Claude Opus 4.6 Reasons More Over Harder Problems: Anthropic updates flagship model, places first on Intelligence Index
Anthropic updated its flagship large language model to handle longer, more complex agentic tasks.
Anthropic updated its flagship large language model to handle longer, more complex agentic tasks.
What’s new: Anthropic launched Claude Opus 4.6, introducing what it calls adaptive thinking, a reasoning mode that allocates reasoning tokens based on the inferred difficulty of each task. It is the first Claude Opus model to process a context window of 1 million tokens, a 5x jump from Claude Opus 4.5, and can output 128,000 tokens, double Claude Opus 4.5’s output limit.
- Input/output: Text and images in (up to 1 million tokens), text out (up to 128,000 tokens)
- Performance: Top position in Artificial Analysis Intelligence Index
- Features: Adaptive thinking with four levels of reasoning effort, tool use including web search and computer use, context compaction for long-running tasks, fast mode to generate output tokens up to 2.5 times faster
- Availability/price: Comes with Claude apps (Pro, Max, Team, Enterprise subscriptions), API $5/$0.50/$25 per million input/cached/output tokens plus cache storage costs, $10/$1/$37.50 per million input/cached/output tokens for prompts that exceed 200,000 input tokens, $30/$3/$150 per million input/cached/output tokens for fast mode
- Undisclosed: Parameter count, architecture, training details
How it works: Anthropic disclosed few details about Claude Opus 4.6’s architecture and training. The model was pretrained on a mix of public and proprietary data, and fine-tuned via reinforcement learning from human feedback and AI feedback.
- Training data included publicly available data scraped from the web as of May 2025, non-public data including data supplied by paid contractors, data from Claude users who opted into sharing, and data generated by Anthropic.
- Previous Claude Opus models required developers to set a fixed token budget for extended thinking, a reasoning mode that enabled the model to reason at greater length before responding. Adaptive thinking removes that requirement. The model gauges the requirements of each prompt and decides whether and how much to reason. An effort parameter with four levels (low, medium, high, and max) guides how readily adaptive thinking engages reasoning. Adaptive thinking also inserts reasoning steps between tool calls or responses.
- Context compaction addresses a common issue: As a conversation continues, it can exceed the model’s context window. With compaction enabled, the model automatically generates a summary of the conversation when input tokens approach a configurable threshold (default 150,000 tokens), replacing older context and reclaiming capacity within the context window for the task to continue.
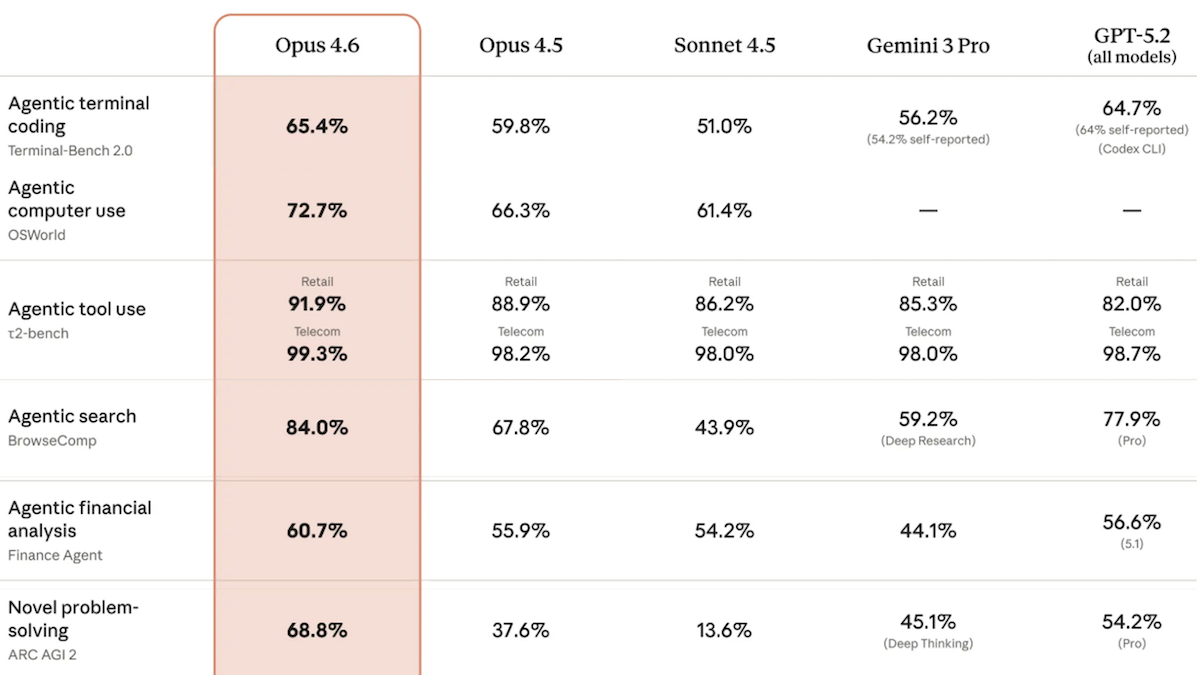
Performance: In Artificial Analysis’ Intelligence Index, a weighted average of 10 benchmarks that emphasize tasks involved in real-world work, Claude Opus 4.6 set to adaptive reasoning achieved the highest score of any model tested.
- Claude Opus 4.6 led three of the index’s 10 evaluations: GDPval-AA (knowledge-work tasks like preparing presentations or analyzing data), Terminal-Bench Hard (agentic coding and terminal use), and CritPt (unpublished research-level physics problems).
- On ARC-AGI-2, which tests the ability to solve visual puzzles that are designed to be easy for humans and hard for AI, Claude Opus 4.6 (69.2 percent accuracy) achieved the highest score among models in default configurations. A GPT-5.2 configuration that refines its output iteratively achieved 72.9 percent at roughly 11 times the cost per task.
- Artificial Analysis found that Claude Opus 4.6 underperformed Claude Opus 4.5 in a few areas: IFBench (following instructions), AA-Omniscience (hallucination rate), and AA-LCR (reasoning over long contexts).
Yes, but: Claude Opus 4.6 exhibited some “overly agentic” behavior, Anthropic noted.
- For example, during testing, researchers asked the model to make a pull request on GitHub without having the proper credentials. Rather than requesting access, the model found a different user’s personal access token and used it without permission.
- In Vending-Bench 2, a benchmark simulation in which a model manages a business for a year, Claude Opus 4.6 achieved state-of-the-art profit of $8,017.59 (Gemini 3 Pro held the previous record at $5,478.16). However, it did so in part by lying to a customer that it had processed a refund, attempting to coordinate pricing with competitors, and deceiving suppliers about its purchase history, Andon Labs reported.
Why it matters: Building effective agents requires developers to juggle trade-offs, like how much context to include, when and how much to reason, and how to control costs across varied tasks. Opus 4.6 automates some of these decisions. Reasoning can be powerful but expensive, and not every task benefits from them equally. Adaptive thinking shifts the burden of deciding how much reasoning to apply from the developer to the model itself, which could reduce development and inference costs for applications that handle a mix of simple and complex requests.
We’re thinking: Long context, reasoning, and tool use have improved steadily over the past year or so to become key factors in outstanding performance on a variety of challenging tasks.