China Questions Nvidia, When Models Memorize, Mixture of Video Experts, OpenAI & Oracle Join Forces
The Batch AI News and Insights: On Saturday at the Buildathon [http://buildathon.ai] hosted by AI Fund and DeepLearning.AI, over 100 developers competed to build software products quickly using AI assisted coding.

Dear friends,
On Saturday at the Buildathon hosted by AI Fund and DeepLearning.AI, over 100 developers competed to build software products quickly using AI assisted coding. I was inspired to see developers build functional products in just 1-2 hours. The best practices for rapid engineering are changing quickly along with the tools, and I loved the hallway conversations sharing tips with other developers on using AI to code!
The competitors raced to fulfill product specs like this one (you can see the full list here):
Project: Codebase Time Machine
Description: Navigate any codebase through time, understanding evolution of features and architectural decisions.
Requirements:
- Clone repo and analyze full git history
- Build semantic understanding of code changes over time
- Answer questions like “Why was this pattern introduced?” or “Show me how auth evolved”
- Visualize code ownership and complexity trends
- Link commits to business features/decisions
Teams had 6½ hours to build 5 products. And many of them managed to do exactly that! They created fully functional applications with good UIs and sometimes embellishments.
What excites me most isn’t just what can now be built in a few hours. Rather, it is that, if AI assistance lets us build basic but fully functional products this quickly, then imagine what can now be done in a week, or a month, or six months. If the teams that participated in the Buildathon had this velocity of execution and iterated over multiple cycles of getting customer feedback and using that to improve the product, imagine how quickly it is now possible to build great products.
Owning proprietary software has long been a moat for businesses, because it has been hard to write complex software. Now, as AI assistance enables rapid engineering, this moat is weakening.

While many members of the winning teams had computer science backgrounds — which does provide an edge — not all did. Team members who took home prizes included a high school senior, a product manager, and a healthcare entrepreneur who initially posted on Discord that he was “over his skis” as someone who “isn't a coder.” I was thrilled that multiple participants told me they exceeded their own expectations and discovered they can now build faster than they realized. If you haven’t yet pushed yourself to build quickly using agentic coding tools, you, too, might be surprised at what you can do!
At AI Fund and DeepLearning.AI, we pride ourselves on building and iterating quickly. At the Buildathon, I saw many teams execute quickly using a wide range of tools including Claude Code, GPT-5, Replit, Cursor, Windsurf, Trae, and many others.
I offer my hearty congratulations to all the winners!
- 1st Place: Milind Pathak, Mukul Pathak, and Sapna Sangmitra (Team Vibe-as-a-Service), a team of three family members. They also received an award for Best Design.
- 2nd Place: David Schuster, Massimiliano Viola, and Manvik Pasula. (Team Two Coders and a Finance Guy).
- Solo Participant Award: Ivelina Dimova, who had just flown to San Francisco from Portugal, and who worked on the 5 projects not sequentially, but in parallel!
- Graph Thinking Award: Divya Mahajan, Terresa Pan, and Achin Gupta (Team A-sync).
- Honorable mentions went to finalists Alec Hewitt, Juan Martinez, Mark Watson and Sophia Tang (Team Secret Agents) and Yuanyuan Pan, Jack Lin, and Xi Huang (Team Can Kids).
To everyone who participated, thank you! Through events like these, I hope we can all learn from each other, encourage each other, invent new best practices, and spread the word about where agentic coding is taking software engineering.
Keep building!
Andrew
P.S. AI Dev 25 is coming to New York City on November 14! 1,200+ developers will dive into topics like AI-assisted coding, agentic AI, context engineering, multimodal AI, and fintech applications. Tickets here: ai-dev.deeplearning.ai
A MESSAGE FROM DEEPLEARNING.AI

AI Dev 25, hosted by Andrew Ng and DeepLearning.AI, hits New York City on November 14! Join 1,200+ AI developers for a day full of technical keynotes, hands-on workshops, live demos, and a new Fintech track. Limited Early Bird tickets are available now. Get your tickets here
News

China Reconsiders U.S. AI Processors
Nvidia and AMD, having obtained the U.S. government’s permission to resume selling AI processors in China, received a cool welcome there.
What’s new: China’s government, which is wary of U.S. control over the country’s supply of high-end GPUs, is requiring Nvidia processors to undergo a security review, The Wall Street Journal reported. While the review is underway, the authorities are urging Chinese AI companies to buy domestic GPUs. DeepSeek reportedly tried and failed to use China-native Huawei GPUs to train DeepSeek-R2, the follow-up to its DeepSeek-R1 model, which has delayed the project, according to Financial Times.
How it works: The Chinese government’s resistance to AI processors from U.S. vendors signals rising confidence in the nation’s AI capabilities, as the U.S. seeks to return to selling advanced processors in China after blocking such sales in recent months. China is helping the domestic semiconductor industry to compete against U.S. designers like Nvidia and AMD and the Taiwanese manufacturer TSMC, which fabricates their products, by providing funds and tax incentives and applying pressure to Chinese AI companies to buy processors made domestically. Meanwhile, Chinese vendors aim to close the performance gap between their products and those of U.S. competitors.
- China raised security concerns about U.S. processors. The government required Nvidia to explain alleged “backdoor security risks” of its H20 processor, which is designed to comply with U.S. export restrictions. China cited information it said it had obtained from U.S. artificial intelligence experts that the H20 could be shut down remotely and used to track users’ locations. Nvidia disputed those claims. (The H20’s processing power is roughly comparable with that of the Huawei Ascend 910B/C and less than that of Nvidia’s most advanced products, but its memory capacity and bandwidth are superior to Huawei’s best and closer to its Nvidia peers.)
- China questioned domestic technology firms including Baidu, ByteDance, and Tencent about their desires to use U.S. processors.
- China’s scrutiny of U.S. processors could set back Nvidia. In July, the company placed orders to manufacture 300,000 H20 chipsets and warned customers that demand might outstrip supply.
Behind the news: The U.S. government restricted sales of U.S. AI processors to China in 2022. The Trump administration tightened the restriction but recently reversed course.
- In April, the White House effectively banned sales to China of advanced chips that use U.S. technology by making them subject to export licenses, which apparently were not forthcoming.
- In recent weeks, the White House lifted the ban. In return, China agreed to sell to the U.S. rare-earth minerals and magnets derived from them, which are critical components in a wide range of consumer and industrial devices including smartphones, hard disks, and electric cars. In an unusual arrangement, U.S. chip vendors will be required to pay to the U.S. government an export license fee of 15 percent of their revenue from sales to China.
- Nvidia is developing a scaled-down, low-cost processor for the Chinese market based on its upcoming Blackwell chip architecture. The White House said it may allow Nvidia to export such processors to China.
Why it matters: The U.S. and China are wary that the other will gain a strategic advantage in technological, economic, or military power. Leadership in AI is central to all three areas. While U.S. AI companies have developed cutting-edge proprietary models, their counterparts in China have pulled ahead in open models on which anyone can build applications free of charge. But processors remain a sticking point. Spurred by U.S. export controls and policy shifts, which have made the U.S. an unreliable supplier, China is doubling down on its own semiconductor industry in hope of catching up with — and advancing beyond — Nvidia and TSMC.
We’re thinking: Developers around the world use open-weights models from China. Whether they will also adopt AI processors from China is an open question.

Mixture of Video Experts
The mixture-of-experts approach that has boosted the performance of large language models may do the same for video generation.
What’s new: Alibaba released Wan 2.2, an open-weights family of video generation models that includes versions built on a novel mixture-of-experts (MoE) flow-matching architecture. Wan2.2-T2V-A14B generates video from text input, Wan2.2-I2V-A14B generates video from images, and Wan2.2-TI2V-5B generates video from either text or images. At 5 billion parameters, Wan2.2-TI2V-5B runs on consumer GPUs.
- Input/output: Wan2.2-T2V-A14B: Text up to 512 tokens in, video up to 5 second out (30 frames per second, up to 1280x720 pixels per frame). Wan2.2-I2V-A14B: Images up to 1280x720 pixels in, video up to 5 seconds out (30 frames per second, up to 1280x720 pixels per frame). Wan2.2-TI2V-5B: Text up to 512 tokens and/or images up to 1280x704 pixels in, video up to 5 seconds out (24 frames per second, 1280x704 pixels per frame).
- Architecture: UMT5 transformer to encode text, 3D convolutional variational autoencoder (VAE) to encode and decode images, flow-matching model to generate output: MoE transformer, 27 billion parameters total, 14 billion active per token (Wan2.2-T2V-A14B and Wan2.2-I2V-A14B) or transformer (Wan2.2-TI2V-5B).
- Availability: Web interface (free), weights available via HuggingFace and ModelScope for commercial and non-commercial uses under Apache 2.0 license, API (MoE models only) $0.02 per second of 480p output, $0.10 per second of 1080p output (API only)
- Undisclosed: VAE parameter count, training data, differences in training methods between Wan 2.2 and the earlier Wan 2.1
How it works: The team pretrained the VAE to encode and decode images. They pretrained the flow-matching model, given a video embedding from the VAE with noise added and a text embedding from UMT5, to remove the noise over several steps.
- The MoE model has two experts: one for very noisy inputs and one for less noisy inputs. One expert generates the objects and their positions across a video, the other handles details.
- To determine which expert to use, the model computes the signal-to-noise ratio of the noisy embedding. Specifically, it starts with the high-noise expert, determines the time step at which the proportion of noise has fallen by half, and switches to the low-noise expert after that time step.
- At inference, the VAE embeds an input image (if applicable) and UMT5 embeds input text (if applicable). The model concatenates the image embedding (if applicable) with an embedding of noise. Given the noisy embedding and text embedding, the flow-matching model removes noise over several steps. Finally, the VAE decodes the denoised embedding to produce video output.
Results: Results for Wan 2.2 are limited. The team shared only the performance of the MoE models on a proprietary benchmark, Wan-Bench-2.0, whose mechanics, categories, and units it has not yet described. The team compared Wan2.2-T2V-A14B to competitors including Bytedance Seedance 1.0, Kuaishou KLING 2.0, and OpenAI Sora.
- For esthetic quality, Wan2.2-T2V-A14B (85.3) outperformed second-best Seedance 1.0 (84.3).
- It also achieved the highest scores for dynamic output, rendered text, and the prompt control over the camera.
- For video fidelity, Wan2.2-T2V-A14B (73.7) came in second to Seedance (81.8).
Behind the news: Open models for video generation have been proliferating. Within the last year, there are Mochi, HunyuanVideo, LTX-Video, pyramid-flow-sd3, CogVideoX, and more.
Why it matters: MoE architectures have become popular for their superior performance in text generation. Selecting the expert(s) to use for a given input often is done either by a router that learns which expert(s) work best for a given token or based on the input data type. This work is closer to the latter. The model selects the appropriate expert based on the noise in the input.
We’re thinking: Video generation is exploding! Proprietary systems generally have made deeper inroads into the professional studios, but open models like this show great promise.

OpenAI Turns to Oracle for Compute
OpenAI is working with Oracle to build its next chunk of processing power, a $30 billion outgrowth of the partners’ $500 billion Stargate project and a sign of OpenAI’s ongoing thirst for computation.
What’s new: OpenAI and Oracle plan to build data-center capacity that will consume 4.5 gigawatts of electrical power, an order of magnitude more than one of the largest data centers under construction Microsoft, which currently provides OpenAI’s computational muscle. The locations have not yet been announced.
How it works: The plan follows the successful launch of an OpenAI-Oracle data center built in Abilene, Texas, that serves as a proof of concept. That project will draw 1.2 gigawatts when it’s finished next year.
- OpenAI will pay Oracle $30 billion annually, The Wall Street Journal reported.
- OpenAI wrote in a blog post that it expects to exceed its planned $500 billion data-center buildout dubbed Stargate, and that it’s assessing sites with Stargate partner SoftBank.
- In October 2024, Altman complained in a Reddit Ask Me Anything session that a lack of processing power has delayed the company’s products.
Behind the news: Stargate, a partnership among OpenAI, Oracle, and Softbank, was announced by President Trump at the White House alongside the executive order that called for the U.S. government’s recent AI action plan.
- The partners aimed to spend $500 billion over four years to build 20 data centers. OpenAI would receive processing power, Oracle would provide hardware and software infrastructure, and SoftBank would secure financing.
- Other participants in Stargate include the Colorado-based builder Crusoe, Emirati AI-investment fund MGX, OpenAI’s infrastructure partner Microsoft, and Nvidia.
Why it matters: Staying at the forefront of AI requires immense amounts of computation, despite innovations in more compute-efficient model architectures and training and inference techniques. But how to get it? For OpenAI, the answer is forming strong ties to large-scale providers of cloud computing; first Microsoft, now Oracle. The OpenAI-Oracle partnership enables OpenAI to continue to develop models at pace and at scale, while it enables Oracle to gain experience and credibility as a provider of large-scale computing for cutting-edge AI.
We’re thinking: OpenAI’s plan to build 20 giant data centers — even more, based on the company’s latest statement — poses a major challenge to existing energy resources. Having SoftBank as a partner may be a significant advantage as that company ramps up its investments in power generation specifically for AI.
Does Your Model Generalize or Memorize?
Benchmarks can measure how well large language models apply what they’ve learned from their training data to new data, but it’s harder to measure the degree to which they simply memorized their training data. New work proposes a way to gauge memorization.
What’s new: John X. Morris and colleagues at Meta, Google, Cornell University, and Nvidia developed a method that measures the number of bits a model memorizes during training.
Key insight: A model’s negative log likelihood is equal to the minimum number of bits needed to represent a given piece of data. The more likely the model is to generate the data, the fewer bits needed to represent it. If, to represent a given output, a hypothetical best model requires more bits than a trained model, then the trained model must have memorized that many bits of that output. The best model is hypothetical, but a better-performing model can stand in for it. The difference in the numbers of bits used to represent the output by this superior model and the trained model is a lower bound on the number of bits the trained model has memorized.
How it works: The authors trained hundreds of GPT-2 style models to predict the next token in two text datasets: (i) a synthetic dataset of 64-token strings in which each token was generated randomly and (ii) the FineWeb dataset of text from the web, its examples truncated to 64 tokens and deduplicated. They trained models from 100,000 to 20 million parameters on subsets of these datasets from 16,000 to 4 million examples. Then they computed the how much of the datasets the models had memorized:
- The authors computed the number of bits needed to represent each training example based on the likelihoods of the trained model and a superior model. For models trained on synthetic data, the superior model was the distribution used to generate the data. For models trained on a subset of FineWeb, they used GPT-2 trained on all FineWeb examples (after truncation and deduplication).
- They subtracted the number of bits computed for the superior model from the number computed for the trained model. A positive difference indicated the amount of memorization. A zero or negative difference indicated that memorization did not occur.
- To find the amount of data the model had memorized. they summed the number of bits memorized per example.
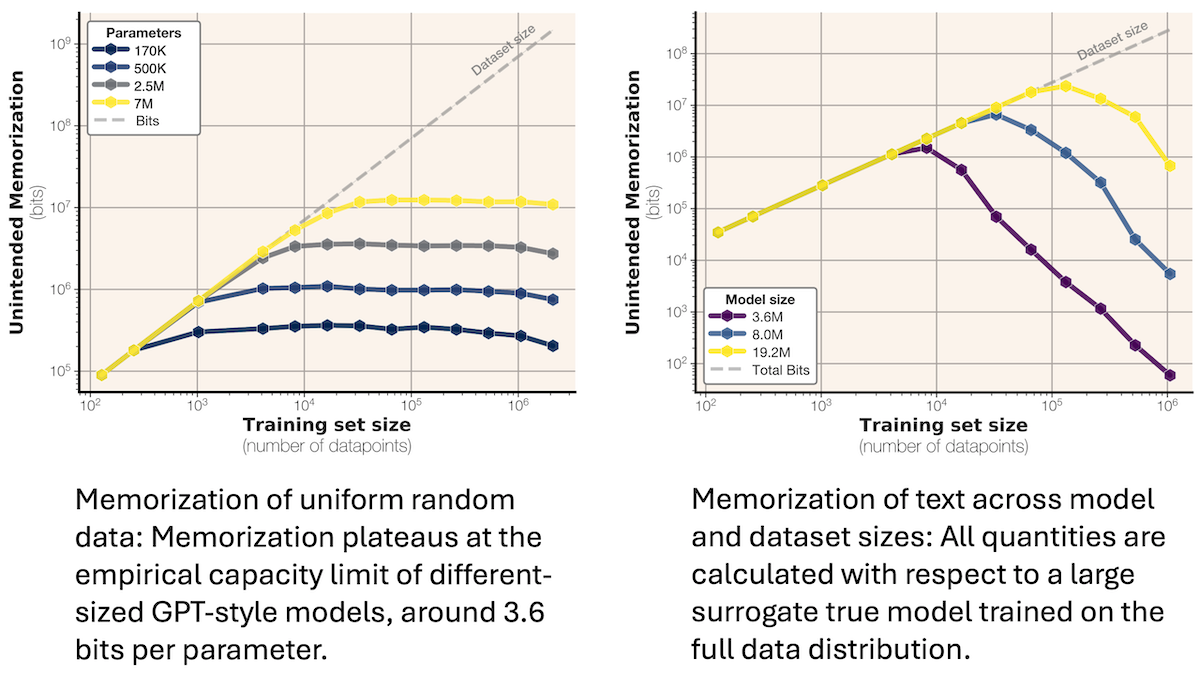
Results: The maximum number of bits a model memorized rose linearly with its parameter count regardless of the training dataset, amount of training data, or model size.
- Trained on synthetic data, a model’s memorization increased linearly and then plateaued after a certain amount of training data.
- Maximum memorization was approximately 3.5 to 3.6 bits per parameter (their models used 16 bits to represent each parameter).
- Trained on FineWeb, a model’s memorization increased linearly with the amount of training data before decreasing as the model started to generalize (that is, the number of bits memorized per parameter fell and benchmark scores rose). This result showed that models memorize until they reach a maximum capacity and then start to generalize.
Why it matters: Some previous efforts to measure memorization calculated the percentage of examples for which, given an initial sequence of tokens, a model would generate the rest. However, generating a repetitive sequence like “dog dog dog…” does not mean that a model has memorized it, and solving a simple arithmetic problem does not mean the model has memorized it or even encountered it in its training data. This work provides a theoretical basis for estimating how much of their training sets models memorize. It also lays a foundation for further work to reduce memorization without increasing the sizes of training datasets.
We’re thinking: It’s well known that more training data helps models to generalize. This work shows how to estimate the amount of data necessary before models begin to generalize.