicians for use of their works to train AI models.
- Last year, Sony Music, UMG, Warner Music, and trade organization Recording Industry Association of America (RIAA) sued Suno and Udio for alleged copyright violations in their music generators. The music companies filed separate lawsuits that alleged the AI companies had trained AI models on copyrighted recordings, and made unauthorized copies in the process, to compete commercially with their music.
- In 2023, UMG pressed Apple Music, Spotify, and YouTube to counter AI-enabled imitations of its artists by blocking AI developers from downloading their recordings. It also asked the streaming companies not to distribute AI-generated music.
Why it matters: Music labels, like other media companies, see their businesses threatened by generative AI, which can synthesize products that are superficially similar to their own at lower cost and in less time. A study by the French streaming music service Deezer found that nearly 28 percent of the music it delivered was generated. In June, a musical group called Velvet Sundown racked up 1 million plays on Spotify of music generated by Suno. The settlement between Udio and UMG unites traditional and AI-generated music in a single business and suggests there could be common ground between media and AI companies, albeit with side effects such as limiting Udio’s distribution of generated music.
We’re thinking: Lawsuits against Suno and Udio by Sony Music, Warner Music, and the RIAA are still underway. This deal offers a blueprint for resolving those cases, but their outcomes are by no means certain. As lovers of music, we look forward to hearing more of it.
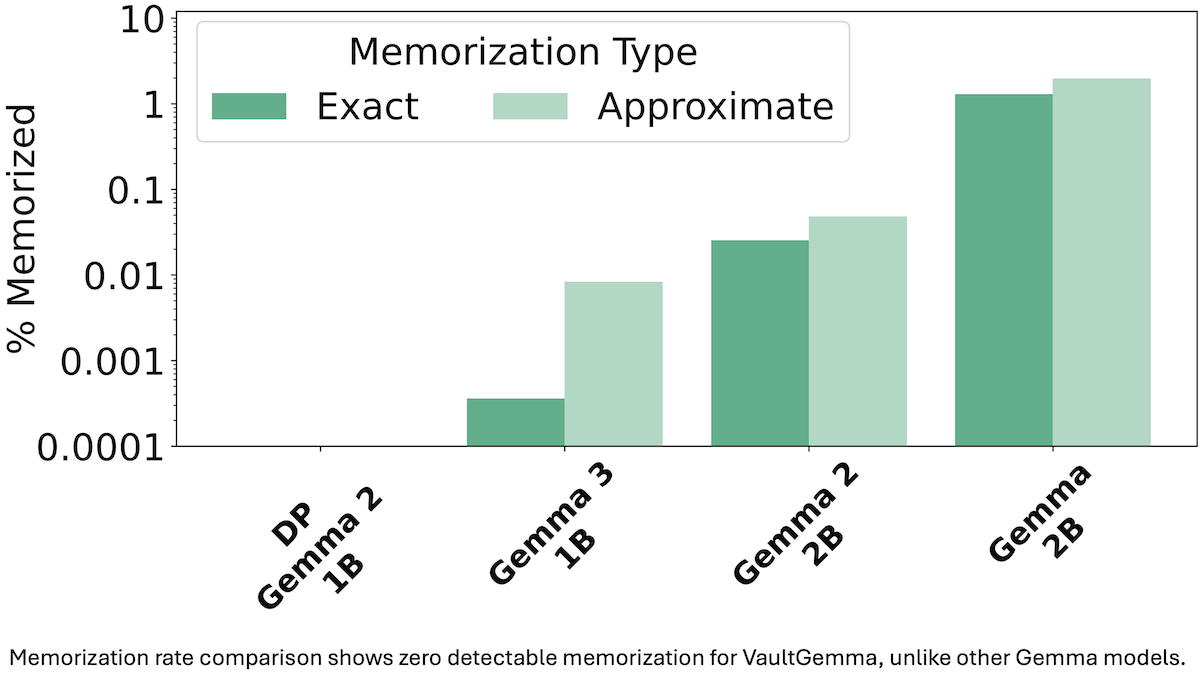
Masking Private Data in Training Sets
Large language models often memorize details in their training data, including private information that may appear only once, like a person’s name, address, or phone number. Researchers built the first open-weights language model that’s guaranteed not to remember such facts.
What’s new: Amer Sinha, Thomas Mesnard, and colleagues at Google released VaultGemma, a 1 billion-parameter model that’s trained from scratch using the technique known as differential privacy. This method prevented the model from memorizing examples that occurred only once in its training data, with a modest sacrifice in performance. Weights are free to download under a license that allows noncommercial and commercial uses with some restrictions.
Differential privacy basics: An algorithm (such as training a neural network) is differentially private if it’s impossible to tell the difference between its product (the learned weights) and its product given that same dataset minus any given example. Since the presence or absence of a single example can’t significantly change the product, personal information can’t leak from the product (the model’s weights) or the consequences of the product (the model’s outputs). In training a neural network, it’s possible to limit the impact of one example by limiting how much each example’s gradient can impact a model’s weights, for instance, by adding noise to each example’s gradient to make it harder to tell from that of other examples.
Key insight: Most previous work applies differential privacy when fine-tuning a model, but that doesn’t prevent the model from memorizing an example during pretraining. Once private information is encoded in the model’s weights, later fine-tuning can’t remove it reliably. Training with differential privacy from the start ensures that such details don’t become embedded in the model.
How it works: VaultGemma follows the same transformer architecture as the 1 billion-parameter version of Google’s Gemma 2. Moreover, the authors pretrained it from scratch on the same 13-trillion-token dataset as Gemma 2 (web, code, and scientific text). The authors applied differential privacy as VaultGemma learned to predict the next token in sequences of 1,024 tokens.
- For every example in a batch, the authors computed the gradient and clipped it so its contribution to the weight update didn’t exceed a fixed threshold. This ensured that any given example didn’t have a disproportionate impact on the weight updates relative to other examples.
- The authors averaged the clipped gradients across each batch and added Gaussian noise to the average before updating the model’s weights. The noise weakened the influence of unique examples while allowing repeated examples to stand out. As a result, the model’s weights became statistically indistinguishable from those of a model trained without any particular 1,024-token sequence.
Results: VaultGemma showed no measurable memorization across 1 million sequences sampled at random from the training set, while pretrained Gemma 1, 2, and 3 models of roughly similar sizes did. VaultGemma’s average performance across 7 question-answering benchmarks generally matched that of GPT-2 (1.5 billion parameters) but fell short of Gemma models of roughly similar size.
- The authors measured memorization in the Gemma family by the percentage of examples a model could reproduce when given the first half of the sequence. Gemma 3 (1 billion parameters) reproduced 0.0005 percent of training examples tested, while Gemma 2 (2 billion parameters) reproduced 0.04 percent. Gemma 1 (2 billion) reproduced about 1 percent. VaultGemma reproduced 0 percent.
- VaultGemma achieved 39 percent accuracy on HellaSwag, a benchmark that’s designed to test common-sense reasoning in everyday situations. GPT-2 achieved 48 percent and Gemma 3 (1 billion parameters) reached 61 percent.
- On TriviaQA, which measures factual question answering, VaultGemma achieved 11 percent, while GPT-2 achieved 6 percent and Gemma 3 (1 billion parameters) achieved 40 percent.
Yes, but: The privacy protection comes with a caveat: It applies only to unique examples such as a private phone number that occurs only once in the dataset. If private information appears repeatedly in the training data, for instance, a celebrity's street address that leaked and appeared in several publications, the model can learn it as a general pattern.
Why it matters: Private information can find its way into training datasets, and in normal use, a typical large language model may divulge it without the subject’s consent. VaultGemma shows that large open-weights models can be provably private. While such privacy still comes with a cost — VaultGemma 1B performs roughly on par with models built about five years ago — the results are promising, and future work may close that gap.
We’re thinking: The smartest model for sensitive data might be the one that remembers only the most common information.



