Human-Level X-Ray Diagnosis: A research summary of CheXbert for labeling chest x-rays
Like nurses who can’t decipher a doctor’s handwriting, machine learning models can’t decipher medical scans — without labels. Conveniently, natural language models can read medical records to extract labels for X-ray images.
Like nurses who can’t decipher a doctor’s handwriting, machine learning models can’t decipher medical scans — without labels. Conveniently, natural language models can read medical records to extract labels for X-ray images.
What’s new: A Stanford team including Akshay Smit and Saahil Jain developed CheXbert, a network that labels chest X-rays nearly as accurately as human radiologists. (Disclosure: The authors include Pranav Rajpurkar, teacher of deeplearning.ai’s AI for Medicine Specialization, as well as Andrew Ng.)
Key insight: A natural language model trained on a rule-based system can generalize to situations the rule-based system doesn’t recognize. This is not a new insight, but it is novel in the authors’ application.
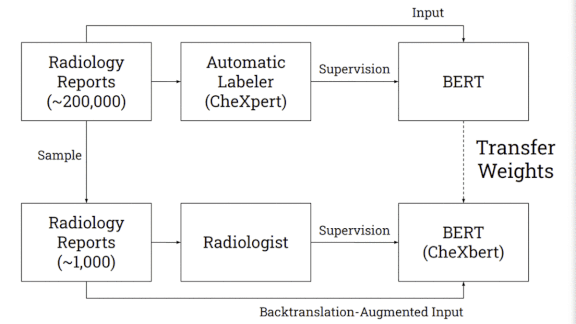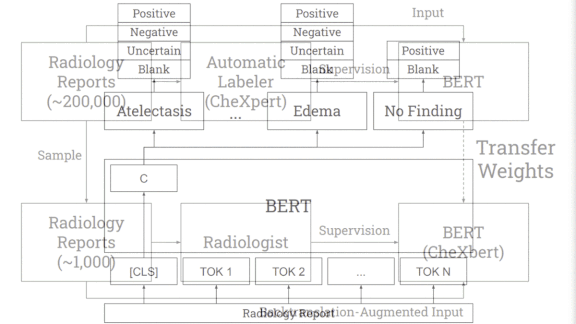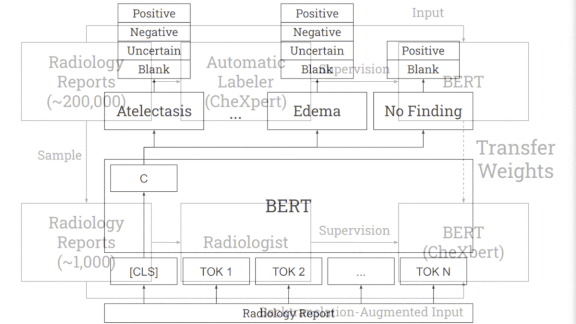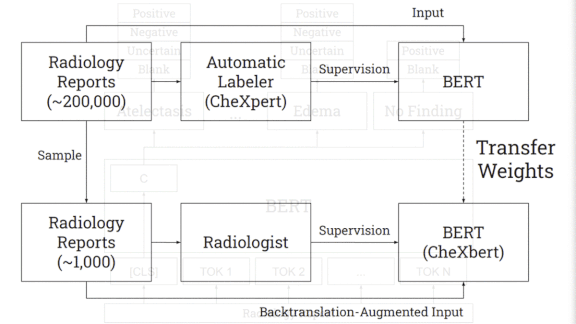
How it works: CheXbert predicts a label from 14 diagnostic classes in the similarly named CheXpert dataset: one of 12 conditions, uncertain, or blank. CheXpert comes with a rule-based labeler that searches radiological reports for mentions of the conditions and determines whether they appear in an image.
- The researchers started with BlueBERT, a language model pre-trained on medical documents.
- They further trained the model on CheXpert’s 190,000 reports to predict labels generated by CheXpert’s labeler.
Then they fine-tuned the model on 1,000 reports labeled by two board-certified radiologists. - The fine-tuning also included augmented examples of the reports produced by the technique known as back translation. The researchers used a Facebook translator to turn the reports from English into German and back, producing rephrased versions.
Results: CheXbert achieved an F1 score of 0.798 on the MIMIC-CXR dataset of chest X-rays. That’s 0.045 better than CheXpert’s labeler and 0.007 short of a board-certified radiologist’s score.
Yes, but: This approach requires a pre-existing, high-quality labeler. Moreover, the neural network’s gain over the rule-based system comes at the cost of interpretability.
Why it matters: A doctor’s attention is too valuable to spend relabeling hundreds of thousands of patient records as one-hot vectors for every possible medical condition. Rule-based labeling can automate some of the work, but language models are better at determining labels.
We’re thinking: Deep learning is poised to accomplish great things in medicine. It all starts with good labels.