Earth Modeled in 10-Meter Squares: Google’s AlphaEarth Foundations tracks the whole planet’s climate, land use, potential for disasters, in detail and at scale
Researchers built a model that integrates satellite imagery and other sensor readings across the entire surface of the Earth to reveal patterns of climate, land use, and other features.
Researchers built a model that integrates satellite imagery and other sensor readings across the entire surface of the Earth to reveal patterns of climate, land use, and other features.
What’s new: Christopher F. Brown, Michal R. Kazmierski, Valerie J. Pasquarella, and colleagues at Google built AlphaEarth Foundations (AEF), a model that produces embeddings that represent every 10-meter-square spot on the globe for each year between 2017 and 2024. The embeddings can be used to track a wide variety of planetary characteristics such as humidity, precipitation, or vegetation and global challenges such as food production, wildfire risk, or reservoir levels. You can download them here for commercial and noncommercial uses under a CC BY 4.0 license. Google offers financial grants to researchers who want to use them.
Key insight: During training, feeding a model one data type limits its performance. On the other hand, feeding it too many types can cause it to learn spurious patterns. A sensible compromise is feeding it the smallest set of input data types that contain most of the relevant information.
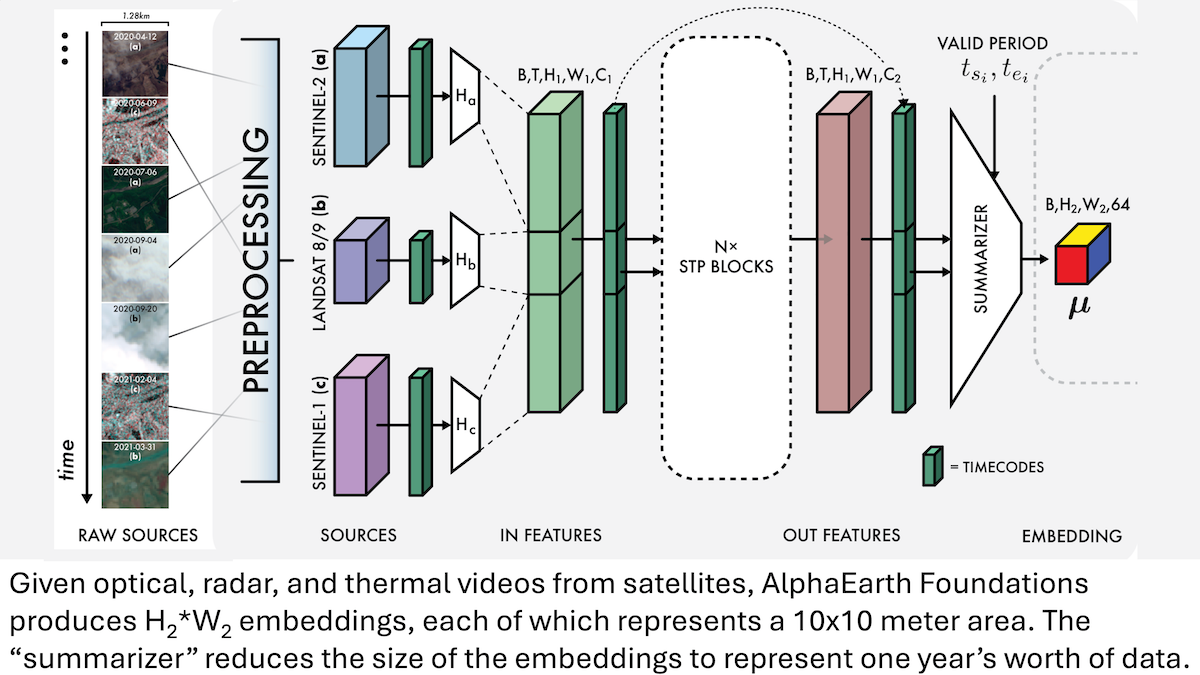
How it works: The authors used three data types — optical, radar, and thermal videos taken by satellites— as training inputs, but the loss terms referred to several others. Given the three types of satellite videos, each of which represented around 1.28 square kilometers, AEF encoded each video using unspecified encoders. It fed the encoded video to a custom module that integrated both self-attention (within and across frames) and convolutional layers. The architecture enabled the model to produce embeddings that represented each 10x10-meter area over the course of a year. To learn to produce good embeddings, the team trained the model using 4 loss terms:
- The first loss term encouraged the model to reconstruct multiple data types: the 3 inputs as well as elevation maps, climate maps, gravity maps, and images labeled with environment types like “wetland.” For each embedding produced by the model, separate vanilla neural networks reconstructed these data types. For example, for each embedding, the system produced a pixel of a thermal video.
- The second loss term encouraged the embeddings to follow the uniform distribution, ensuring that they weren’t all alike. This suited them for clustering and other common approaches.
- The third loss term encouraged the model to produce identical embeddings when given the input with a part missing as it did when given the entire input. This enabled the model to make good embeddings even if some — or all — frames were missing from an optical, radar, or thermal video.
- The fourth loss term encouraged the model to produce similar embeddings to those of text tagged with matching geographic coordinates from Wikipedia and the Global Biodiversity Information Facility , such as geotagged text about landmarks or animal populations. Conversely, it encouraged the model to produce embeddings unlike those of text corresponding to geographic coordinates that differed (following CLIP). To produce text embeddings, the authors used a frozen version of Gemini followed by a vanilla neural network that learned to help match Gemini’s embeddings and AEF’s.
- To adapt AEF for classification or regression, they trained a linear model, given an embedding from AEF, to classify or estimate the labels on a few hundred examples from the test dataset.
Results: The authors compared AEF to 9 alternatives, including manually designed approaches to embedding satellite imagery such as MOSAIKS and CCDC as well as learned models like SatCLIP. Across 11 datasets, AEF outperformed the alternatives by a significant margin.
- Classifying crops in Canada, AEF achieved around 51 percent accuracy, while the next-best approach, CCDC, achieved around 47 percent accuracy.
- Classifying changes from one type of environment to another (for example from grass to water), AEF achieved 78.4 percent accuracy, while next-best approach, MOSAIKS, achieved 72 percent accuracy.
- Estimating the amount of water per area transferred from land to atmosphere over a month, AEF achieved roughly 12 millimeters mean square error, while MOSAIKS achieved roughly 18 millimeters mean square error.
Why it matters: Satellites examine much of Earth’s surface, but their output is fragmentary (due to cloud cover and orbital coverage) and difficult to integrate. Machine learning can pack a vast range of overhead data into a comprehensive set of embeddings that can be used with Google’s own Earth Engine system and other models. By embedding pixels, AEF makes it easier to map environmental phenomena and track changes over time, and the 10x10-meter resolution offers insight into small-scale features of Earth’s surface. The team continues to collect data, revise the model, and publish updated embeddings.
We’re thinking: This project brings AI to the whole world!