How to Liberate Data From Large, Complex PDFs: LandingAI’s Agentic Document Extraction accurately extracts data from PDFs for processing by LLMs in as few as 3 lines of code.
LandingAI’s Agentic Document Extraction (ADE) turns PDF files into LLM-ready markdown text.
Dear friends,
LandingAI’s Agentic Document Extraction (ADE) turns PDF files into LLM-ready markdown text. I’m excited about this tool providing a powerful building block for developers to use in applications in financial services, healthcare, logistics, legal, insurance, and many other sectors.
Before LLMs, many documents sat on individuals’ laptops or in businesses’ cloud storage buckets unexamined, because we did not have software that could make sense of them. But now that LLMs can make sense of text, there’s significant value in getting information out of the numerous PDF documents, forms, and slide decks we’ve stored for processing — if we are able to extract the information in them accurately. For example:
- Healthcare: Streamlining patient intake by accurately extracting data from complex medical forms
- Financial services: Accurately extracting data from complex financial statements such as a company’s public filings, which might include financial tables with thousands of cells, for analysis
- Logistics: Extracting data from shipment orders and custom forms to track or expedite shipping
- Legal: Enable automated contract review by accurately extracting key clauses from complex legal documents
Accurate extraction of data is important in many valuable applications. However, achieving accuracy is not easy.
Further, even though LLMs hallucinate, our intuition is still that computers are good at math. Some of the most disconcerting mistakes I’ve seen a computer make have been when a system incorrectly extracted figures from a large table of numbers or complex form and output a confident-sounding but incorrect financial figure. Because our intuition tells us that computers are good at numbers (after all, computers are supposed to be good at computing!), I’ve seen users find silent failures in the form of incorrect numerical outputs particularly hard to catch.
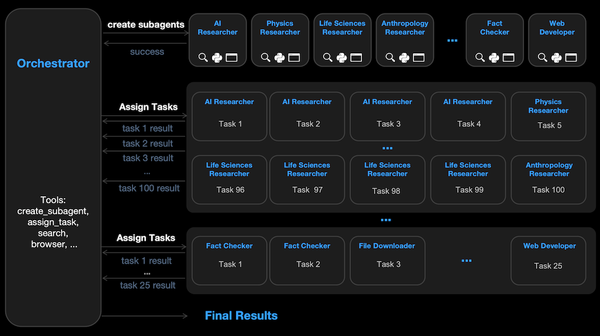
How can we accurately extract information from large PDF files? Humans don’t just glance at a document and reach a conclusion on that basis. Instead, they iteratively examine different parts of the document to pull out information piece by piece. An agentic workflow can do the same.
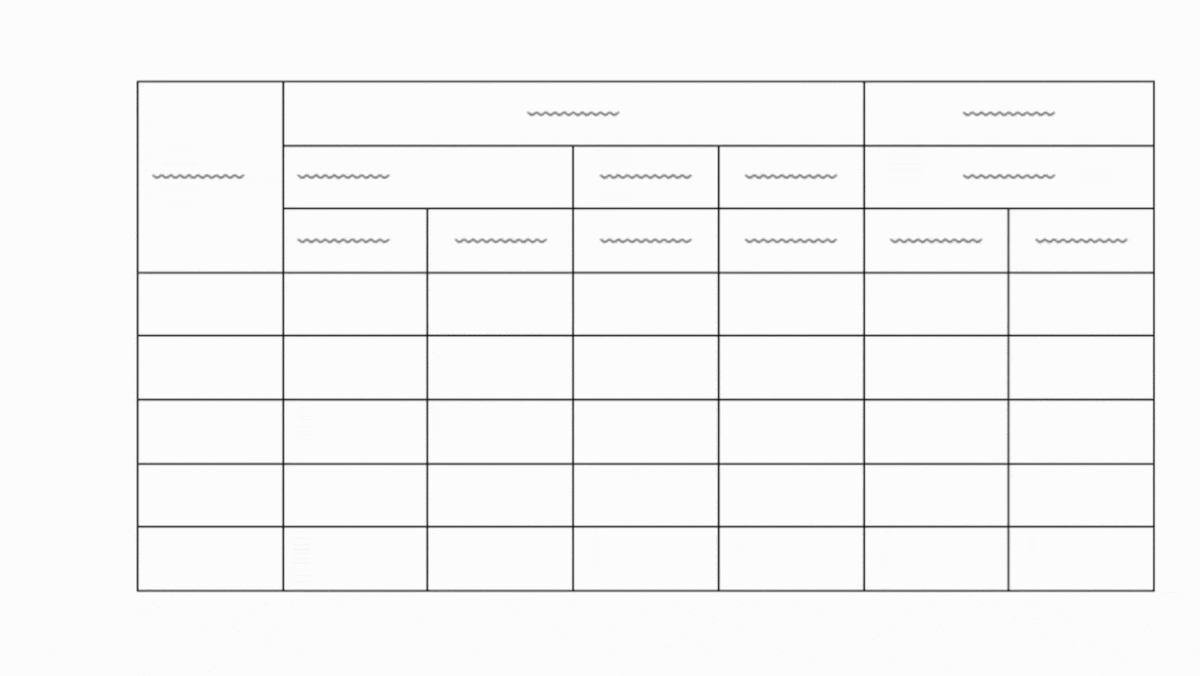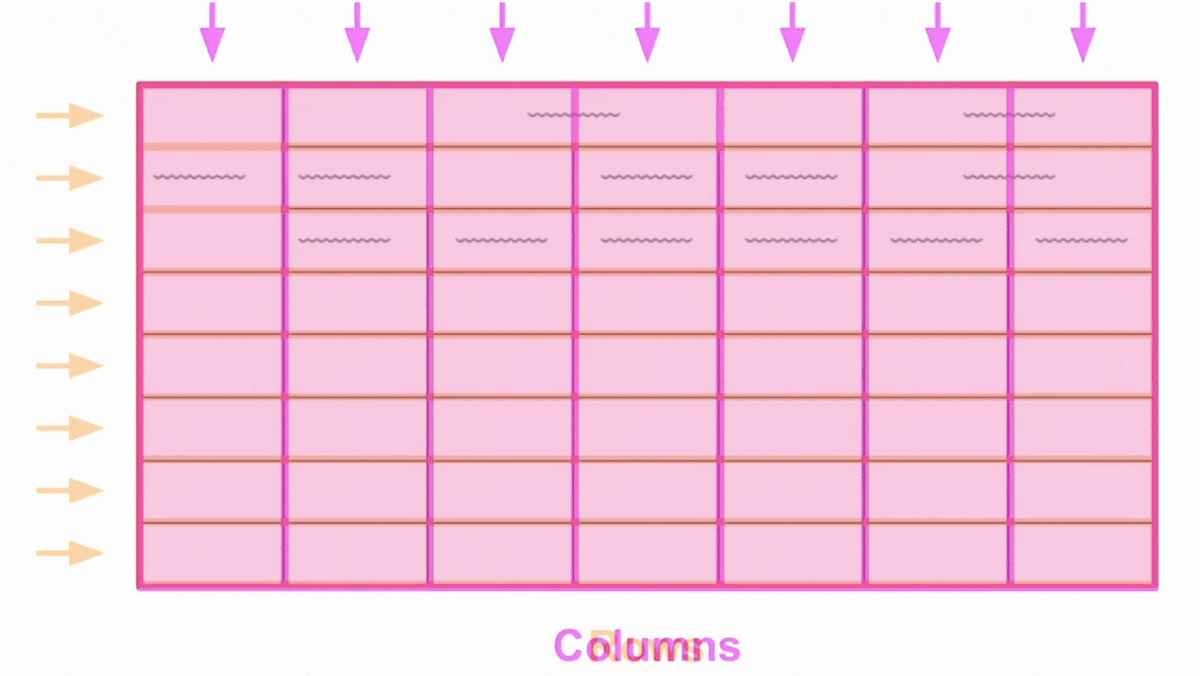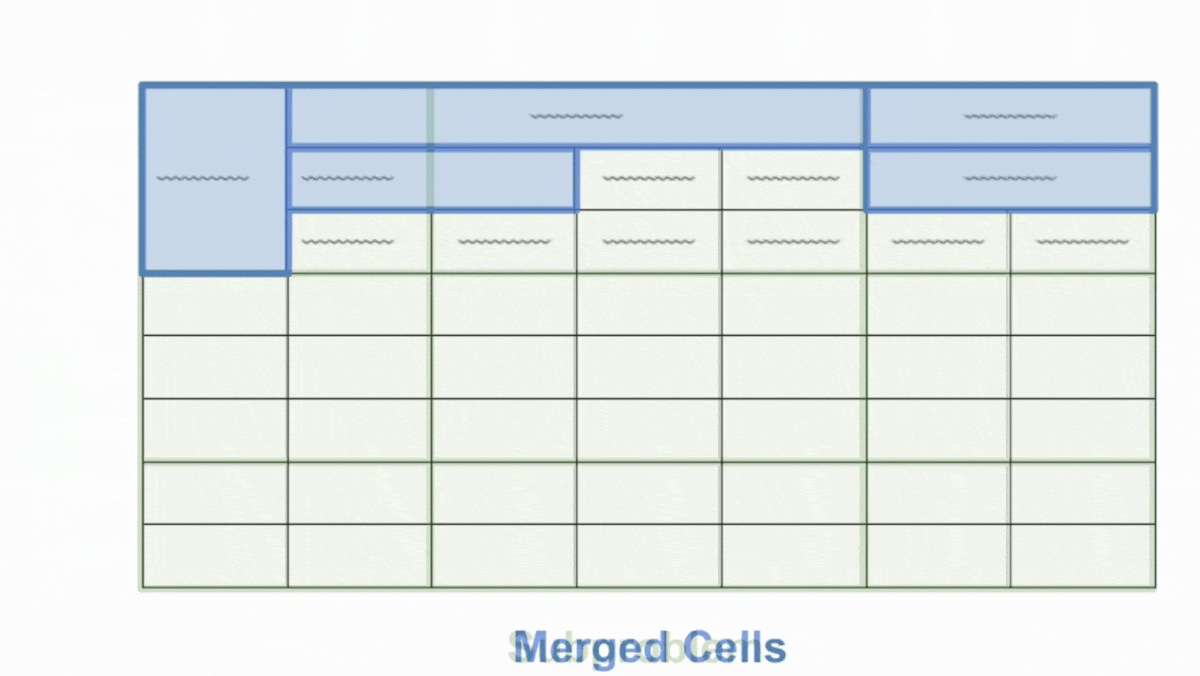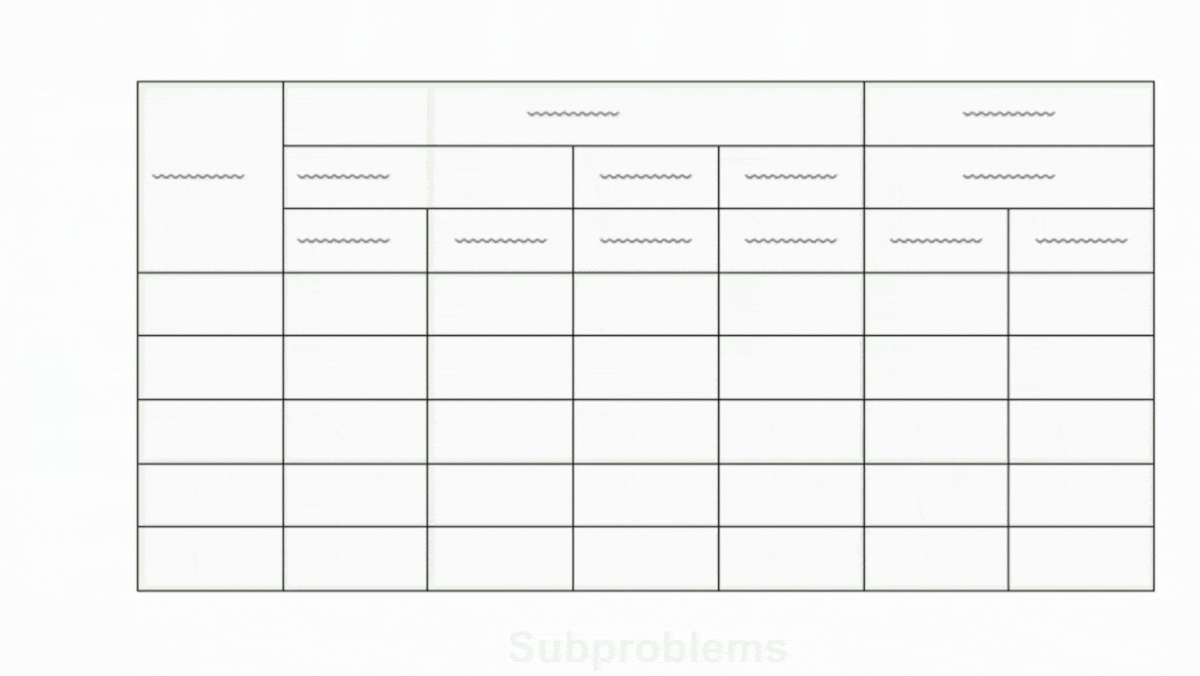
ADE iteratively decomposes complex documents into smaller sections for careful examination. It uses a new custom model we call the Document Pre-trained Transformer (DPT); more details are in this video. For example, given a complex document, it might extract a table and then further extract the table structure, identifying rows, columns, merged cells, and so on. This breaks down complex documents into smaller and easier subproblems for processing, resulting in much more accurate results.
Today, a lot of dark data — data that has been collected but is not used — is locked up in documents. ADE, which you can call using just ~3 simple lines of code, accurately extracts this information for analysis or processing by AI. You can learn more about it here. I hope many developers will think of cool applications to build with this.
Keep building!
Andrew