
Claude Levels Up, Qwen3 Proliferates, Big AI Diversifies Product Lines, LoRA Adapters on Tap
The Batch AI News and Insights: I’m thrilled to announce my latest course: Agentic AI! This course will get you up to speed building cutting-edge agentic workflows.

Dear friends,
I’m thrilled to announce my latest course: Agentic AI! This course will get you up to speed building cutting-edge agentic workflows. It is available from DeepLearning.AI here. The only prerequisite is familiarity with Python, though knowing a bit about LLMs helps too.
This self-paced course is taught in a vendor-neutral way, using raw Python — without hiding details in a framework. So you’ll learn the core concepts that you can then implement using any popular agentic AI framework, or using no framework.
Specifically, you’ll learn how to implement four key agentic design patterns:
- Reflection, in which an agent examines its own output and figures out how to improve it
- Tool use, in which an LLM-driven application decides which functions to call to carry out web search, access calendars, send email, write code, etc.
- Planning, where you’ll use an LLM to decide how to break down a task into sub-tasks for execution, and
- Multi-agent collaboration, in which you build multiple specialized agents — much like how a company might hire multiple employees — to perform a complex task.
More important, you’ll also learn best practices for building effective agents.
Having worked with many teams on many agents, I’ve found that the single biggest predictor of whether someone can build effectively is whether they know how to drive a disciplined process for evals and error analysis. Teams that don’t know how to do this can spend months tweaking agents with little progress to show for it. I’ve seen teams that spent months tuning prompts, building tools for an agent to use, etc., only to hit a performance ceiling they could not break through.

But if you understand how to put in evals and how to monitor an agent’s actions at each step (traces) to see when part of its workflow is breaking, you’ll be able to efficiently home in on which components to focus on improving. Instead of guessing what to work on, you'll let evals data guide you.
You’ll also learn to take a complex application and systematically decompose it into a sequence of tasks to implement using these design patterns. When you understand this process, you’ll also be better at spotting opportunities to build agents.
The course illustrates these concepts with many examples, such as code generation, customer service agents, and automated marketing workflows. We also build a deep research agent that searches for information, summarizes and synthesizes it, and generates a thoughtful report.
When you complete this course, you’ll understand the key building blocks of agents as well as best practices for assembling and tuning these building blocks. This will put you significantly ahead of the vast majority of teams building agents today.
Please join me in this course, and let’s build some amazing agents!
Keep building,
Andrew
A MESSAGE FROM DEEPLEARNING.AI

AI Dev 25, hosted by Andrew Ng and DeepLearning.AI, heads to New York City! On November 14, join 1,200+ AI developers for a day full of technical keynotes, hands-on workshops, live demos, and a new Fintech Track. Secure your tickets here!
News
Claude Levels Up
Anthropic updated its mid-size Claude Sonnet model, making it the first member of the Claude family to reach version 4.5. It also enhanced the Claude Code agentic coding tool with long-desired features.
Claude Sonnet 4.5: The new model offers a substantial increase in performance as well as a variable budget for reasoning tokens.
- Input/output: Text and images in (up to between 200,000 to 1 million tokens depending on service tier), text out (up to 64,000 tokens)
- Availability: Free via Claude.ai, API access $3/$15 per million tokens input/output via Anthropic, Amazon Bedrock, and Google Vertex
- Features: Reasoning with variable token budget, extended processing time (“hours” according to the documentation), serial (rather than simultaneous) completion of tasks
- Knowledge cutoff: January 2025
- Undisclosed: Model architecture, training data and methods
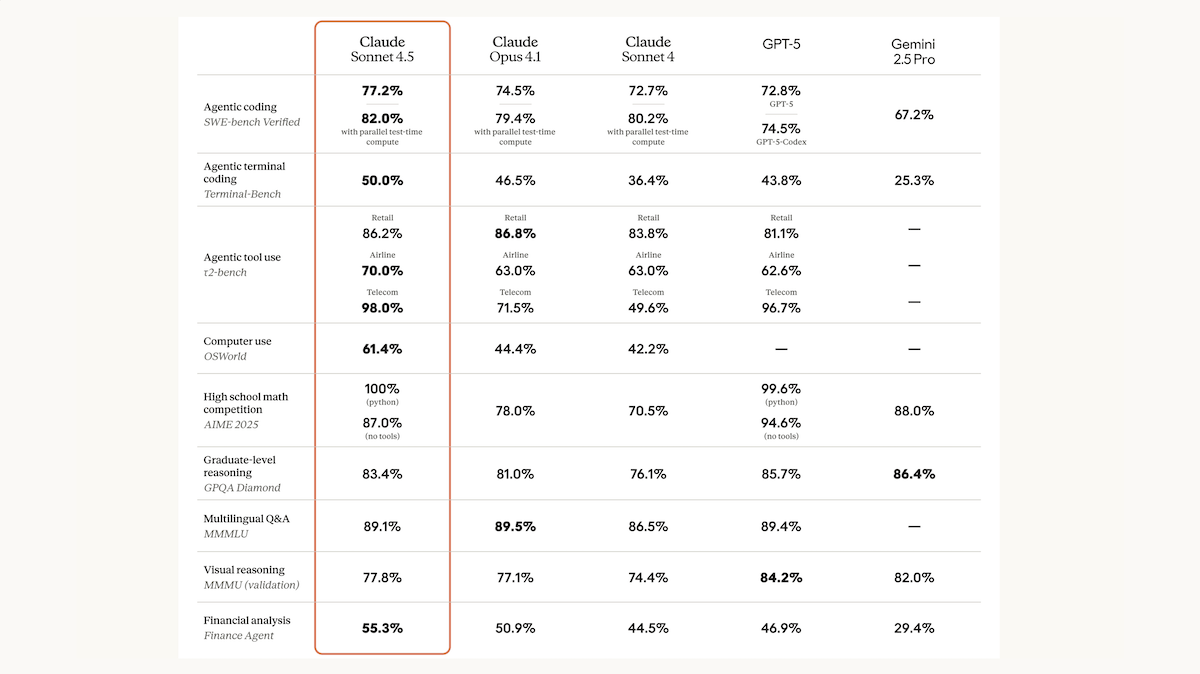
Results: In Anthropic’s tests, Claude Sonnet 4.5’s coding metrics stood out, but it performed well on broader assessments, too.
- With a reasoning budget of 32,000 tokens, Claude Sonnet 4.5 currently tops the LM Arena Text Leaderboard. Without reasoning, it ranks fourth.
- On coding challenges in SWE-bench Verified, Claude Sonnet 4.5 (82 percent) raised the state of the art, outperforming previous leaders Claude Sonnet 4 (80.2 percent) and Claude Opus 4.1 (79.4 percent).
- It achieved 61.4 percent on the computer-use benchmark OSWorld, well ahead of other models in available leaderboards.
- It achieved 100 percent on AIME 2025’s math problems when it used Python tools, although GPT-5 dominated when neither model used tools.
- On tests of visual reasoning such as GPQA-Diamond and MMMLU, Sonnet 4.5 generally outperformed the larger Claude Opus 4.1 but fell short of Google Gemini Pro 4.5 and OpenAI GPT-5.
Claude Code: Anthropic’s agentic coding tool got a design overhaul that adds a number of fresh capabilities. Notably, it comes with a software development kit — based on the same software infrastructure, toolkit, orchestration logic, and memory management that underpins Claude Code — for building other agentic tools.
- Claude Agent SDK. The new software development kit pairs Claude models with software tools for web search, file management, code deployment, and other autonomous capabilities. It provides building blocks for all of Claude Code’s functionality so you can build your own agentic applications.
- Context tracking. Agentic use cases require continuity even when inputs exceed a model’s input context limit. When a model’s message history approaches this limit, Claude Code asks the model to summarize the most critical details and passes the summary to the model as the latest input. It also removes tool results when they’re no longer needed, making room for further input.
- Memory. A new API “memory tool” enables the model to store and retrieve especially important information like project states outside the input.
- Checkpoints. Claude Code now stores checkpoints, preserving safe states that it can revert to in case of mistakes. It also added an IDE extension that can be used in VSCode and similar applications in lieu of the terminal.
Behind the news: Founded by ex-Open AI employees, Anthropic markets itself as an alternative to that company: safer, more humane, and more tasteful. Although it hasn’t stopped touting those values, the emphases have grown simpler: coding and workplace productivity. While ChatGPT may be synonymous with AI among consumers, Anthropic is focusing on software developers and businesses.
Why it matters: The coupling of Claude Sonnet 4.5 with the enhanced Claude Code reflects Anthropic’s emphasis on workplace productivity. This focus speaks to some of the business world’s anxieties: When will AI pay off for my workforce? When will it transform what they do? For now, coding (via Claude Code or a competitor) is one obvious answer.
We’re thinking: The Claude Agent SDK is a significant release that will enable many developers to build powerful agentic apps. We look forward to an explosion of Claude-based progeny!
OpenAI, Meta Diversify AI Product Lines
OpenAI and Meta, which have been content to offer standalone chatbots or tuck them into existing products, introduced dueling social video networks and other initiatives designed to boost revenue and engagement.
What’s new: OpenAI’s Sora 2 is a TikTok-style app that lets users share 10-second clips, while Meta’s Vibes enables Facebook users to generate new videos or remix existing ones. In addition, OpenAI launched ChatGPT Pulse, which creates personal briefings based on recent chats and data from connected apps like calendars, and Instant Checkout, which allows ChatGPT users to shop as they chat.
How it works: The new initiatives take advantage of existing AI capabilities to boost engagement and bring in revenue.
- Sora 2: OpenAI’s social video app, which topped the iOS App Store leaderboard over the weekend, lets users generate a limited number of 10-second, 640x480-pixel clips, while subscribers to ChatGPT Pro ($200 per month) can produce unlimited 20-second, 1920x1080-pixel clips. Users can generate their own likenesses and permit others to do so (as OpenAI CEO Sam Altman did, inspiring his audience to generate clips of him shoplifting GPUs at Target, among other antics). The company tightened restrictions on the use of anime and other characters after rightsholders complained, Altman wrote in a blog post.
- Vibes: Meta’s social video feed appears under a free tab in its Meta AI app or on the Vibes web site. Users can’t put themselves into the action, but they can generate clips based on images they upload or remix existing videos in their feed while adding music and altering visual styles. Generated videos can be posted to Instagram and Facebook.
- ChatGPT Pulse: Pulse is a new kind of personal news-and-productivity service. It tracks users’ chats, emails, and calendar entries and creates cards designed to anticipate users’ concerns and provide related news, reminders, suggestions, and tips. The service is currently limited to subscribers to ChatGPT Pro, but OpenAI says eventually it will be free for all users in some form.
- Instant Checkout: ChatGPT users who request product recommendations can buy suggested items from Etsy and Shopify without leaving the chatbot’s user interface. OpenAI earns fees on sales, a structure akin to affiliate links that generate revenue for product recommendation services like Wirecutter; the company says its commissions will not influence ChatGPT’s suggestions. Purchases made in ChatGPT are processed via the Agentic Commerce Protocol, a partnership between OpenAI and the payment processor Stripe that is similar to Google’s Agent Payments Protocol.
Behind the news: For revenue, OpenAI so far has relied on chatbot subscriptions, which account for roughly 80 percent. However, only a tiny fraction of ChatGPT’s 700 million weekly active users subscribe. Tactics such as imposing rate limits persuade some to sign up, but personal productivity, shopping commissions, and advertising offer ways to earn money from the rest.
Why it matters: Products based on generative AI are already well established, but they’re still in their infancy, and an infinite variety of AI-powered consumer products and services remains to be invented. OpenAI’s ChatGPT Pulse is a genuinely fresh idea, using agentic capabilities to deliver timely, personalized information and perspective in any domain. Both OpenAI and Facebook are experimenting with social video, giving users new ways to entertain friends and express themselves. And, of course, melding large language models with digital commerce may come to feel natural as people increasingly turn to chatbots for purchasing advice.
We’re thinking: The financial success of such AI-driven products is bound to have a powerful impact on future directions of AI research and development.
Qwen3 Goes Big (and Smaller)
Alibaba rounded out the Qwen3 family with its biggest large language model to date as well as smaller models that process text, images, video, and/or audio.
What’s new: The closed-weights Qwen3-Max gives Alibaba a foothold among the biggest large language models. Qwen3-VL-235B-A22B is an open-weights model that processes text, images, and video at the top of its size class and beyond. Qwen3-Omni, also open-weights, adds audio to the mix with outstanding results.
Qwen3-Max encompasses 1 trillion parameters trained on 36 trillion tokens. It’s available in base and instruction-tuned versions, with a reasoning version to come. Like Alibaba’s other Max models (but unlike most of the Qwen series), its weights are not available.
- Input/output: Text in (up to 262,000 tokens), text out (up to 65,536 tokens)
- Architecture and training: 1 trillion-parameter mixture-of-experts decoder, specific training data and methods undisclosed
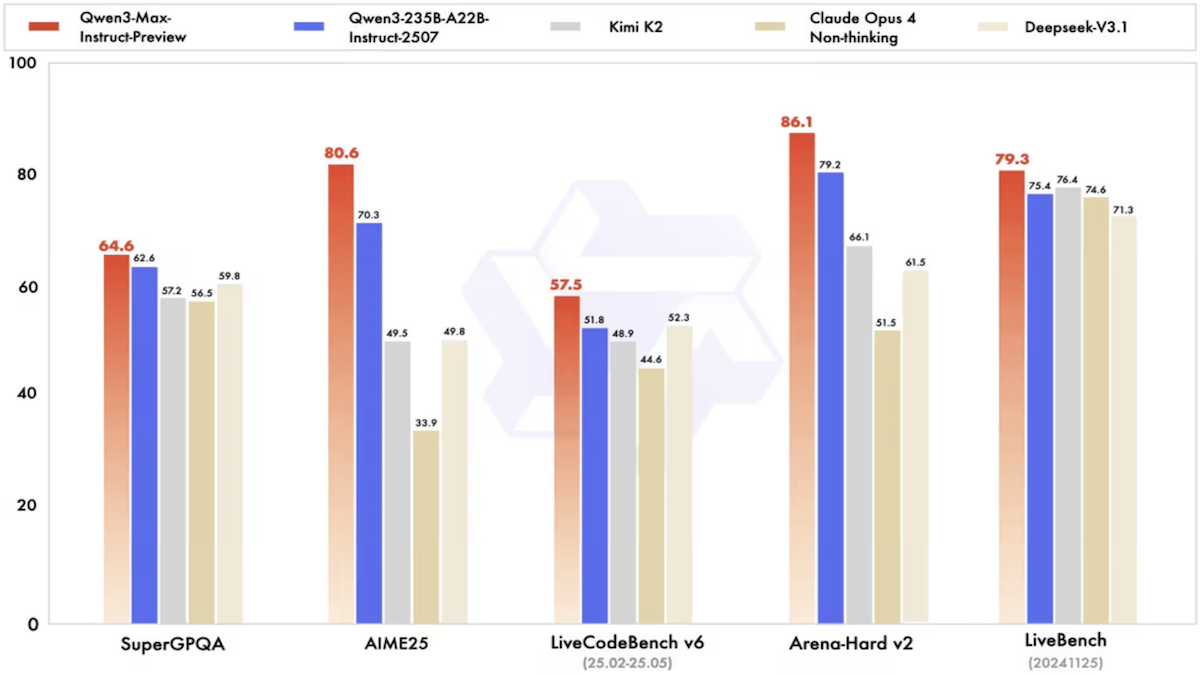
- Performance: In Alibaba’s tests, Qwen3-Max generally fell short of Google Gemini 2.5 Pro and OpenAI GPT-5 but outperformed large models from Anthropic, DeepSeek, and xAI. On Artificial Analysis’ Intelligence Index, it scored just behind the smaller Qwen3-235B-A22B.
- Availability: API access $1.20/$6.00 per 1 million input/output tokens via Alibaba Cloud in Singapore, $0.861/$3.441 per 1 million input/output tokens via Alibaba Cloud in Beijing
Qwen3-VL-235B-A22B, a vision-language variant of Qwen3-235B-A22B, is designed to drive agentic interactions that require understanding of images and videos. It comes in base, instruction-tuned, and reasoning versions.
- Input/output: Text, images, video in (up to 262,000 tokens, expandable to 1 million tokens), text out (up to 81,920 tokens)
- Architecture and training: Mixture-of-experts decoder (235 billion parameters total, 22 billion active per token), vision encoder, specific training data and methods undisclosed
- Performance: In Alibaba’s tests, Qwen3-VL-235B-A22B outperformed other open-weights models and generally matched the best available models on many image and video benchmarks, with or without reasoning capability. It established new states of the art among both open and closed models for MathVision (math problems), Design2Code (visual coding tests), and several tests of text recognition. It outperformed Gemini 2.5 Pro and OpenAI GPT-5 on tests of agentic capabilities (ScreenSpot Pro, OSWorldG, Android World), document understanding (MMLongBench-Doc, DocVQATest), and 2D/3D spatial awareness (CountBench). It performed second-best only to Gemini Pro 2.5 on the science, technology, and math portions of MMMU-Pro, visual reasoning puzzles in SimpleVQA, and video understanding challenges in VideoMMMU.
- Availability: Free for commercial and noncommercial uses under Apache 2.0 license, $0.70/$2.80 per 1 million tokens input/output via Alibaba Cloud
Qwen3-Omni-30B-A3B was pretrained on text, images, video, and audio, so it translates between them directly. It comes in instruction-tuned and reasoning versions as well as a specialized audio/video captioner model.
- Input/output: Text, images, video, or audio in (up to 65,536 tokens), text or spoken-word audio out (up to 16,384 tokens)
- Architecture and training: Mixture-of-experts transformer (30 billion parameters total, 3 billion active per token), specialized experts for multimodal and speech processing, specific training data and methods undisclosed
- Performance: Qwen3-Omni is the best-performing open-weights voice model, outperforming GPT-4o on many tests. Among 36 audio and audio-visual benchmarks, Qwen3-Omni-30B-A3B achieved state-of-the-art results on 22. In tests of mixed media understanding and voice output, its results were competitive with those of Gemini 2.5 Pro, ByteDance Seed-ASR, and OpenAI GPT-4o Transcribe.
- Availability: Free for commercial and noncommercial uses under Apache 2.0 license, $0.52/$1.99 per 1 million tokens of text input/output, $0.94/$3.67 per 1 million tokens of image-video input/text output, $4.57/$18.13 per 1 million tokens of audio input/output via Alibaba Cloud
Behind the news: Alibaba recently released Qwen3-Next, which accelerates performance by alternating attention and Gated DeltaNet layers. The new models don’t use this architecture, but it remains a potential path for future models in the Qwen family.
Why it matters: While Qwen3-Max falls short of competitors, the new open-weights multimodal models offer opportunities for developers. Qwen3-VL-235B-A22B offers low cost, versatility, and customizability, and Qwen3-Omni-30B-A3B provides a welcome option for voice applications. Alibaba has been a consistent, versatile experimenter that has put open releases first, and its new releases cover a wide range of needs.
We’re thinking: We love to see open-weights models turning in world-beating results! With their prowess in multimedia understanding, reasoning, and tool use, Qwen3-VL and Qwen3-Omni put a wide range of agentic applications within reach of all developers.
LoRA Adapters On Tap
The approach known as LoRA streamlines fine-tuning by training a small adapter that modifies a pretrained model’s weights at inference. Researchers built a model that generates such adapters directly.
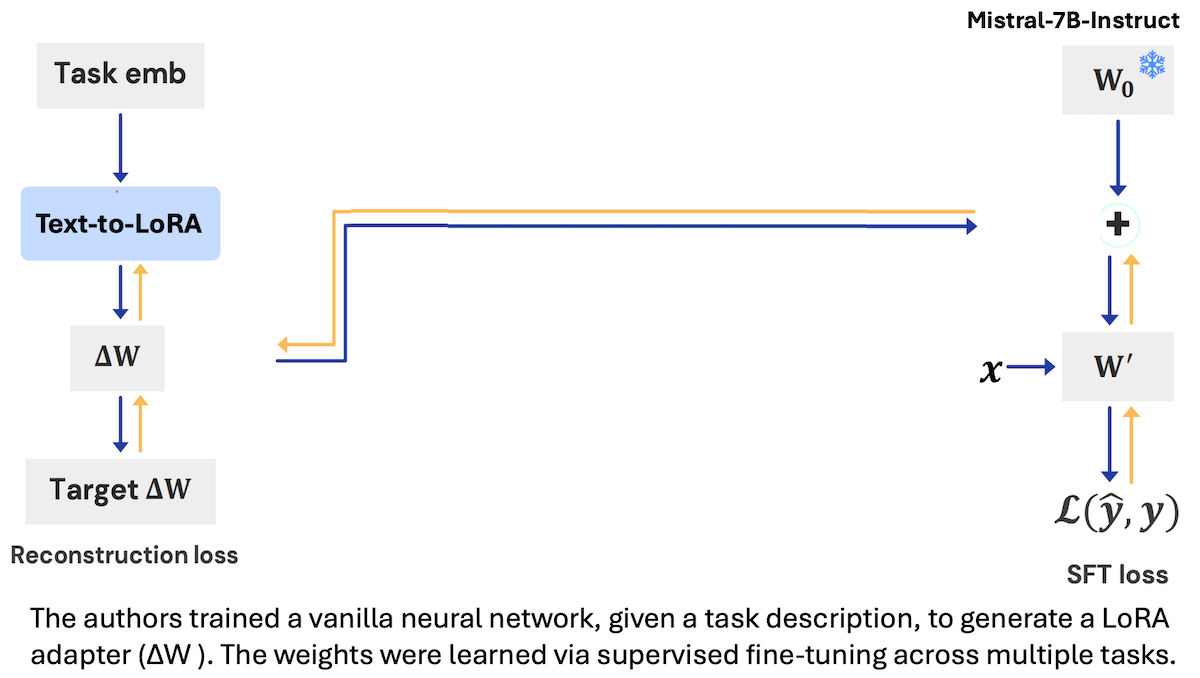
What’s new: Rujikorn Charakorn and colleagues at the Tokyo-based startup Sakana AI introduced Text-to-LoRA, a model that produces task-specific LoRA adapters based on natural language descriptions of tasks to be performed by a separate large language model.
Key insight: Typically, a LoRA adapter is trained for a particular task. However, a model can learn, given a description of a task, to generate a suitable adapter for tasks it may not have encountered in its training.
How it works: The authors trained a vanilla neural network, given text that describes a task, to produce a task-specific LoRA adapter for the large language model Mistral-7B-Instruct.
- The authors trained the network on 479 tasks such as answering questions about physics and solving math word problems. Each task consisted of 128 example input-output pairs and a description like this one for solving math word problems: “This task challenges your problem-solving abilities through mathematical reasoning. You must carefully read each scenario and systematically work through the data to compute the final outcome.”
- They generated embeddings of task descriptions by passing them to gte-large-en-v1.5, a pretrained embedding model.
- Given an embedding of a task description and embeddings that specified layers of Mistral-7B-Instruct to adapt, Text-to-LoRA learned to generate a LoRA adapter. Specifically, it learned to minimize the difference between the outputs of the LoRA-adapted Mistral-7B-Instruct and the ground truth outputs.
Results: The authors evaluated Mistral-7B-Instruct with Text-to-LoRA on 10 reasoning benchmarks (such as BoolQ, Hellaswag, and WinoGrande). They compared the results to Mistral-7B-Instruct (i) with conventional task-specific adapters, (ii) with a single adapter trained on all 479 training tasks simultaneously, (iii) unadapted but with the task description prepended to the prompt, and (iv) unadapted but with a plain prompt.
- Across all benchmarks, Mistral-7B-Instruct with Text-to-LoRA achieved 67.7 percent average accuracy. The LLM with the multi-task adapter achieved 66.3 percent. The unadapted LLM with the task description prepended to the prompt achieved 60.6 percent average accuracy, while a plain prompt yielded 55.8 percent.
- Comparing their work against conventional LoRA adapters, the authors reported results on 8 tasks (excluding GSM8K and HumanEval). Mistral-7B-Instruct with conventional adapters did best (75.8 percent). The LLM with Text-to-LoRA achieved 73.9 percent average accuracy, with the 479-task adapter 71.9 percent, and with no adapter 60.0 percent.
Why it matters: The demands placed on a model often change over time, and training new LoRA adapters to match is cumbersome. In effect, Text-to-LoRA compresses a library of LoRA adapters into a parameter-efficient hypernetwork that generalizes to arbitrary tasks. Because it generates them based on text descriptions, different descriptive phrasing can produce different styles of adaptation to emphasize, say, reasoning, format, or other constraints. In this way, Text-to-LoRA makes it easy, quick, and inexpensive to produce new adapters for idiosyncratic or shifting tasks.
We’re thinking: Training LoRA adaptors typically involves a tradeoff between specialization and generalization, and ensembles or mixtures of adapters can improve generalization. This approach offers an efficient, low-cost way to produce LoRA ensembles, which typically are expensive to train and maintain.



