
10 Million Tokens of Input Context: ATLAS, a transformer-like architecture, can process a context window as large as ten million tokens
An alternative to attention enables large language models to track relationships among words across extraordinarily wide spans of text.
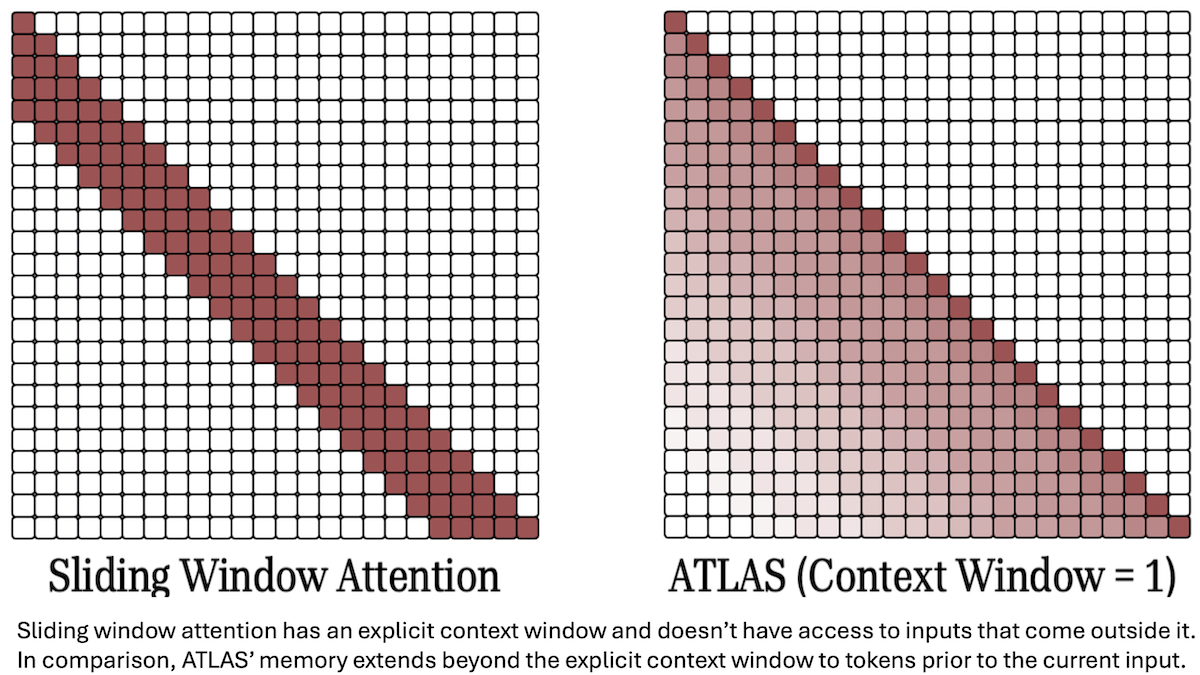
An alternative to attention enables large language models to track relationships among words across extraordinarily wide spans of text.
What’s new: Ali Behrouz and colleagues at Google devised a trainable component they call a memory module that stores and retrieves an input’s semantic content. The authors integrated this component into a transformer-like architecture, ATLAS, that can process up to 10 million tokens of input.
Key insight: Given a text token, a recurrent neural network computes a vector that represents it, which it updates when it receives the next token, and so on, so it remembers what it has processed so far. However, the vector may lose relevant information over many input tokens. An alternative is to dedicate a part of the network, or module, to generating a representation of the input and update its weights at inference. The module acts something like a retriever: When it receives sequences of tokens that are similar to those it received previously, it retrieves stored representations of the earlier sequence enriched with the latest context. In this way, it can interpret new input tokens in light of previous ones, like a typical recurrent neural network, without needing to examine all input tokens at once, like a transformer.
How it works: ATLAS replaces a transformer’s attention layers with a trainable memory module. The authors trained a 1.3 billion-parameter model to predict the next token in the FineWeb dataset of text from the web. During training, ATLAS learned good base values for the memory module’s weights, to be further modified at inference.
- Given text tokens, ATLAS used linear projections to transform them (a sliding context window of the last 2 tokens) into a key used to find related information and a value containing that information.
- The memory module, made up of fully connected layers, received the transformed key and produced a predicted value.
ATLAS compared the predicted value to the actual value and updated the memory module’s weights to minimize the difference, effectively learning which keys retrieve which values. - At inference, the model’s parameters were frozen except the memory model’s weights, which reset after each session.
Results: The authors compared ATLAS to other models of the same size that were trained on the same number of tokens. ATLAS performed best, especially in long-context tasks.
- On BABILong (answering questions about long texts), given 10 million tokens, ATLAS achieved 80 percent accuracy. Titans, a long-term memory architecture that updates its weights based on the most recently processed token, achieved approximately 70 percent accuracy. (To put these numbers in context, GPT-4’s accuracy fell from 80 percent given 1,000 tokens to below 40 percent given 100,000 tokens; its maximum input length is 128,000 tokens.
- Across 8 question-answering benchmarks, ATLAS averaged 57.62 percent accuracy, while Transformer++ averaged 52.25 percent accuracy.
Yes, but: The authors tested ATLAS at relatively small size 1.3 billion parameters. How it would perform at larger scales is unclear.
Why it matters: Keeping track of very long inputs remains a challenge for most LLMs, and processing more than 2 million tokens — the current limit of Google Gemini 2.5 Pro — is a wild frontier. ATLAS updates parameters at inference to maintain context through extraordinarily long inputs, potentially opening up applications that involve data-dense inputs such as video at full resolution and frame rate.
We’re thinking: ATLAS extends context to 10 million tokens — far greater than the vast majority of models. What will such very long context be useful for? How will we evaluate model performance over such long inputs? What tradeoffs come with using more tokens versus better context engineering? ATLAS may push such questions further into the foreground.



