
Drone Swarms Go To War, States Ban AI Mental-Health Treatments, Qwen3-Next Accelerates, Transformers Get Energized
The Batch AI News and Insights: Automated software testing is growing in importance in the era of AI-assisted coding.

Dear friends,
Automated software testing is growing in importance in the era of AI-assisted coding. Agentic coding systems accelerate development but are also unreliable. Agentic testing — where you ask AI to write tests and check your code against them — is helping. Automatically testing infrastructure software components that you intend to build on top of is especially helpful and results in more stable infrastructure and less downstream debugging.
Software testing methodologies such as Test Driven Development (TDD), a test-intensive approach that involves first writing rigorous tests for correctness and only then making progress by writing code that passes those tests, are an important way to find bugs. But it can be a lot of work to write tests. (I personally never adopted TDD for that reason.) Because AI is quite good at writing tests, agentic testing enjoys growing attention.
First, coding agents do misbehave! My teams use them a lot, and we have seen:
- Numerous bugs introduced by coding agents, including subtle infrastructure bugs that take humans weeks to find.
- A security loophole that was introduced into our production system when a coding agent made password resets easier to simplify development.
- Reward hacking, where a coding agent modified test code to make it easier to pass the tests.
- An agent running "rm *.py" in the working directory, leading to deletion of all of a project's code (which, fortunately, was backed up on github).
In the last example, when pressed, the agent apologized and agreed “that was an incredibly stupid mistake.” This made us feel better, but the damage had already been done!
I love coding agents despite such mistakes and see them making us dramatically more productive. To make them more reliable, I’ve found that prioritizing where to test helps.

I rarely write (or direct an agent to write) extensive tests for front-end code. If there's a bug, hopefully it will be easy to see and also cause little lasting damage. For example, I find generated code’s front-end bugs, say in the display of information on a web page, relatively easy to find. When the front end of a web site looks wrong, you’ll see it immediately, and you can tell the agent and have it iterate to fix it. (A more advanced technique: Use MCP to let the agent integrate with software like Playwright to automatically take screenshots, so it can autonomously see if something is wrong and debug.)
In contrast, back-end bugs are harder to find. I’ve seen subtle infrastructure bugs — for example, one that led to a corrupted database record only in certain corner cases — that took a long time to find. Putting in place rigorous tests for your infrastructure code might help spot these problems earlier and save you many hours of challenging debugging.
Bugs in software components that you intend to build on top of lead to downstream bugs that can be hard to find. Further, bugs in a component that’s deep in a software stack — and that you build multiple abstraction layers on top of — might surface only weeks or months later, long after you’ve forgotten what you were doing while building this specific component, and be really hard to identify and fix. This is why testing components deep in your software stack is especially important. Meta’s mantra “Move fast with stable infrastructure” (which replaced “move fast and break things”) still applies today. Agentic testing can help you make sure you have good infrastructure for you and others to build on!
At AI Fund and DeepLearning.AI’s recent Buildathon, we held a panel discussion with experts in agentic coding (Michele Catasta, President at Replit; Chao Peng, Principal Research Scientist at Trae; and Paxton Maeder-York, Venture Partnerships at Anthropic; moderated by AI Fund’s Eli Chen), where the speakers shared best practices. Testing was one of the topics discussed. That panel was one of my highlights of Buildathon and you can watch the video on YouTube.
Keep testing!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Build an app that works with Box content in place. In this short course, you’ll connect to the Box MCP server to discover tools, list folders, and extract fields without moving files, then evolve the solution into a multi-agent system coordinated via A2A. Sign up for free
News
Qwen3-Next Accelerates
Alibaba updated its popular Qwen3 open-weights models with a number of fresh, speed-boosting tweaks.
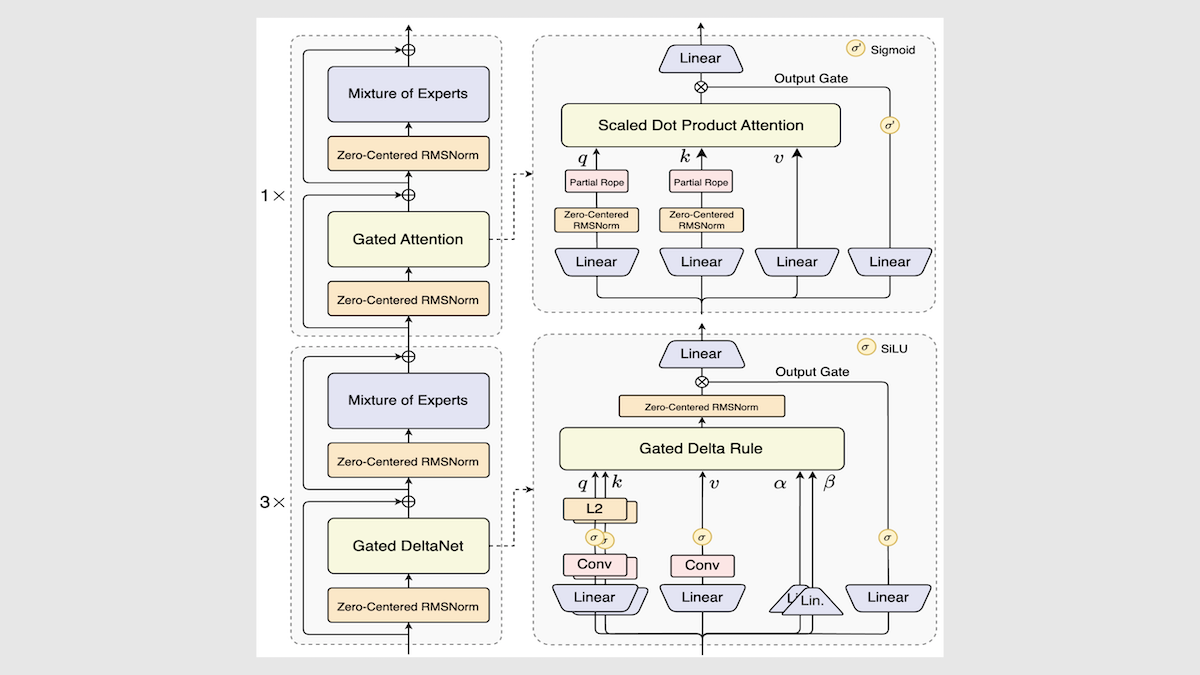
What’s new: Alibaba released weights for Qwen3-Next-80B-A3B in Instruct and Thinking variations. They incorporate some of the latest research on alternate forms of attention and mixture-of-experts approaches to use less processing power at inference.
- Input/output: Text in (pretrained on up to 262,144 tokens, extensible up to 1 million via YaRN method), text out (up to 16,384 recommended for Qwen3-Next-80B-A3B)
- Architecture: Mixture-of-experts transformer with mixed attention and Gated DeltaNet layers, 80 billion total parameters total, 3 billion parameters active per token
- Performance: Roughly 3 to 10 times faster than Qwen3-32B at inference (depending on input size) while achieving better performance in most tasks
- Availability: Weights for Qwen3-Next-80B-A3B-Thinking and Qwen3-Next-80B-A3B-Instruct available for commercial and noncommercial uses under Apache 2.0 license from HuggingFace and ModelScope
- API: Qwen3-Next-80B-A3B-Thinking $0.50/$6 per 1 million input/output tokens, Qwen3-Next-80B-A3B-Instruct $0.50/$2 per 1 million input/output tokens via Alibaba
- Undisclosed: Specific training methods, training data
How it works: The team modified the Qwen3-30B-A3B architecture and training method to increase training efficiency and stability as follows:
- The team increased the number of experts from 128 to 512, so at inference the model only uses 3.7 percent of its total parameters per token (though the number of active parameters is unchanged).
- They replaced 75 percent of the vanilla attention layers with Gated DeltaNet layers, a form of linear attention that runs slightly slower than Mamba2 but yields better performance.
- They replaced the remaining vanilla attention layers with gated attention layers. Gated attention layers add in a learned gate after computing attention, effectively enabling the model to decide which parts of the layer’s output they want to pass along to subsequent layers.
- The team pretrained this modified architecture on 15 trillion tokens of Qwen3’s training dataset to predict multiple tokens at once. (They do not specify the number but recommend predicting two at a time at inference.) They fine-tuned the models using the reinforcement learning method GSPO.
Results: Qwen3-Next models were faster than Qwen3-30B-A3B and Qwen3-32B in Alibaba’s tests. They performed in the middle of the pack in independent tests.
- Qwen3-Next showed notable speed at inference, especially with large inputs. Given 4,000 tokens of input, Qwen3-Next generated tokens as fast as Qwen3-30B-A3B and three times faster than Qwen3-32B. Given 128,000 tokens of input, it was 3 times faster than Qwen3-30B-A3B and 10 times faster than Qwen3-32B. Qwen3-Next trained much faster as well, 90.7 percent faster than Qwen3-32B and 87.7 percent faster than Qwen3-30B-A3B.
- According to the Artificial Analysis Intelligence score (an average of 10 popular benchmarks that test general knowledge, math, and coding), Qwen3-Next-80B-A3B-Thinking turned in middling performance compared to proprietary reasoning LLMs. It outperformed Gemini 2.5 Flash Thinking, Z.ai GLM 4.5, but underperformed Anthropic Claude 4 Sonnet, Gemini 2.5 Pro, and OpenAI GPT-5.
- Similarly, Qwen3-Next-80B-A3B-Instruct scored in the middle of the pack compared to proprietary non-reasoning LLMs. It outperformed OpenAI GPT-4.1, tied with DeepSeek-V3.1, and underperformed the much larger Moonshot Kimi K2.
Behind the news: Since transformers gained traction, researchers have been working to design faster variants of attention and new layers (like Mamba). However, the resulting models tend to be limited in size and performance relative to the state of the art when the innovations were proposed, sometimes because adapting them to existing GPU hardware is difficult. Qwen3-Next takes advantage of recent research without these limitations. It outperforms current large and popular models, potentially pointing a way toward future LLM architectures.
Why it matters: Qwen3-Next offers a recipe for faster inference without compromising performance. Mixture-of-experts architectures enable models to learn more while using fewer parameters at inference, increasing throughput. Swapping vanilla attention for more-efficient layers boosts throughput further, especially as context lengths increase. Predicting multiple tokens at once provides an additional edge.
We’re thinking: Rapidly rising demand for cheaper and faster token generation is pushing more teams to tune mixture-of-experts architectures so they use fewer active parameters. Such techniques will continue to grow in importance as demand for inference increases.
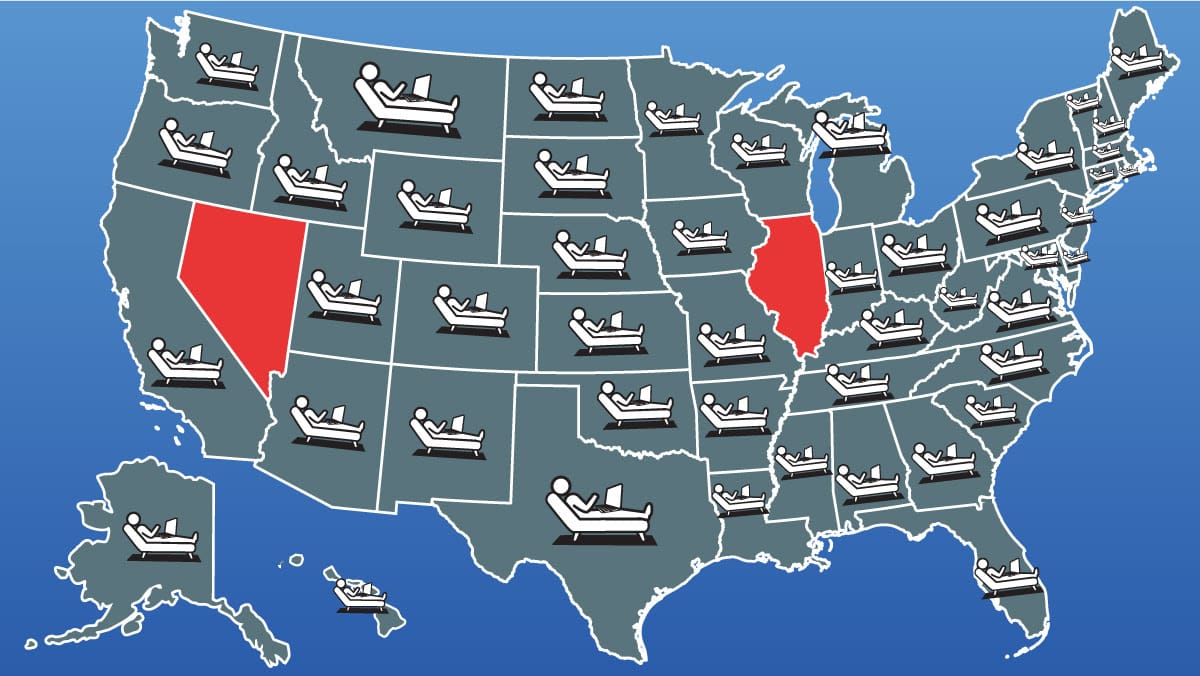
States Ban AI-Driven Treatments for Mental Health
Illinois became the second U.S. state, after Nevada, to ban AI applications that administer psychotherapy.
What’s new: Illinois passed the Wellness and Oversight for Psychological Resources Act, which prohibits uses of AI to treat mental-health conditions without a doctor’s direct participation. Violations could result in fines up to $10,000 for each use.
How it works: The bill effectively bans the use of chatbots to administer therapy on their own and restricts some other uses of AI in mental-health care, even by licensed professionals. Proponents say it will protect patients from unproven treatments and human therapists from being replaced by AI systems.
- Companies can’t advertise chatbots as therapeutic tools or offer other AI-powered therapeutic services without the involvement of a licensed professional.
- Mental health professionals may not use AI to make therapeutic decisions, detect a patient’s mental or emotional state, or participate directly in therapeutic communications. They must obtain informed consent from clients to use AI in therapy sessions that are recorded or transcribed. They can use AI freely for administrative services such as scheduling, billing, and keeping records.
Behind the news: In June, Nevada became the first U.S. state to prohibit AI in treatments for mental health, and California, New Jersey, and Pennsylvania are considering their own limits. These actions come as some experts in public and mental health warn of potential hazards posed by chatbots that deliver therapy without having established their safety and effectiveness. An April study found that many general-purpose chatbots failed to respond appropriately when given conversational prompts that simulated mental-health issues. Recent weeks have seen reports that detailed unhealthy relationships between chatbots users, and some conversations between chatbots and vulnerable people have led to harm.
Why it matters: In the absence of national laws, regulation of AI in the U.S. is proceeding state by state. The Illinois and Nevada laws essentially ban AI-driven therapy, whether it’s dispensed by general-purpose models or those that have been fine-tuned and shown to behave in ways that are consistent with accepted clinical practice. They prohibit companies from marketing poorly designed and untested AI systems as beneficial therapeutic agents, but they also prevent licensed mental-heath professionals from using specialized systems to make treatment decisions. The upshot is that helpful AI models will be unavailable to people who may benefit from them.
We’re thinking: We favor regulations based on applications rather than underlying technology. However, by banning AI-driven therapy outright, Illinois and Nevada have left no room for legitimate AI-powered applications that provide effective therapy. Large language models are helping many people with therapy-like matters. They can lower the cost of therapy, offer around-the-clock service, and alleviate shortages of qualified professionals. They’re not yet perfect replacements for human therapists, but they will improve. Banning them will do more harm than good.

Drone Swarms Go to War
Swarms of drones that coordinate with one another autonomously have become a battlefield staple in Ukraine.
What’s new: The Ukrainian army is deploying squads of weaponized drones that decide among themselves which will attack first and when. Small swarms controlled by software developed by Swarmer, a U.S.-based startup, have been targeting Russian soldiers, equipment, and infrastructure for the better part of a year, The Wall Street Journal reported.
How it works: Swarmer’s swarm-control software is designed to work with a wide variety of unmanned aerial vehicles. A human operator makes decisions about use of lethal force: “You set the target and they do the rest,” said a Ukrainian officer whose unit has used Swarmer’s technology more than 100 times. Unlike popular drone-driven light shows, in which a crowd of drones are pre-programmed to move in particular ways, Swarmer swarms adapt to one another’s motions. And unlike typical drones, which depend on cloud computing, they operate in ways that are designed to avoid enemy interference with communications. For instance, the human operator can transmit to the swarm only once per minute. The units maintain distance and avoid collisions with one another, but they navigate independently to avoid presenting an aggregate target.
- The system includes (i) an operating system that manages the security, integrity, and delivery of data that passes between drones and their human operators, (ii) an AI engine that manages swarm behavior, and (iii) a user interface for planning missions, defining targets, and authorizing use of force. It has no defensive capability and can’t take evasive action if fired upon.
- Swarmer is scaling up the number of drones its software can manage. The software is designed to manage up to 690 drones, and Swarmer is preparing for a test of 100. It has been tested successfully with up to 25. However, a typical deployment involves only 3: one for reconnaissance and two bombers that may carry as many as 25 small bombs each.
- The human crew includes an operator, a planner, and a navigator. The operator sets a target zone in which the swarm will seek enemy positions, issues commands to engage, and can abort missions. The operator orders strikes based on targets marked in video from the reconnaissance drone.
- The swarm determines when each bomber will act based on its distance from the target, remaining battery power, and available munitions. They continue to attack until they recognize that the target has been destroyed.
Behind the news: Drones are deployed en masse by both sides as Ukraine defends itself against invasion by Russia. They have changed the course of the war, as tactical and strategic goals have shifted to accommodate enormous fleets of unmanned air power, often in the form of consumer-grade equipment.
- Ukraine, especially, has embraced the technology to compensate for its smaller, less well armed forces. Hundreds of companies have sprung up to meet the rising demand.
- Drones are the leading cause of death for soldiers on both sides. They account for 70 percent to 80 percent of battlefield casualties, The New York Times reported.
- They also have many non-lethal uses. Drones monitor enemy forces; lay mines; and deliver food, water, medicine, and ammunition. Larger ones evacuate wounded and dead soldiers.
Why it matters: AI has a long history in warfare, and drone swarms are only the latest of what promises to be an ongoing stream of military uses of the technology. Yet the increasing autonomy of military drone systems poses difficult challenges, both practical and ethical. Swarmer’s software keeps humans in the loop to make firing decisions but, driven by the brutal logic of armed conflict, drones seem bound to become more widespread, capable, and autonomous.
We’re thinking: War is tragic. At the same time, democratic nations must have the means to defend themselves, and we support the Ukrainian people in their struggle to defend their country.
Transformers Energized
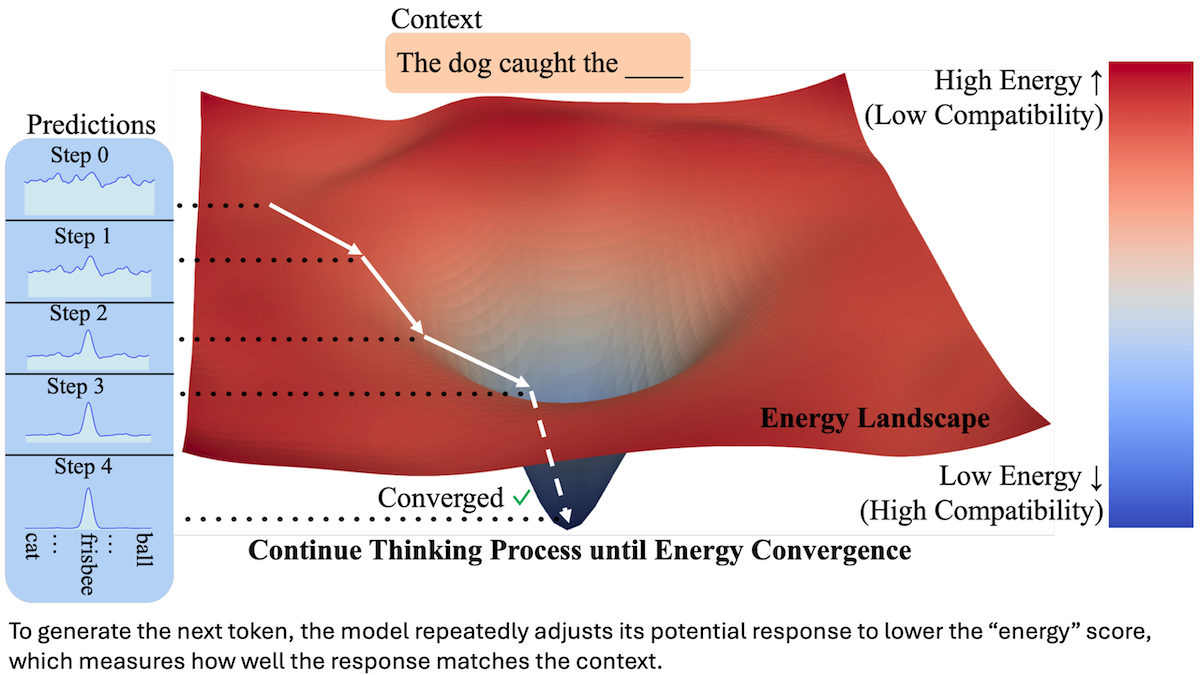
A new type of transformer can check its work. Instead of guessing the next output token in one shot like a typical transformer, it starts with a rough version of the token and improves it step by step.
What’s new: Alexi Gladstone and colleagues at University of Virginia, University of Illinois Urbana-Champaign, Amazon, Stanford, and Harvard proposed the Energy-Based Transformer (EBT). Early experiments show that it scales more efficiently than transformers at relatively small sizes.
Energy-based model basics: For a given input context paired with a candidate response (for example, a prompt and potential next token), an energy-based model produces a number called “energy” that represents how likely the potential next token would follow the prompt. During training, the model learns to assign low energy if a context/potential-response pair is very likely and high energy if it’s not.
Key insight: A typical transformer is trained to predict the next token directly, while an energy-based model learns how to score an input text. How would a researcher use an energy-based model to predict the next text token? A naive way would be to measure the energy of an input prompt with a random token, randomly modify the text token a number of times, and select the prompt-token combination with the lowest energy. Instead of random modification, a model can use gradient descent repeatedly to compute the change needed to decrease the token’s energy. This process enables the model to refine the token over several steps, ultimately producing a token with low energy (and high likelihood to follow the previous text).
How it works: Among other models, the authors trained a 44 million-parameter autoregressive EBT on the RedPajama-Data-v2 dataset of 32 billion text tokens scraped from the web. As input, EBT received a sequence of tokens and a probability vector (for the next token). It learned to output an energy score that measured the likelihood that the predicted next token would follow the context.
- During training, given a text prompt and a random guess for the probability vector, the model computed the energy. It refined the vector (leaving the model weights unchanged) by backpropagating to compute the change in the vector needed to decrease the predicted energy, and then it updated the vector. It repeated this process for a fixed number of steps, producing a predicted probability vector.
- The loss function encouraged the model to minimize the difference between the predicted probability vector and the ground-truth vector (1 for the right token, 0 for all others).
- At inference, given an input, the model predicted the next token by starting with a random probability vector and refining it through a fixed number of steps.
Results: The authors compared EBTs and transformers of the same sizes and trained on the same numbers of tokens by measuring perplexity (a measure of the likelihood that a model will predict the next word, lower is better) on several benchmarks including math problems, question answering, and reading comprehension. Overall, EBT proved to be better at generalization but worse at generating text that followed the training data’s distribution. EBTs in the sizes tested proved to be significantly less compute-efficient than transformers, but they scaled better, and larger versions may be more efficient than transformers.
- On three out of four popular benchmarks, the EBT achieved better perplexity than a vanilla transformer of the same size and trained on the same number of tokens. The EBT beat the transformer on GSM8K math problems (43.3 to 49.6), BIG-bench Elementary Math QA (72.6 to 79.8), and BIG-bench Dyck Languages, which tests closing brackets or parentheses accurately (125.3 to 131.5). On the SQuAD test of reading comprehension, EBT underperformed the transformer (53.1 to 52.3).
- On a held-out portion of the dataset, the EBT achieved slightly worse perplexity than the transformer (33.43 to 31.36).
- The authors trained several EBTs and transformers using model sizes and training-step counts dictated by transformer scaling laws and trained the models using roughly 1016 to 1020 FLOPs. The EBTs required about 10 times more FLOPs than transformers to reach the same perplexity. However, per additional FLOP, the EBTs’ perplexity improved 3 percent faster than the transformers’, so larger EBTs trained on more data for more steps may achieve higher perplexity using fewer FLOPs.
- The authors built autoregressive video models and vision transformers with similarly promising results.
Why it matters: This work offers intriguing possibilities for higher performance at larger scales. A typical transformer learns to predict the next token directly, but that locks it into a single forward pass per output token and provides no built-in measure of whether the prediction is good. In contrast, EBT learns to assign a score that it uses both to generate tokens (by iteratively lowering their energy) and to verify them (by checking if the energy is high). Work remains to learn whether larger EBTs can be more compute-efficient.
We’re thinking: When it comes to energy, AI research is a renewable resource!



