Power Moves in AI Coding, Moonshot’s Agentic LLM, How to Comply with EU AI Regs, AI Agents Evolve
The Batch AI News and Insights: We’re organizing a new event called Buildathon: The Rapid Engineering Competition, to be held in the San Francisco Bay Area on Saturday, August 16, 2025!

Dear friends,
We’re organizing a new event called Buildathon: The Rapid Engineering Competition, to be held in the San Francisco Bay Area on Saturday, August 16, 2025! You can learn more and apply to participate here.
AI-assisted coding is speeding up software engineering more than most people appreciate. We’re inviting the best builders from Silicon Valley and around the world to compete in person on rapidly engineering software.
I’ve observed a wide spectrum of AI adoption among software engineers. Some use AI only occasionally — for example, asking LLMs basic coding questions. Others have integrated AI-assisted IDEs like Cursor or Windsurf into their daily work. More advanced users are skilled at directing agentic coding assistants such as Claude Code and Gemini CLI. A small but growing group is now orchestrating multiple AI agents working in parallel across different parts of a large codebase.
In tech, the desire to chase the latest shiny technology sometimes leads individuals and even businesses to switch tooling more often than necessary. But the rapid evolution of AI coding tools means teams that are half a generation behind can be significantly less productive than those at the bleeding edge.

Code autocompletion by GitHub Copilot was cutting-edge 2 years ago, but it’s nowhere near what is possible now! For example, my team AI Fund routinely goes from a product idea to a basic working product or prototype in hours. This is why overcoming the Product Management Bottleneck — deciding what to build rather than the actual building — occupies a growing part of our effort.
DeepLearning.AI and AI Fund are organizing this Buildathon competition to see how quickly the best developers can build products. We’ll provide a loose product spec, say on a Real-Time Multiplayer Code Editor or Personal Finance Tracker (see above). Historically, these products may have taken a team of 2 or 3 engineers weeks or months to build. But we hope participants will be able to build them in closer to 60 minutes. You can read more about the competition format here.
If you use AI-assisted coding to engineer software quickly, please join our Buildathon here and show us your skills!
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
In our course Retrieval Augmented Generation, you’ll build RAG systems that connect AI models to trusted, external data sources. This hands-on course covers techniques for retrieval, prompting, and evaluation to improve the quality of your applications’ output. Get started now
News

Powers Realign in AI-Assisted Coding
A $3 billion bid by OpenAI to acquire Windsurf, maker of the AI-assisted integrated development environment of the same name, collapsed at the 11th hour, setting off a tumultuous few days of corporate maneuvering.
What’s new: Google licensed Windsurf’s technology for $2.4 billion and hired CEO Varun Mohan, co-founder Douglas Chen, and an unknown number of key engineers. Cognition AI, maker of the Devin agentic coding system, purchased what remained for an undisclosed sum. OpenAI was left empty-handed.
How it works: AI-assisted coding tools are boosting software engineering productivity, accelerating development cycles, and finding bugs and security vulnerabilities. As a leader in the field, Windsurf became a target for acquisition.
- In early May, Bloomberg reported that OpenAI had agreed to pay $3 billion for Windsurf, formerly known as Codeium. The deal would have given OpenAI talent, technology, and a user base to compete in AI-assisted coding.
- The same day, Windsurf CEO Mohan posted on the social media platform X, “Big announcement tomorrow!” But the day came and went with no further news.
- On July 11, Bloomberg reported that the deal was off. Instead, Mohan and the others had accepted positions at Google as part of a $2.4 billion non-exclusive deal to license Windsurf’s technology. OpenAI’s effort had unraveled partly because Microsoft, due to its relationship with OpenAI, would have gained access to Windsurf’s intellectual property.
- Three days later, Cognition announced that it had acquired Windsurf’s remaining assets. Windsurf promoted head of business Jeff Wang to CEO. The company awarded equity to all employees and accelerated the schedule for equity to vest.
Behind the news: Google’s hiring of Windsurf’s leadership and access to its technology in return for a large licensing fee mirrors its earlier arrangement with Character.AI. Such deals between AI leaders and startups have become increasingly common as AI companies seek quick advantages without the risk that regulators might delay or quash an outright acquisition, while AI startups seek infusions of cash to support the building of cutting-edge models. Other deals of this sort have involved Meta and Scale AI, Amazon and Adept, and Microsoft and Inflection.
Why it matters: AI-assisted coding is hot! Google recently launched Gemini Code Assist and Gemini CLI, competing with Amazon Kiro, Anthropic Claude Code, Microsoft’s GitHub Copilot, Replit Ghostwriter, and others. Expertise and technology from Windsurf may help it pull ahead. Meanwhile, Cognition’s 2024 release of Devin pioneered agentic coding, but since then competitors have taken the spotlight. Cash from Google gives the company a chance to regroup. As for OpenAI, there are other great makers of AI-assisted tools to negotiate with.
We’re thinking: Windsurf’s Anshul Ramachandran teaches a short course on agentic coding. Check it out for a peek at the technology Google deemed worth $2.4 billion.
Born to Be Agentic
An agent’s performance depends not only on an effective workflow but also on a large language model that excels at agentic activities. A new open-weights model focuses on those capabilities.
What’s new: Beijing-based Moonshot AI released the Kimi K2 family of 1 trillion-parameter large language models (LLMs). The family includes the pretrained Kimi-K2-Base and Kimi-K2-Instruct, which is fine-tuned for core agentic tasks, notably tool use. Bucking the recent trend in LLMs, Kimi K2 models are not trained for chain-of-thought reasoning.
- Input/output: Text in (up to around 128,000 tokens), text out (up to around 16,000 tokens)
- Architecture: Mixture-of-experts transformer, 1 trillion parameters total, 32 billion parameters active
- Performance: Outperforms other open-weights, non-reasoning models in tool use, coding, math, and general-knowledge benchmarks
- Availability: Web interface (free), API ($0.60/$0.15/$2.50 per million input/cached/output tokens), weights available for non-commercial and commercial uses up to 100 million monthly active users or monthly revenue of $20,000,000 under “modified MIT license”
- Features: Tool use including web search and arbitrary tools
- Undisclosed: Specific training methods, training datasets
How it works: Moonshot pretrained the models on 15.5 trillion tokens from undisclosed sources. It fine-tuned Kimi-K2-Instruct via reinforcement learning using a proprietary dataset.
- To enable Kimi-K2-Instruct to use tools, the team generated a large dataset of examples in which models used tools, both real-world and synthetic, that implement model context protocol (MCP). Unidentified models acted as users, and other unidentified models acted as agents that solved tasks assigned by the users. A further model acted as a judge to filter out unsuccessful examples.
- The team fine-tuned Kimi-K2-Instruct via reinforcement learning. The model evaluated its own performance, used its evaluation as a reward, and iteratively improved its performance.
- The team also fine-tuned Kimi-K2-Instruct to solve coding and math problems via reinforcement learning. The model did not evaluate its own performance on these problems; it determined rewards according to pre-existing solutions or unit tests.
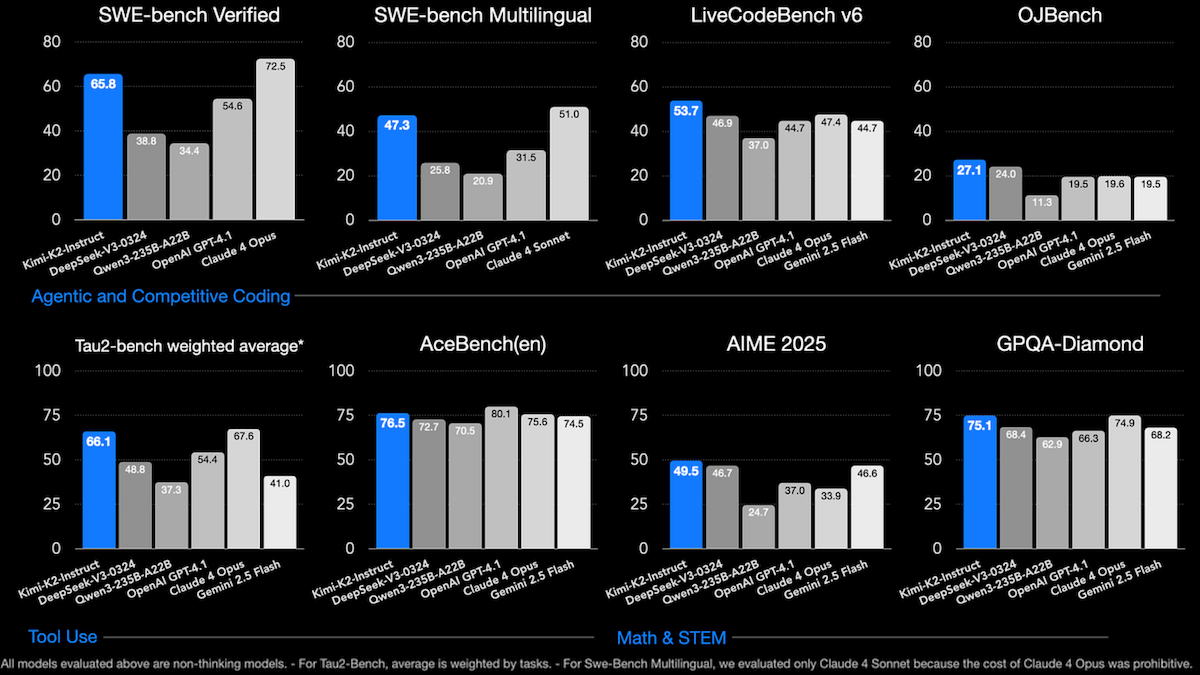
Results: Moonshot compared Kimi-K2-Instruct to two open-weights, non-reasoning models (DeepSeek-V3 and Qwen3-235B-A22B with reasoning switched off) and four closed, non-reasoning models.
- Kimi-K2-Instruct outperformed the open-weights models across a range of benchmarks for tool use, coding, math, reasoning, and general knowledge.
- It achieved middling performance relative to the closed models, though it did relatively well in math and science tasks.
- Compared to all models tested, on LiveCodeBench (coding tasks), Kimi K2 (53 percent) achieved the best performance, ahead of Claude Sonnet 4 with extended thinking mode switched off (48.5 percent).
- Among all models tested, on AceBench (tool use), Kimi K2 (76.5 percent accuracy) placed second behind GPT 4.1 (80.1 percent accuracy).
- On 8 out of 11 math and science benchmarks, Kimi K2 achieved the best performance of all models tested.
Behind the news: Third-party vendors have been quick to implement Kimi-K2-Instruct.
- The Groq platform accelerates Kimi-K2-Instruct’s output to about 200 tokens per second ($1/$3 per million input/output tokens) compared to 45 tokens per second reported by Artificial Analysis.
- The fine-tuning platform Unsloth released quantized versions that run on local devices that have 250 gigabytes of combined hard-disk capacity, RAM, and VRAM.
Why it matters: Demand is growing for LLMs that carry out agentic workflows accurately, as these workflows lead to better performance. Kimi-K2-Instruct gives developers a strong option for fine-tuning models for their own agentic tasks.
We’re thinking: Early LLMs were built to generate output for human consumption. But the rise of agentic workflows means that more and more LLM output is consumed by computers, so it makes good sense to put more research and training effort into building LLMs that generate output for computers. A leading LLM optimized for agentic workflows is a boon to developers!

How to Comply With the EU’s AI Act
The European Union published guidelines to help builders of AI models to comply with the AI Act, which was enacted last year.
What’s new: The General Purpose AI Code of Practice outlines voluntary procedures to comply with provisions of the AI Act that govern general-purpose models. Companies that follow the guidelines will benefit from simplified compliance, greater legal certainty, and potentially lower administrative costs, according to EU officials. Those that don’t must comply with the law nonetheless, which may prove more costly. While Microsoft, Mistral, and OpenAI said they would follow the guidelines, Meta declined, saying that Europe is “heading down the wrong path on AI.”
How it works: The code focuses on “general-purpose AI models” that are capable of performing a wide range of tasks.
- Stricter rules apply to models that are deemed to pose “systemic risk,” or “a risk that is specific to the high-impact capabilities” owing to a model’s reach or clear potential for producing negative effects. Managers of such models must perform continuous assessment and mitigation, including identifying and analyzing systemic risks and evaluating how acceptable they are. They must protect against unauthorized access and insider threats.
- Developers who build models that pose systemic risk must maintain a variety of documentation. They must disclose training data and sources, how they obtained rights to the data, the resulting model’s properties, their testing methods, and computational resources and energy consumed. They must file updates when they make significant changes or upon request of parties that use the model. They must report mishaps and model misbehavior. They must file a report within 2 days of becoming aware of an event that led to a serious and irreversible disruption of critical infrastructure, 5 days to report a cybersecurity breach, and 10 days a model’s responsibility for a human death.
- The code doesn’t mention penalties for noncompliance or violations. Further, the code doesn’t discuss the cost of compliance except to say that assessing and mitigating systemic risks “merits significant investment of time and resources.” In 2024, Germany’s Federal Statistical Office estimated that the cost of compliance for a high-risk system would come to roughly $600,000 to get started and another $100,000 annually.
Behind the news: The AI Act is the product of years of debate and lobbying among scores of stakeholders. EU technology official Henna Virkkunen called the AI Act “an important step” in making cutting-edge models “not only innovative but also safe and transparent.” However, companies and governments on both sides of the Atlantic have asserted that the law goes too far. In May, the EU moved to relax some provisions, including language that would allow users to sue AI companies for damages caused by their systems. Earlier this month, 44 chief executives at top European companies asked European Commission President Ursula von der Leyen to postpone the AI Act’s rules that govern general-purpose models for two years.
Why it matters: The AI Act is the most comprehensive and far-reaching set of AI regulations enacted to date, yet it remains highly contentious and in flux. The commitments by Microsoft, Mistral, and OpenAI to follow the code mark a significant step in the act’s circuitous path to implementation, but also an increase in bureaucracy and potential for regulatory capture. Their endorsement could persuade other big companies to sign on and weaken further efforts to loosen the act’s requirements.
We’re thinking: From a regulatory point of view, the notion of systemic risk is misguided. Limiting the inherent risk of AI models is as helpful as limiting the inherent risk of electric motors, which would result only in relatively useless motors. We hope for further revisions in the AI Act that relieve burdens on builders of foundation models, especially open source projects, and address practical risks of specific applications rather than theoretical risks of their underlying technology.
Agentic System for Harder Problems
LLMs can struggle with difficult algorithmic or scientific challenges when asked to solve them in a single attempt. An agentic workflow improved one-shot performance on hard problems both theoretical and practical.
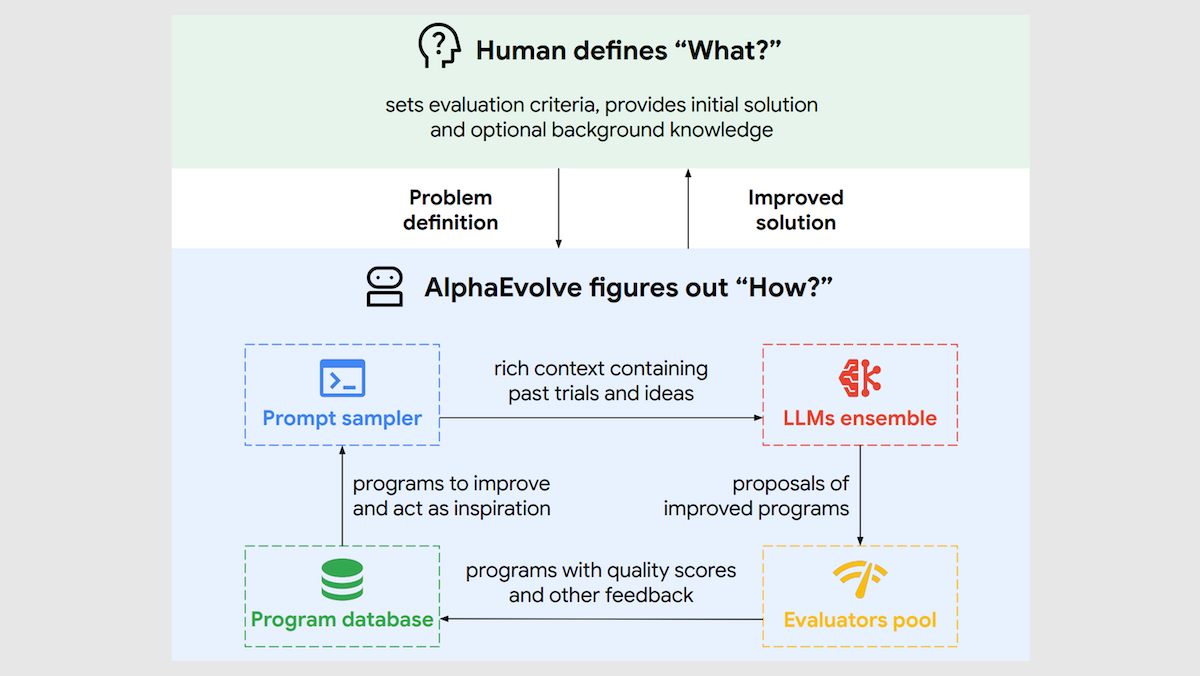
What’s new: Alexander Novikov, Ngân Vũ, Marvin Eisenberger, and colleagues at Google built AlphaEvolve, an agentic system that used LLMs to generate code in an evolutionary process. AlphaEvolve solved longstanding math problems and helped to reduce the training time for one of Google’s Gemini large language models.
Key insight: When we’re using an LLM to solve a difficult problem, it’s often more effective to start with a working version and gradually improve it than to generate a solution in one shot. By making small, targeted modifications and keeping only those that perform best under automated evaluation, this iterative process can solve problems that LLMs often can’t solve directly. Google used this idea in its earlier FunSearch, which used an LLM to evolve individual Python functions. This approach has become more powerful as LLMs have improved, and today it can benefit more difficult problems.
How it works: AlphaEvolve implemented an evolutionary loop: Given initial code and evaluation code, Gemini 2.0 Flash and Gemini 2.0 Pro suggested changes, stored the revised program in a database, evaluated it, suggested further changes, and repeated the process.
- The initial code was required to run but it could be minimal, a skeleton with placeholder logic like functions that return constants (such as “def custom_sort(list): return 2”), which primed AlphaEvolve to find a custom sorting function). Special tags indicated which parts AlphaEvolve could improve (for example, “return 2” only).
- The evaluation code could use the usual Python “sorted” function to check for correctness (for instance, “def evaluate(): return custom_sort(lst) == sorted(lst)”).
- AlphaEvolve prompted Gemini 2.0 Flash and Pro to improve the code; for example, “Act as an expert software developer. Your task is to iteratively improve the provided codebase. [USER PROVIDED CODE]”. Gemini 2.0 Flash generated ideas quickly, while Gemini 2.0 Pro provided slower but higher-quality suggestions. Each LLM proposed small alterations.
- AlphaEvolve ran and scored the altered code using the evaluation code. AlphaEvolve updated a database with the new alterations and their scores.
- The system continued in loop: It sampled high-scoring programs from its database to include in the prompts for the two LLMs, which suggested further alterations. Then it evaluated the altered programs, stored them in the database, and so on. (The authors don’t explain how the loop ends.)
Results: AlphaEvolve achieved breakthroughs in both math and software engineering.
- AlphaEvolve discovered a new algorithm for multiplying 4×4 matrices of complex values that uses 48 multiplications, fewer than [Strassen’s method], the first such progress in 56 years. (Prior work by Google improved Strassen’s method for 4×4 matrices of binary values.)
- The authors used the system to tackle over 50 other math problems. It matched the performance of the best-known algorithms in about 75 percent of cases and surpassed them in 20 percent, for instance the kissing number problem (packing spheres in 11-dimensional space so they all touch the same sphere).
- In software engineering, it optimized key components of Google's infrastructure. (i) It improved Google’s cluster scheduling algorithms, freeing up 0.7 percent of total computing resources that otherwise would be idle. (ii) It also discovered a GPU kernel configuration that accelerated attention by 32 percent. (iii) It found ways to split up the matrices that delivered an average 23 percent speedup for matrix multiplication relative to previous expert-designed heuristics. This reduced Gemini’s training time by 1 percent.
Why it matters: AlphaEvolve proposes thousands of candidate ideas — some bad, some brilliant — to evolve better programs. The authors show that this approach can improve algorithms that have stood for decades as well as computing infrastructure designed by Google engineers. Thus, AlphaEvolve adds to the growing evidence that LLMs can act as collaborators in cutting-edge research, exploring broad problem spaces and finding novel solutions. Other examples include Co-Scientist and SWE-agent.
We’re thinking: Relatively simple evaluations enabled the authors’ agentic evolutionary system to gradually improve. More broadly, evaluations are proving to be important to a wide variety of agentic workflows.