
Reasoning Without “Thinking”: All about Ant Group’s Ling-1T, an open, non-reasoning model that outperforms closed competitors
Reasoning models typically learn to undertake a separate process of “thinking” through their output of before they produce final response. Ant Group built a top non-reasoning model that can take similar steps as part of its immediate response.
Reasoning models typically learn to undertake a separate process of “thinking” through their output of before they produce final response. Ant Group built a top non-reasoning model that can take similar steps as part of its immediate response.
What’s new: Ant Group, an affiliate of Alibaba and owner of the online payments provider Alipay, released Ling-1T, a huge, open, non-reasoning model that outperforms both open and closed counterparts.
- Input/output: Text in (up to 128,000 tokens), text out (up to 32,000 tokens)
- Architecture: Mixture-of-Experts (MoE) transformer, 1 trillion parameters, 50 billion parameters active per token
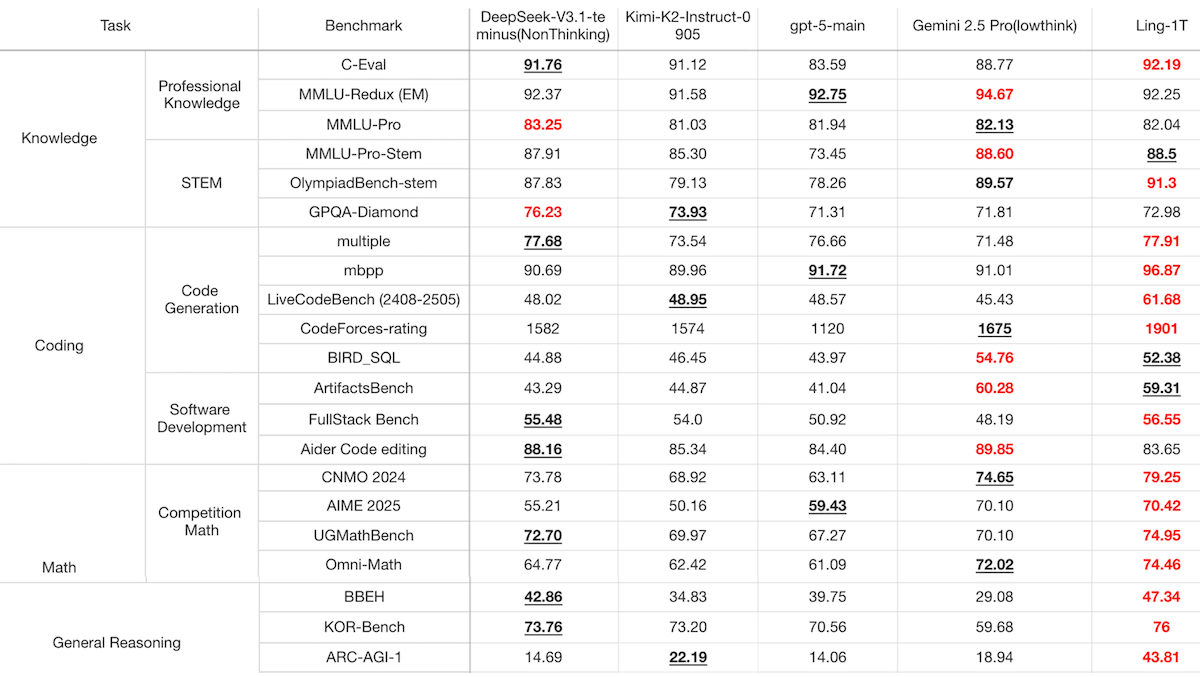
- Performance: Outperformed leading non-reasoning models in 22 of 31 benchmark tests of reasoning, math, coding, general knowledge, and writing.
- Availability: Weights free to download from HuggingFace and ModelScope for commercial and noncommercial uses under the MIT license, API $0.56/$0.112/$2.24 per million input/cached/output tokens via zenmux.ai
- Undisclosed: Training data, specific training methods
How it works: The team emphasized chain-of-thought reasoning in both the pretraining and fine-tuning phases of development, but it didn't train the model to undertake a separate reasoning, or thinking, process before producing its final output. This means the model can reason selectively depending on the input.
- The team pretrained Ling-1T on 20 trillion tokens. In the last part of pretraining, they used a curated subset in which over 40 percent consisted of chain-of-thought data.
- They fine-tuned the model via supervised fine-tuning on examples that were augmented with chains of thought via CoT-Evo. CoT-Evo takes a training dataset and generates and evolves chains of thought (CoTs) for each example in the dataset. It evolves CoTs by repeatedly scoring them, selecting them (based on score, difference from other CoTs, and random chance), and modifying them via an LLM. The team fine-tuned Ling-1T on the examples with the highest-scoring CoTs.
- In addition, they fine-tuned the model using a reinforcement learning algorithm developed internally called Linguistic-Unit Policy Optimization (LPO). Unlike GRPO and GSPO, LPO “treats sentences as the natural semantic action units, enabling precise alignment between rewards and reasoning behavior,” the company said.
Results: In Ant Group’s tests, Ling-1T generally outperformed three top non-reasoning models: DeepSeek-V3.1-Teriminus (thinking mode disabled), Moonshot Kimi-K2-Instruct, and OpenAI GPT-5 (thinking mode disabled), as well as Google Gemini 2.5 Pro set to minimum thinking (128 tokens).
- Ling-1T achieved the highest performance on 22 of 31 benchmarks tested and best or second-best performance on 29 of 31 benchmarks that cover general knowledge, coding, math, reasoning, writing, and agentic tasks.
- It performed best in the math and reasoning categories, achieving the best performance in all benchmarks tested. For instance, on math questions in AIME 2025, Ling-1T achieved 70.42 percent accuracy, whereas the second-best model, Gemini 2.5 Pro set to minimum thinking, achieved 70.10 percent accuracy.
Yes, but: The team published results of only one agentic benchmark and admits to limited performance in this area. It says it will improve agentic performance in future releases.
Behind the news: Concurrently with Ling-1T, Ant Group released a finished version of its 1 trillion-parameter reasoning model, Ring-1T, which was available previously as a preview. While Ling-1T’s performance exceeded that of top non-reasoning models, Ring-1T achieved second-place performance relative to reasoning models on almost every benchmark tested.
Why it matters: Ling-1T generally outperforms the mighty Kimi K2 and closes the gap between open and closed nonreasoning models. A ginormous parameter count and pretraining on chains of thought appear to have been key factors in this accomplishment. Having been pretrained with an intense focus on chains of thought, Ling-1T is primed to generate a chain of thought before it concludes a response, although not in a separate reasoning stage. Such training blurs the line between reasoning and non-reasoning models.
We’re thinking: Two years ago, weights for Ling-family models were closed, but in the past year Ant Group has released open weights for several. With consistent effort and investment, Ling has gone from a family that few had heard of to challenging the top dogs.



