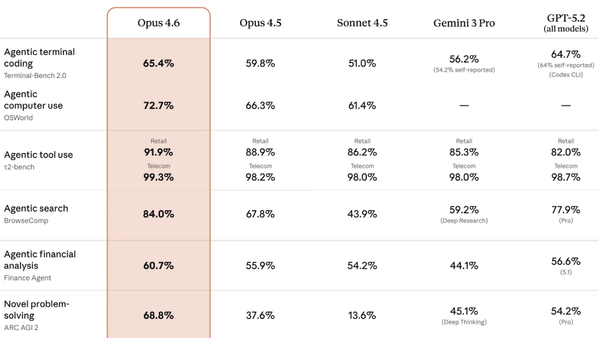
Next-Level DeepSeek-R1: DeepSeek-R1’s update leads all open models and brings it up to date with the latest from Google and OpenAI
DeepSeek updated its groundbreaking DeepSeek-R1 large language model to strike another blow for open-weights performance.
DeepSeek updated its groundbreaking DeepSeek-R1 large language model to strike another blow for open-weights performance.
What’s new: The new DeepSeek-R1-0528 surpasses its predecessor and approaches the performance of OpenAI o3 and Google Gemini-2.5 Pro. A smaller version, DeepSeek-R1-0528-Qwen3-8B, runs on a single GPU with as little as 40GB VRAM, according to TechCrunch.
- Input/output: Text in (up to 64,000 tokens), text out (up to 64,000 tokens)
- Architecture: DeepSeek-R1-0528 mixture-of-experts transformer, 685 billion parameters (upgraded from 671 billion), 37 billion active at any given time; DeepSeek-R1-0528-Qwen3-8B transformer
- Features: JSON output, tool use
- Availability/price: Both models free via Hugging Face for noncommercial and commercial uses under MIT License, DeepSeek-R1-0528 available via DeepSeek’s app by entering the conversation interface and turning on Deep Thinking, DeepSeek API $0.14/$2.19 per 1 million tokens of input/output ($0.035/$0.55 per 1 million tokens of input/output from 4:30 P.M. to 12:30 A.M. Pacific Time)
- Undisclosed: Fine-tuning data and methods
How it works: DeepSeek released little information so far about how it built the new models.
- Like the original DeepSeek-R1, DeepSeek-R1-0528 is a fine-tuned version of DeepSeek-V3 from late 2024. It was exposed to further “algorithmic optimization mechanisms during post-training” and consumes more tokens at inference.
- DeepSeek-R1-0528-Qwen3-8B is based on Qwen3-8B with reasoning knowledge distilled from DeepSeek-R1-0528.
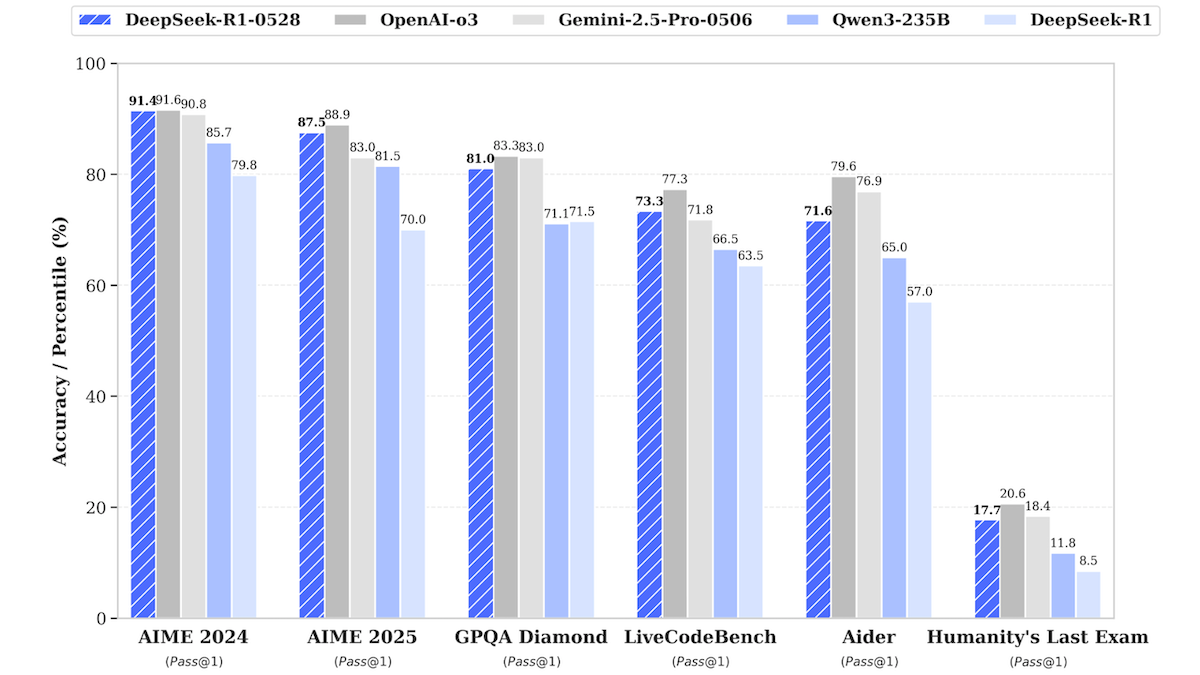
Performance: DeepSeek-R1-0528 nips at the heels of top closed LLMs on a variety of benchmarks, while DeepSeek-R1-0528-Qwen3-8B raises the bar for LLMs in its 8-billion-parameter size class. DeepSeek claims general improvements in reasoning, managing complex tasks, and writing and editing lengthy prose, along with 50 percent fewer hallucinations when rewriting and summarizing.
- DeepSeek-R1-0528 improves on the previous version dramatically in some cases. In DeepSeek’s tests, it achieved 17.7 percent of the reasoning problems in HLE compared to the previous version's 8.5 percent. On Aider, it achieved 71.6 percent accuracy compared to the previous version's 53.3 percent accuracy, and it made a similar improvement on AIME 2025 (math) — although it consumed nearly twice as many tokens.
- On AIME 2024 and AIME 2025 (high-school math competition problems) as well as LiveCodeBench (coding challenges), DeepSeek-R1-0528 performed ahead of Gemini-2.5 Pro-0506 but behind o3. On GPQA Diamond (graduate-level knowledge in a variety of domains), Aider (programming tasks), and HLE (reasoning), it fell behind both Gemini-2.5 Pro-0506 and o3.
- DeepSeek-R1-0528-Qwen3-8B excelled on AIME 2025, where it achieved 76.3 percent, ahead of the much larger Qwen3-32B (72.9 percent) and just behind o3-mini set to medium effort (76.7 percent). It did less well on GPQA, underperforming the other models reported by DeepSeek, and LiveCodeBench, where it fell behind Gemini 2.5-Flash-Thinking-0520.
Behind the news: The initial version of DeepSeek-R1 challenged the belief that building top-performing AI models requires tens to hundreds of millions of dollars, top-of-the-line GPUs, and enormous numbers of GPU hours. For the second time in less than a year, DeepSeek has built a competitive LLM with a relatively low budget.
Why it matters: DeepSeek’s models, along with Alibaba’s Qwen series, continue to narrow the gap between open-weights models and their closed peers. Its accomplishments could lead to wider adoption of less-expensive, more-efficient approaches. DeepSeek is passing along the cost savings to developers, offering high-performance inference at a fraction of the cost of closed models.
We’re thinking: DeepSeek-R1-0528-Qwen3-8B mixes contributions from open-weight models — possible only because Qwen3’s license, like DeepSeek’s is permissive. Open models enable experimentation and innovation in ways that closed models do not.