GPT-5’s Rough Takeoff, AI Video Blockbusters, India’s Homegrown LLMs, Synthetic Data Generation
The Batch AI News and Insights: Just as many businesses are transforming to become more capable by using AI, universities are too.

Dear friends,
Just as many businesses are transforming to become more capable by using AI, universities are too. I recently visited the UK to receive an honorary doctorate from the University of Exeter’s Faculty of Environment, Science and Economy. The name of this faculty stood out to me as a particularly forward-looking way to organize an academic division. Having Computer Science sit alongside Environmental Science and the Business School creates natural opportunities for collaboration across these fields.
Leveraging AI leads a university to do things differently. Speaking with Vice Chancellor Lisa Roberts, Deputy Vice Chancellor Timothy Quine, and CS Department Head Andrew Howes, I was struck by the university leadership’s pragmatic and enthusiastic embrace of AI. This is not a group whose primary worry is whether students will cheat using AI. This is a group that is thinking about how to create a student body that is empowered through AI, whether by teaching more students to code, helping them use AI tools effectively, or showing them what’s newly possible in their disciplines.
Exeter is a wonderful place to create synergies between AI, environmental science, and business. It hosts 5 of the world’s top 21 most influential climate scientists according to Reuters, and its scholars are major contributors to reports by the UN’s IPCC (Intergovernmental Panel on Climate Change) as well as pioneers in numerous areas of climate research including geoengineering, which I wrote about previously. Its Centre for Environmental Intelligence, a partnership with the Met Office (the UK’s national weather service), applies AI to massive climate datasets. More work like this is needed to understand climate change and strategies for mitigation and adaptation. Add to this its Business School — named Business School of the Year by the consultancy Times Higher Education — and you have the ingredients for building applications and pursuing interdisciplinary studies that span technological, environmental, and economic realities.

Having been born in the UK and spent most of my career in Silicon Valley, I find it exciting to see Exeter’s leadership embrace AI with an enthusiasm I more often associate with California. The UK has always punched above its weight in research, and seeing that tradition continue in the AI era is encouraging.
Just as every company is becoming an AI company, every university must become an AI university — not just teaching AI, but using it to advance every field of study. This doesn’t mean abandoning disciplinary expertise. It means maintaining technical excellence while ensuring AI enhances every field.
Like almost all other universities and businesses worldwide, Exeter’s AI transformation is just beginning. But the enthusiastic embrace of AI by its leadership will give it momentum. As someone who is proud to be an honorary graduate of the university, I look forward to seeing what comes next!
Keep building,
Andrew
A MESSAGE FROM DEEPLEARNING.AI
Build working GenAI app prototypes in hours, not weeks. Turn Python scripts into interactive web apps using Streamlit and Snowflake's Cortex AI, and deploy to Snowflake or Streamlit Cloud for user feedback. Learn more and enroll now!
News
GPT-5 Takeoff Encounters Turbulence
OpenAI launched GPT-5, the highly anticipated successor to its groundbreaking series of large language models, but glitches in the rollout left many early users disappointed and frustrated.
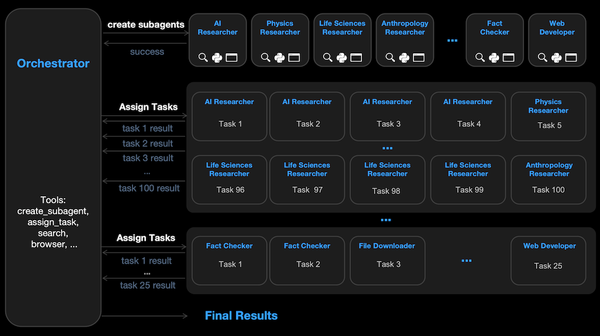
What’s new: Rather than a family of models, GPT-5 is a family of systems — GPT-5, GPT-5 Mini, GPT-5 Nano, and GPT-5 Pro — that include non-reasoning and variable-reasoning models along with a router that switches between them automatically depending on the input. OpenAI made GPT-5 the only option in the ChatGPT user interface without prior notice, but the router failed right out of the gate, causing the company to reinstate ChatGPT access to earlier models for paid users.
- Input/output: Text and images in (up to 272,000 tokens), text out (up to 128,000 tokens including reasoning and response, 122 tokens per second, 72 seconds to first token)
- Performance: Outperforms previous OpenAI models on most benchmarks reported; tops competing models on some benchmarks of math, coding, and multimodal abilities as well as health knowledge; reduced hallucinations
- Features: Developer options include four levels of reasoning, three levels of verbosity (output length), tool calling via JSON or natural language, selectable non-reasoning and reasoning models, summaries of reasoning tokens
- Availability/price: Via API GPT-5 $1.25/$0.13/$10 per million input/cached/output tokens, GPT-5 Mini $0.25/$0.025/$2 per million input/cached/output tokens, GPT-5 Nano $0.05/$0.005/$0.40 per million input/cached/output tokens; via ChatGPT free limited access; via ChatGPT Pro $200/month unlimited access to GPT-5 and GPT-5 Pro
- Knowledge cutoff: September 30, 2024 (GPT-5), May 30, 2024 (GPT-5 Mini, GPT-5 Nano)
- Undisclosed: Model, router, and system architectures; training methods and data
How it works: OpenAI revealed few details about GPT-5’s architecture and training except “safe completions” fine-tuning to balance safety and helpfulness, which is documented in a paper.
- The router selects between non-reasoning and reasoning models based on input “type,” “complexity,” tool requirements, and explicit user intent (such as a prompt to “think hard”). The router learns from user behavior. When ChatGPT users reach usage limits, the router directs queries to mini versions of each model.
- The team trained the models on web content, licensed data, and human and generated input. They fine-tuned them to reason via reinforcement learning.
- In addition, they fine-tuned the models to prefer helpful but “safe” answers over refusals to answer, an approach the team calls safe completions. Given a potentially problematic input, a model aims to respond usefully while staying within safety guidelines, explains when it must refuse, and suggests related outputs that don’t touch on topics it has been trained to avoid.
Results: GPT-5 topped some benchmarks according to OpenAI's evaluations. However, it fell short of competing models on some measures of abstract reasoning in independent tests.
- On SWE-bench (software engineering tasks), GPT-5 (74.9 percent accuracy) outperformed Claude Opus 4.1 (74.5 percent accuracy).
- On AIME 2025 (competition math problems), GPT-5 set to high reasoning without tools (94.6 percent accuracy) surpassed o3 set to high reasoning (88.9 percent).
- On the EQ-Bench Creative Writing v3 benchmark (leaderboard here), GPT-5 with an unspecified reasoning level (90.30) outperformed o3 (87.65), Gemini-2.5-pro (86.00), and Claude Opus 4 (83.75).
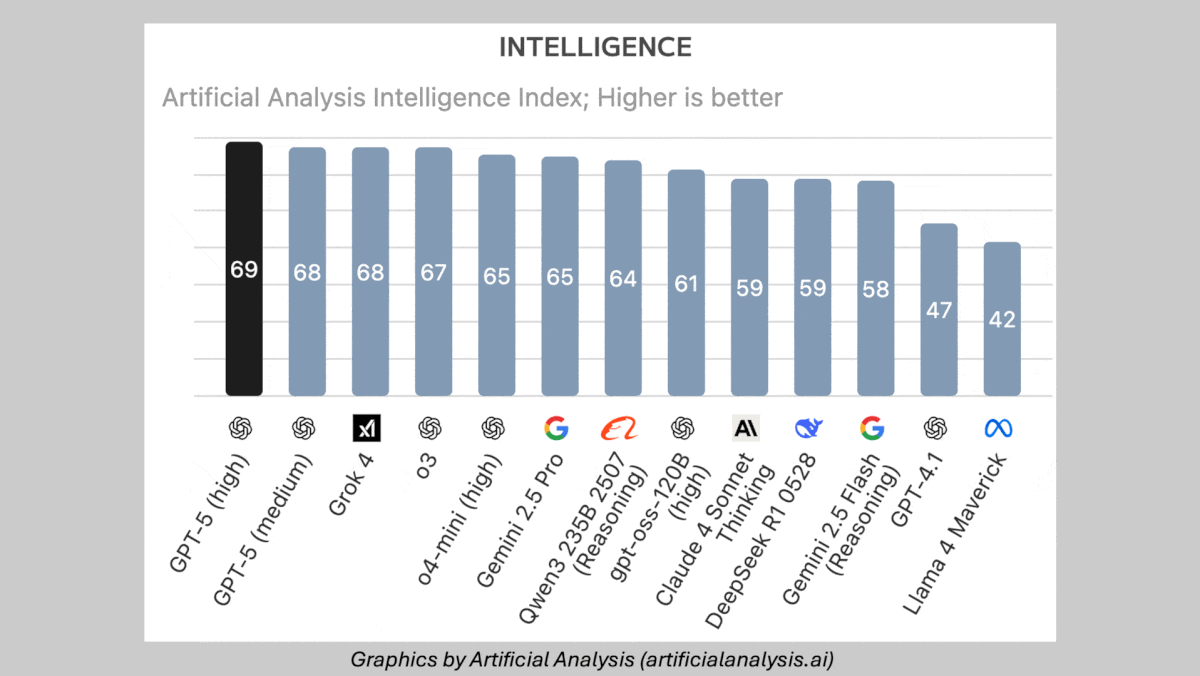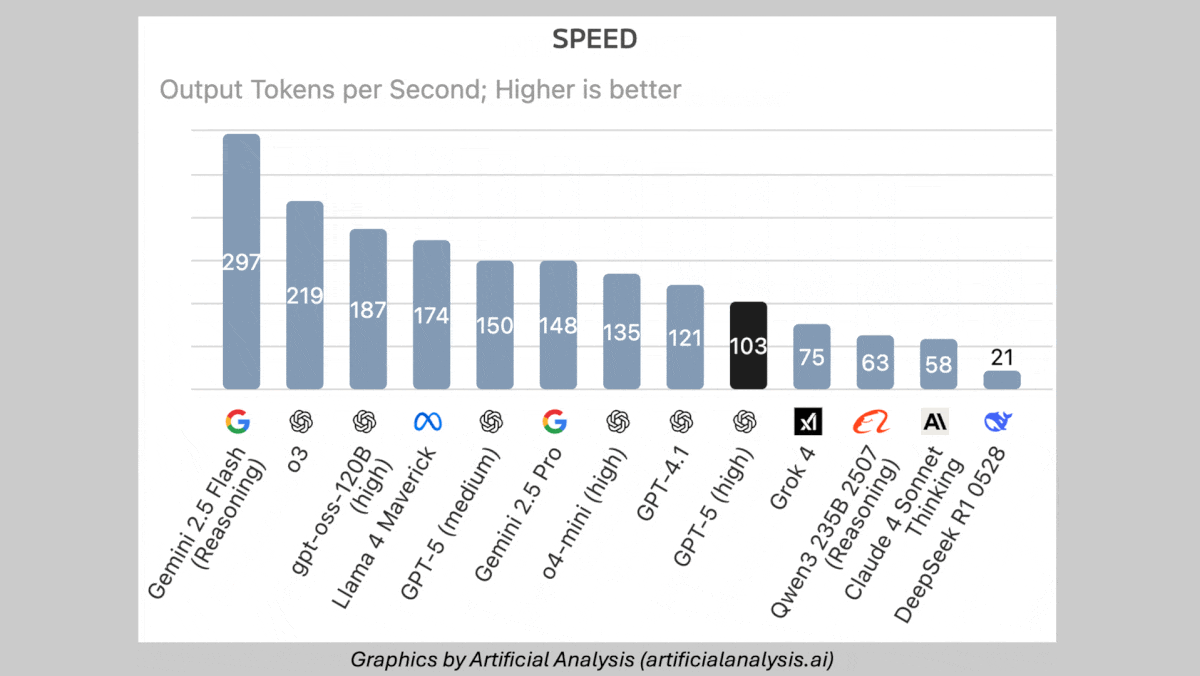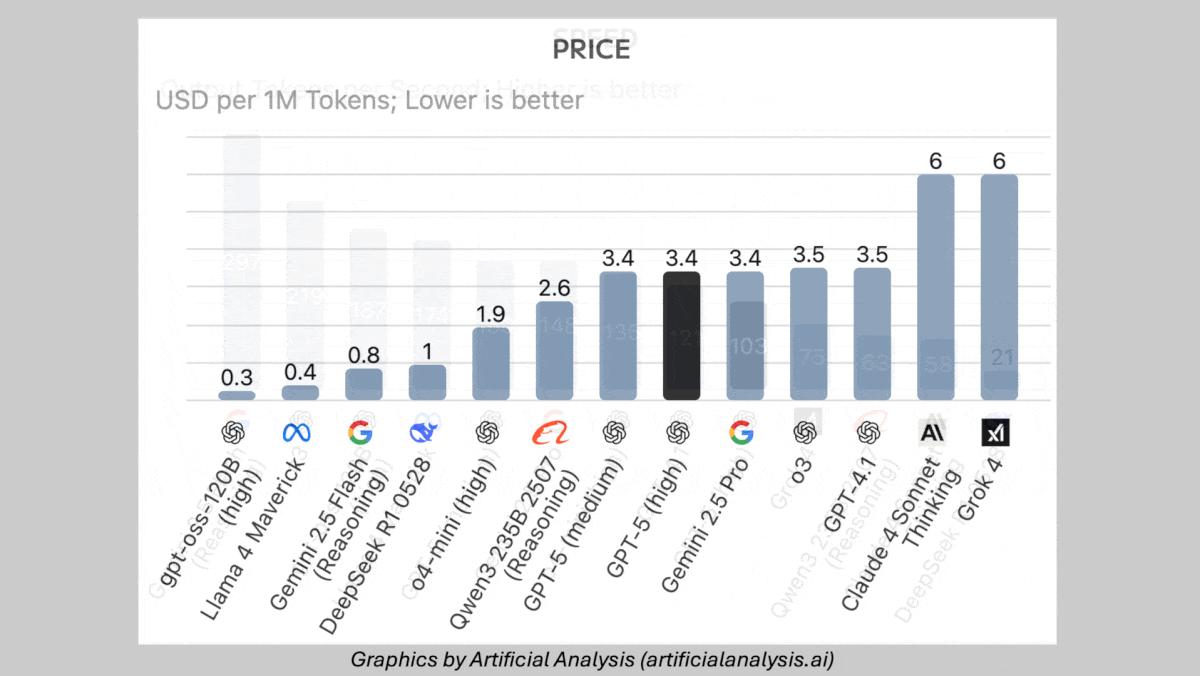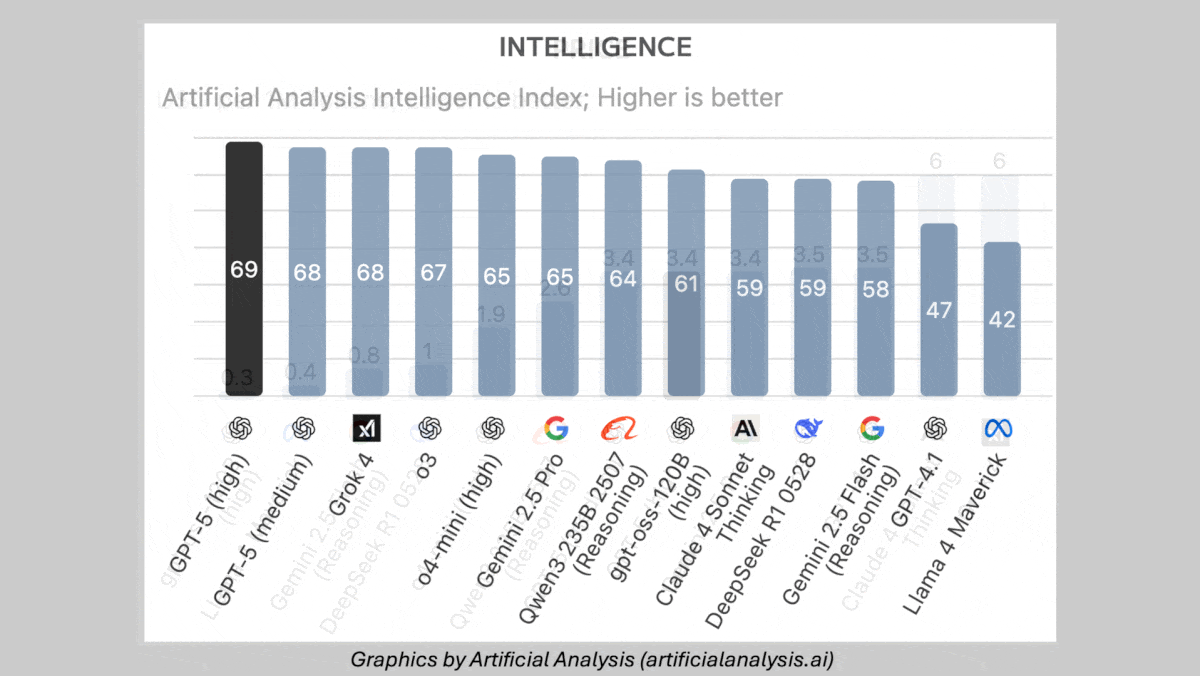
- On Artificial Analysis’s Intelligence Index, a weighted average of 10 benchmarks, GPT-5 set to either high or medium reasoning exceeded all other models tested, followed by xAI Grok 4 and OpenAI o3. However, it fared worse on benchmarks of abstract reasoning without tool use. For instance, on ARC-AGI-1 and ARC-AGI-2 (visual puzzles), GPT-5 with high reasoning (65.7 percent and 9.9 percent respectively) underperformed Grok 4 Thinking (66.7 percent and 16 percent respectively).
Behind the news: Launched in March 2023, GPT-4 raised the bar for vision-language performance, and anticipation of the next version grew steadily over the two years since. In December 2024, The Wall Street Journal reported GPT-5 was delayed as the scale of the project stretched OpenAI’s computational limits. In a mid-February 2025 post on the X social network, OpenAI CEO Sam Altman offered GPT-4.5 as a stopgap and outlined the improvements expected with GPT-5. But in April, he said GPT-5 would be delayed further and launched o3 and o4-mini, whose performance once again topped leaderboards. GPT-5’s August 7 debut brought an end to the long wait, but misleading graphs of its performance, rate limits, and the malfunctioning switcher marred the event, while the unexpected deprecation of earlier models in ChatGPT hamstrung many users.
Why it matters: OpenAI models have consistently topped language benchmarks. With GPT-5, the company has launched a system architecture that integrates its best models and takes advantage of the strengths of each: rapid output, slower output with adjustable computation devoted to reasoning, and graceful degradation to smaller versions.
We’re thinking: Novices may find that the GPT-5 router’s ability to choose a model for any given input simplifies things, but it remains to be seen whether expert users, who may be better at selecting the appropriate model for their tasks, will be happy to give up this control.

India Pushes to Build Indigenous AI
India, which has limited funding and large numbers of languages and dialects, is redoubling its efforts to build native large language models.
What’s new: India is funding startups and marshaling processing resources, MIT Technology Review reported. Companies such as CoRover, Sarvam AI, and Soket AI Labs are working on efficient models that can process many of the 22 officially recognized languages spoken in India while running on relatively small compute budgets.
Challenges: India is home to more than 120 languages and 19,500 dialects. However, training models to process them faces hurdles both cultural and technical.
- Some Indian languages don’t have much written text or consistent spelling, which makes for few large, high-quality datasets for model training.
- Languages such as Kannada and Tamil can be written without delimiters between words, such as spaces, which makes them difficult to tokenize efficiently.
- India lacks the financial muscle available in China, Europe, and the United States. Last year, the U.S. spent 3.5 percent of its gross domestic product on research and development, China spent 2.68 percent, and Europe spent 2.2 percent, while India spent 0.65 percent. The picture is more stark when it comes to funding startups. In 2024, U.S. AI startups amassed $97 billion in venture funding and Europe raised $51 billion, while Indian AI start-ups brought in $780.5 million.
- India’s technology industry has evolved to focus on services, such as those offered by giant software consultant Infosys, Tata, and HCL, rather than products.
Initiatives: To overcome the challenges, India’s government, cloud providers, and startups are attempting to kickstart indigenous model development. Several Indian AI leaders said they’re inspired by DeepSeek, the Chinese developer that built a leading large language model while spending far less than its international competitors.
- Last year, India’s government approved a $1.2 billion investment in the IndiaAI Mission, an overarching plan to develop AI technology.
- Some of that money will bankroll efforts like one by the Indian Ministry of Electronics and Information Technology (MeitY). In January, just 10 days after DeepSeek released DeepSeek-R1, MeitY called for proposals to build foundation models. It also invited cloud-computing and data‑center companies to reserve GPU compute capacity for government‑led AI research, which brought access to 19,000 GPUs including 13,000 top-of-the-line Nvidia H100s. The call netted 67 proposals.
- In April, the government announced that it would sponsor six large-scale models. It chose Sarvam AI to build a 70-billion-parameter multilingual model with reasoning and voice capabilities (the latter being crucial in a country where many people don’t read or write). The model is expected to be available later this year.
- MeitY also chose three startups to build multilingual models. Soket AI Labs is building a 120 billion-parameter model, Gan.ai is working on a 70 billion-parameter model, and Gnani.ai is focusing on 14 billion parameters and voice capabilities.
- Other government-funded efforts already are bearing fruit. CoRover.ai built the 3.2 billion-parameter BharatGPT, India’s first government-funded multimodal model, which offers voice capabilities in 12 languages. In June, CoRover.ai launched BharatGPT Mini, a compact version that comprises 534 million parameters.
Why it matters: As LLMs have become more sophisticated, it has become clear that one size doesn’t fit all. Countries (and subcultures within countries) need models that reflect their values, habits of thought, and languages. Yet resources are unequally distributed, leaving developers in some countries struggling to realize this dream. India is making a push to overcome the obstacles and develop AI that suits its own needs.
We’re thinking: Different countries deserve models that reflect their distinctive characters, but their development efforts need not remain insular. AI is an international project, and teams in different countries benefit by collaborating with one another. Let’s all help one another realize the benefits of AI worldwide.

AI Video Goes Mainstream
Generated video clips are capturing eyeballs in viral videos, ad campaigns, and a Netflix show.
What’s new: The Dor Brothers, a digital video studio based in Berlin, uses AI-generated clips to produce of social-media hits including “The Drill,” which has been viewed 16 million times. Similarly, AI-focused creative agency Genre.ai made a raucous commercial for gaming company Kalshi for less than $2,000, stirring debate about the future of advertising. Netflix generated a scene for one of its streaming productions, the sci-fi series The Eternaut.
How it works: For Genre.ai and The Dor Brothers, making stand-out videos requires entering new prompts repeatedly until they’re satisfied with the output, then assembling the best clips using traditional digital video editing tools. For the Kalshi ad, for instance, Genre.ai generated 300 to 400 clips to get 15 keepers. Netflix did not describe its video-generation process.
- The Dor Brothers begin by brainstorming concepts and feeding them to OpenAI’s ChatGPT and other chatbots to generate prompts. The studio uses Midjourney, Stable Diffusion, and DALL-E to turn prompts into images. It refines the prompts and feeds them to Runway Gen-4 or Google Veo 3, to produce clips.
- Genre.ai CEO PJ Accetturo uses Google Gemini or ChatGPT to help come up with ideas and co-write scripts. He uses Gemini or ChatGPT to convert scripts into shot-by-shot prompts — no more than 5 at a time, which keeps their quality high, he says — then pastes the prompts into Veo 3. To maintain visual consistency, he provides a detailed description of the scene in every prompt.
- Netflix is experimenting with Runway’s models for video generation, Bloomberg reported. To produce the AI-generated clip that appeared in The Eternaut, the company generated a scene in which a building collapsed. AI allowed production to move at 10 times the usual speed and a fraction of the usual cost, Netflix executive Ted Sarandos told The Guardian. Runway’s output has also appeared in scores of music videos, the 2022 movie Everything Everywhere All at Once, and TV’s “The Late Show.”
Behind the news: Top makers of video generation models have been courting commercial filmmakers to fit generative AI into their production processes.
- Runway has worked with television studio AMC to incorporate its tools into the studio’s production and marketing operations, and with Lionsgate to build a custom model trained on the Hollywood studio’s film archive.
- Meta teamed up with Blumhouse, the production company behind horror thrillers such as Get Out and Halloween, to help develop its Meta Movie Gen tools.
- Google’s DeepMind research team helped filmmaker Darren Aronofsky to build an AI-powered movie studio called Primordial Soup.
Why it matters: Video generation enables studios to produce finished work on schedules and budgets that would be unattainable any other way. Sets, lighting, cameras, talent, makeup, even scripts and scores — generative AI subsumes them all. For newcomers like The Dor Brothers or Genre.ai, this is liberating. They can focus on realizing their ideas without going to the effort and expense of working with people, video equipment, and locations. For established studios, it’s an opportunity to transform traditional methods and do more with less.
We’re thinking: AI is rapidly transforming the labor, cost, and esthetics of filmmaking. This isn’t the first time: It follows close upon streaming and social video, or before that, computer-generated effects and digital cameras. The Screen Actors Guild and Writers Guild of America negotiated agreements with film/video producers that limit some applications of AI, but creative people will find ways to use the technology to make products that audiences like. This creates opportunities for producers not only to boost their productivity but also to expand their revenue — which, we hope, will be used to make more and better productions than ever before.
Training Data for Coding Assistants
A bottleneck in fine-tuning large language models for software engineering is building a dataset that can show them how to edit code, search for subroutines, write test scripts, control a terminal, manage a file system, and so on. Researchers built a pipeline that produces such data automatically.
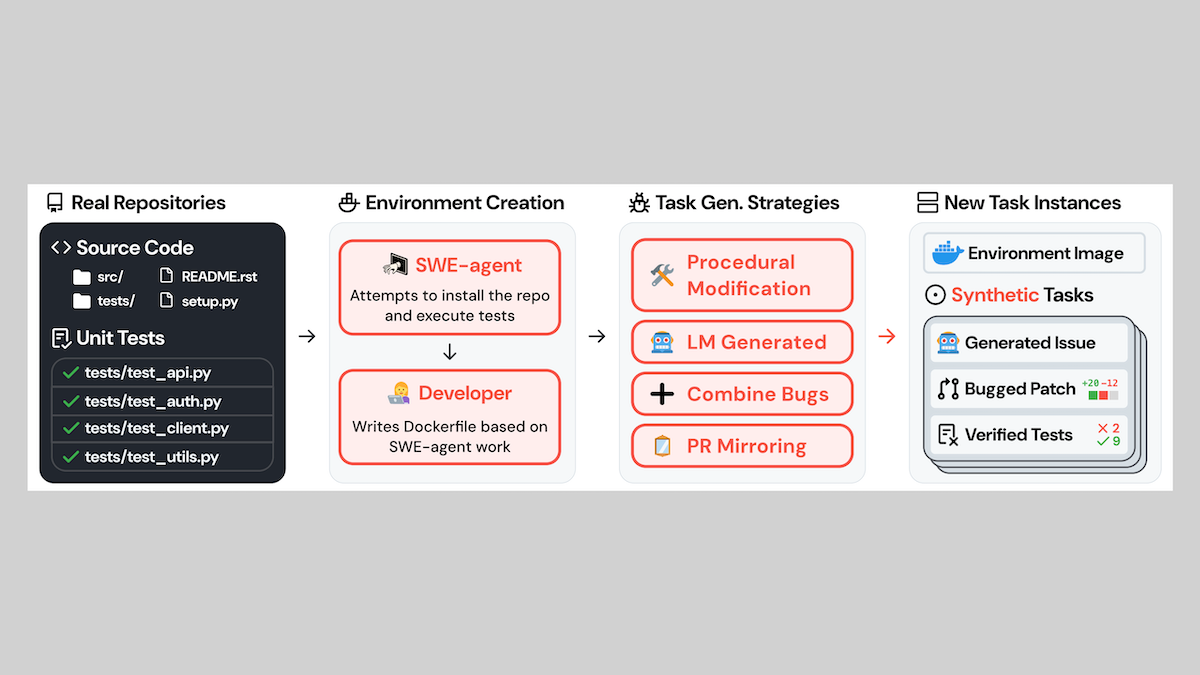
What’s new: John Yang and colleagues at Stanford, Princeton, and Alibaba introduced SWE-smith, a method that generates realistic examples of bug fixes and other code alterations. The code, dataset, and a model that was fine-tuned on the data are freely available for commercial and noncommercial uses.
Key insight: Automated unit tests determine whether code does what it’s supposed to do. Code that doesn’t pass a unit test has a bug, so one way to generate bug-fix examples is to start with code that passes a unit test and modify it until it doesn’t. Another is to start with working code and revert to previous versions that contain bugs or lack desired features. Having introduced issues, we can prompt an LLM to eliminate them, producing valid before-and-after examples that don’t require manual validation.
How it works: The authors started with 128 GitHub repositories of Python code.
- For each repository, the authors automatically built a Docker execution environment using SWE-agent, an open-source software engineering agent they built in earlier work.
- They synthesized bugs via four methods: (i) OpenAI o3-mini introduced bugs into functions or classes, (ii) a custom program altered code procedurally; for example, deleting loops or switching the order of lines, (iii) the authors combined these bugs to create more complex problems, and (iv) they reverted pull requests to re-introduce bugs and remove features from earlier versions of the code.
- They validated bugs by running unit tests and kept examples in which the buggy code failed one or more tests.
To generate examples of multi-step bug fixes, they prompted SWE-agent using Claude 3.5 Sonnet, Claude 3.7 Sonnet, or GPT-4o to fix the bugs over several steps.
Results: The authors fine-tuned Qwen 2.5 Coder-32B on 5,000 examples, focusing on the bugs produced by methods (i) and (iv) above, which they found most effective. To represent a diversity of bugs, they kept no more than 3 example fixes for any given bug. Paired with SWE-agent, their model solved software engineering problems in SWE-bench Verified in one attempt 40.2 percent of the time. Paired with the OpenHands agentic framework, the same-size R2E-Gym-32B (fine-tuned on different data) and the much bigger Qwen3-235B-A22B (not fine-tuned) solved 34.4 percent in one attempt.
Why it matters: Previous datasets for fine-tuning LLMs on coding tasks are small, often comprising thousands of training instances from less than a dozen repositories. The authors’ method can produce such data at scale, potentially enabling major developers to improve their AI-assisted coding models and everyone else to build better systems.
We’re thinking: AI-assisted coding is revolutionizing software development, and the tools are still evolving. The ability to produce effective training data at scale is likely to further accelerate the progress — already moving at breakneck speed! — in this area.