
Qwen3’s Agentic Advance: Inside Alibaba's new open-weights models, including the 480 billion parameter Qwen3-Coder
Less than two weeks after Moonshot’s Kimi K2 bested other open-weights, non-reasoning models in tests related to agentic behavior, Alibaba raised the bar yet again.
Less than two weeks after Moonshot’s Kimi K2 bested other open-weights, non-reasoning models in tests related to agentic behavior, Alibaba raised the bar yet again.
What’s new: Alibaba released the weights for three new large language models based on its earlier Qwen3-235B-A22B. It updated the earlier model (designating the update 2507), divided it into non-reasoning and reasoning variants, and added Qwen3-Coder for coding and multi-turn tool use.
- Input/output: Qwen3-235B-A22B-Instruct-2507 and Qwen3-235B-A22B-Thinking-2507: Text in (up to 262,144 tokens), text out (adjustable, up to 32,768 tokens recommended. Qwen3-Coder: Text in (up to 1 million tokens), text out (adjustable, up to 32,768 tokens recommended).
- Architecture: Mixture-of-experts transformers. Qwen3-235B-A22B-Instruct-2507 and Qwen3-235B-A22B-Thinking-2507: 235 billion parameters, 22 billion active at any given time. Qwen3-Coder: 480 billion parameters, 35 billion active at any given time.
- Performance: Qwen3-235B-A22B-Instruct-2507: best among non-reasoning models on most benchmarks reported. Qwen3-235B-A22B-Thinking-2507: middling performance compared to proprietary reasoning models. Qwen3-Coder: best among coding models on most benchmarks reported
- Availability: Free for noncommercial and commercial uses under Apache 2.0 license via HuggingFace and ModelScope, API access via Alibaba Cloud.
- API Price: Qwen3-235B-A22B-Instruct-2507: $0.70/$2.8 per million input/output tokens. Qwen3-235B-A22B-Thinking-2507: $0.70/$8.4 per 1 million input/output tokens. Qwen3-Coder: $1 to $6 per 1 million input tokens, $5 to $60 per 1 million output tokens depending on the number of input tokens.
- Undisclosed: Qwen3-235B-A22B-Instruct-2507 and Qwen3-235B-A22B-Thinking-2507: updated training data and methods. Qwen3-Coder: training data and methods.
How it works: The updated Qwen3 models underwent pretraining and reinforcement learning (RL) phases, but the company has not yet published details. During RL, the team used a modified version of Group Relative Policy Optimization (GRPO) that it calls Group Sequence Policy Optimization (GSPO).
- Qwen3-235B-A22B-Instruct-2507 and Qwen3-235B-A22B-Thinking-2507: The team removed the switch that previously enabled or disabled reasoning. Instead, users can choose whether to use the nonreasoning or reasoning model. Both models process input sizes up to double that of the previous version.
- Qwen3-Coder: The team pretrained Qwen3-Coder on 7.5 trillion tokens, 70 percent of which were code. During RL, Qwen3-Coder learned to solve tasks that required multiple turns of tool use.
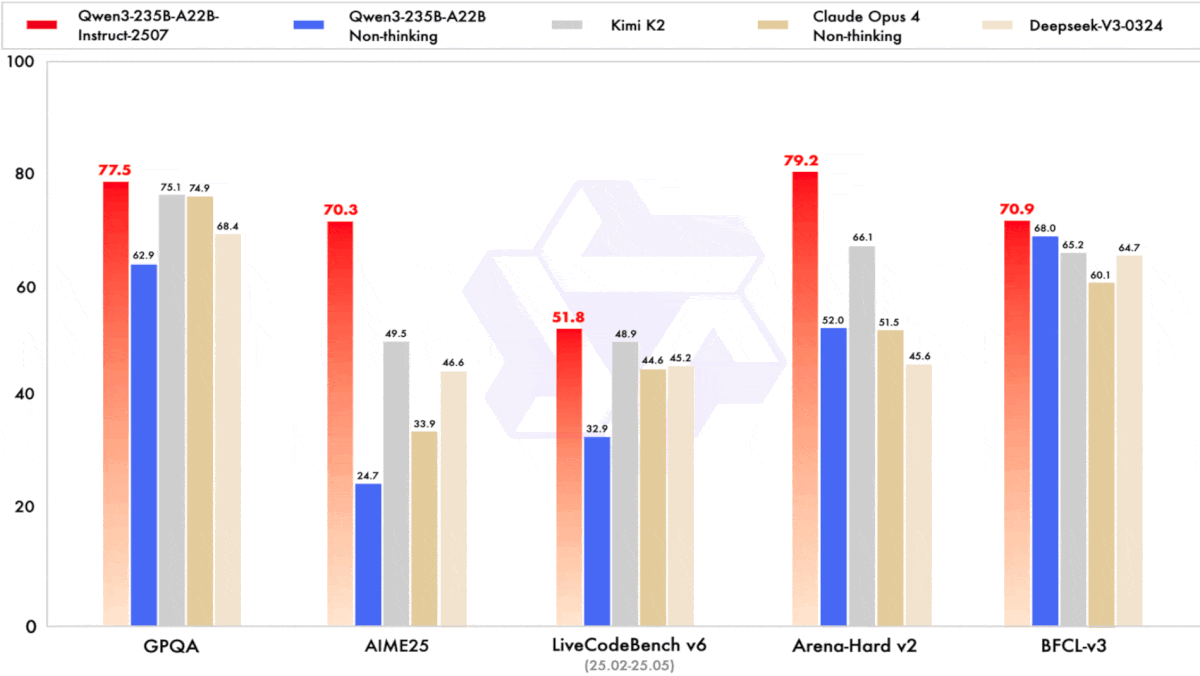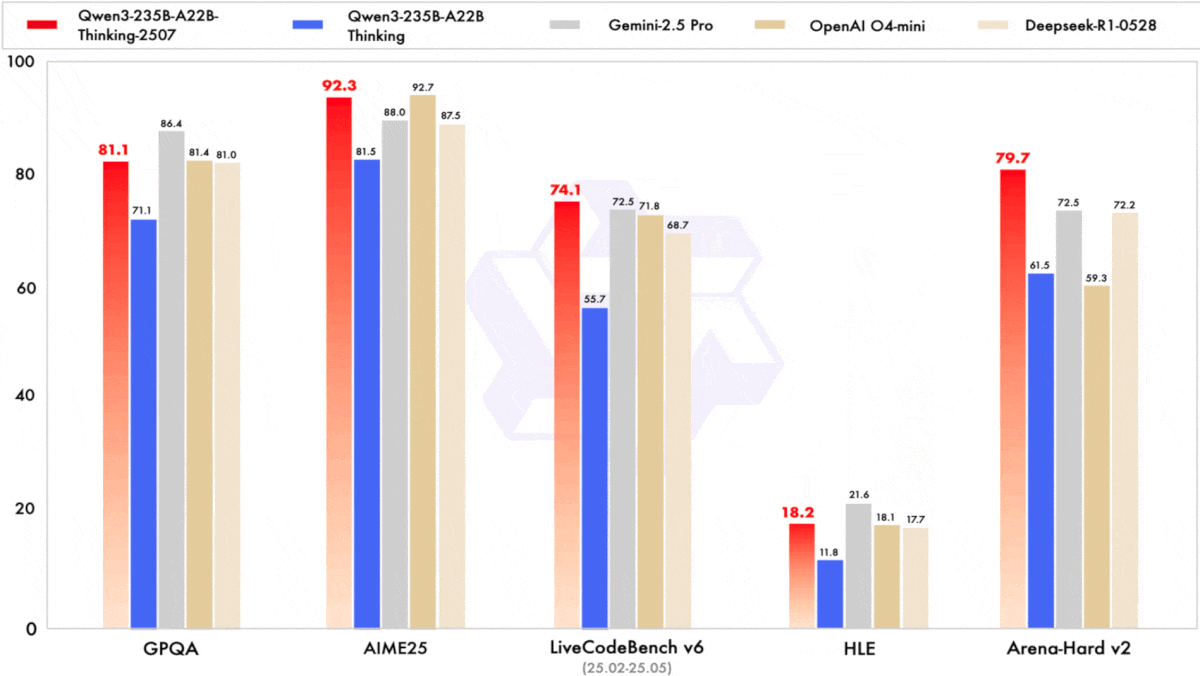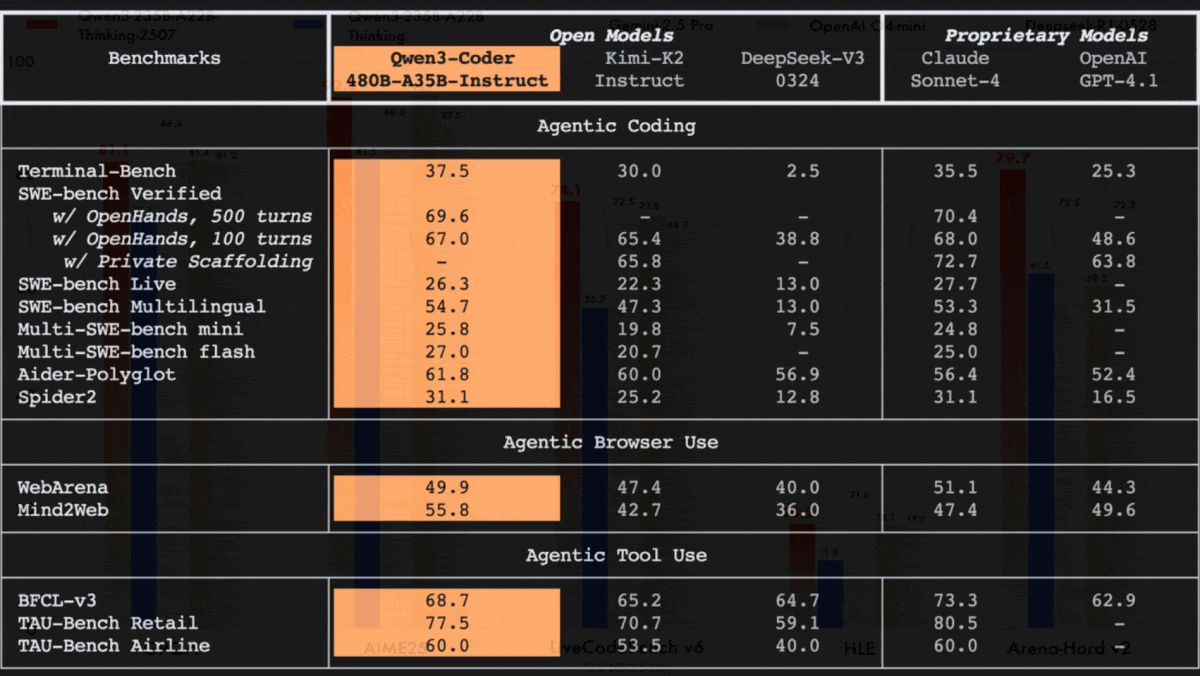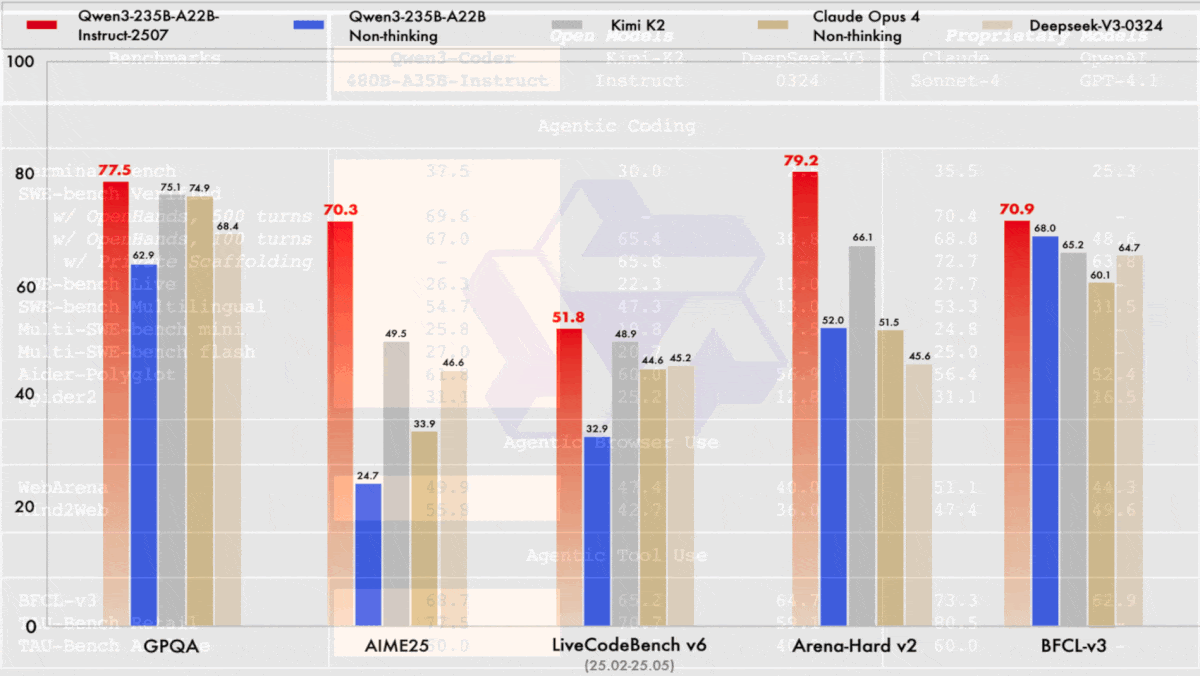
Performance: The authors compared Qwen3-235B-A22B-Instruct-2507 and Qwen3-235B-A22B-Thinking-2507 to both open and proprietary models across tasks that involved knowledge, reasoning, coding, and tool use. They compared Qwen3-Coder to open and proprietary models on agentic tasks (coding, tool use, and browser use).
- Qwen3-235B-A22B-Instruct-2507 achieved the best performance on 14 of 25 benchmarks tested compared to other non-reasoning models, including Kimi K2, Claude Opus 4 (with reasoning mode turned off), and GPT-4o. It did especially well on knowledge and reasoning tasks. For example, on GPQA (graduate-level science questions), Qwen3-235B-A22B-Instruct-2507 (77.5 percent accuracy) outperformed second-best Kimi K2 (75.1 percent accuracy).
- Qwen3-235B-A22B-Thinking-2507 achieved the best performance on 7 of 23 benchmarks compared to other reasoning models, often behind o3 and Gemini-2.5 Pro and ahead of Claud 4 Opus with thinking mode turned on. For instance, on GPQA, Qwen3-235B-A22B-Thinking-2507 (81.1 percent accuracy) fell behind Gemini 2.5 Pro (86.4 percent) and o3 (83.3 percent) but ahead of Claude 4 Opus (79.6 percent).
- Qwen3-Coder outperformed open-weights models Kimi K2 Instruct and DeepSeek-V3 on all 13 benchmarks presented that involve agentic capabilities like multi-turn coding and agentic workflows. Compared to Claude 4 Sonnet, it achieved better performance on 6 of 13. For instance, on SWE-bench Verified (software engineering tasks), the authors compared the models using the OpenHands agentic framework for 100 turns. Qwen3-Coder succeeded 67 percent of the time, while Kimi K2 Instruct succeeded 65.4 percent of the time and Claude Sonnet 4 succeeded 68 percent of the time.
Why it matters: Developers of open-weights models are adjusting their approaches to emphasize performance in agentic tasks (primarily involving coding and tool use). These models open doors to a vast range of applications that, given a task, can plan an appropriate series of actions and interact with other computer systems to execute them. That the first wave of such models were built by teams in China is significant: U.S. developers like Anthropic, Google, and OpenAI continue to lead the way with proprietary models, but China’s open-weights community is hot on their heels, while the U.S. open-weights champion, Meta, may step away from this role.
We’re thinking: Agentic performance is driving the next wave of AI progress. We hope to learn more about how the Qwen team raised the bar.



