
Qwen3 Goes Big (and Smaller): Alibaba expands Qwen3 family with a 1 trillion-parameter Max model, open-weights Qwen3-VL, and the Qwen3-Omni voice model
Alibaba rounded out the Qwen3 family with its biggest large language model to date as well as smaller models that process text, images, video, and/or audio.
Alibaba rounded out the Qwen3 family with its biggest large language model to date as well as smaller models that process text, images, video, and/or audio.
What’s new: The closed-weights Qwen3-Max gives Alibaba a foothold among the biggest large language models. Qwen3-VL-235B-A22B is an open-weights model that processes text, images, and video at the top of its size class and beyond. Qwen3-Omni, also open-weights, adds audio to the mix with outstanding results.
Qwen3-Max encompasses 1 trillion parameters trained on 36 trillion tokens. It’s available in base and instruction-tuned versions, with a reasoning version to come. Like Alibaba’s other Max models (but unlike most of the Qwen series), its weights are not available.
- Input/output: Text in (up to 262,000 tokens), text out (up to 65,536 tokens)
- Architecture and training: 1 trillion-parameter mixture-of-experts decoder, specific training data and methods undisclosed
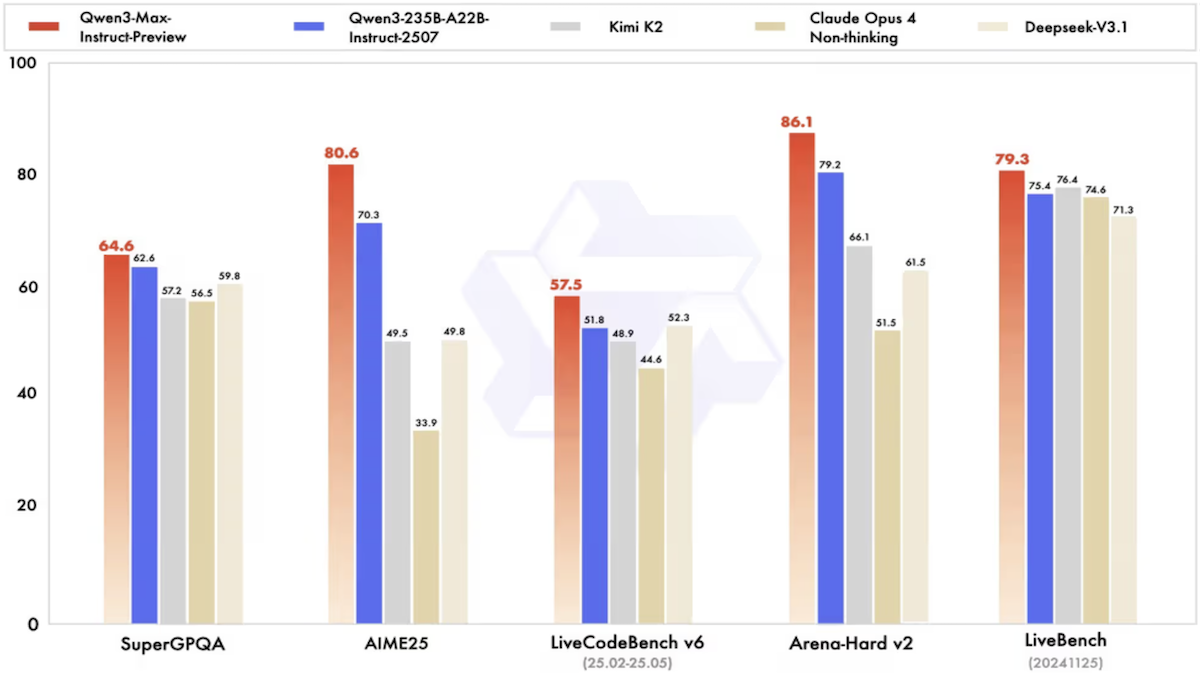
- Performance: In Alibaba’s tests, Qwen3-Max generally fell short of Google Gemini 2.5 Pro and OpenAI GPT-5 but outperformed large models from Anthropic, DeepSeek, and xAI. On Artificial Analysis’ Intelligence Index, it scored just behind the smaller Qwen3-235B-A22B.
- Availability: API access $1.20/$6.00 per 1 million input/output tokens via Alibaba Cloud in Singapore, $0.861/$3.441 per 1 million input/output tokens via Alibaba Cloud in Beijing
Qwen3-VL-235B-A22B, a vision-language variant of Qwen3-235B-A22B, is designed to drive agentic interactions that require understanding of images and videos. It comes in base, instruction-tuned, and reasoning versions.
- Input/output: Text, images, video in (up to 262,000 tokens, expandable to 1 million tokens), text out (up to 81,920 tokens)
- Architecture and training: Mixture-of-experts decoder (235 billion parameters total, 22 billion active per token), vision encoder, specific training data and methods undisclosed
- Performance: In Alibaba’s tests, Qwen3-VL-235B-A22B outperformed other open-weights models and generally matched the best available models on many image and video benchmarks, with or without reasoning capability. It established new states of the art among both open and closed models for MathVision (math problems), Design2Code (visual coding tests), and several tests of text recognition. It outperformed Gemini 2.5 Pro and OpenAI GPT-5 on tests of agentic capabilities (ScreenSpot Pro, OSWorldG, Android World), document understanding (MMLongBench-Doc, DocVQATest), and 2D/3D spatial awareness (CountBench). It performed second-best only to Gemini Pro 2.5 on the science, technology, and math portions of MMMU-Pro, visual reasoning puzzles in SimpleVQA, and video understanding challenges in VideoMMMU.
- Availability: Free for commercial and noncommercial uses under Apache 2.0 license, $0.70/$2.80 per 1 million tokens input/output via Alibaba Cloud
Qwen3-Omni-30B-A3B was pretrained on text, images, video, and audio, so it translates between them directly. It comes in instruction-tuned and reasoning versions as well as a specialized audio/video captioner model.
- Input/output: Text, images, video, or audio in (up to 65,536 tokens), text or spoken-word audio out (up to 16,384 tokens)
- Architecture and training: Mixture-of-experts transformer (30 billion parameters total, 3 billion active per token), specialized experts for multimodal and speech processing, specific training data and methods undisclosed
- Performance: Qwen3-Omni is the best-performing open-weights voice model, outperforming GPT-4o on many tests. Among 36 audio and audio-visual benchmarks, Qwen3-Omni-30B-A3B achieved state-of-the-art results on 22. In tests of mixed media understanding and voice output, its results were competitive with those of Gemini 2.5 Pro, ByteDance Seed-ASR, and OpenAI GPT-4o Transcribe.
- Availability: Free for commercial and noncommercial uses under Apache 2.0 license, $0.52/$1.99 per 1 million tokens of text input/output, $0.94/$3.67 per 1 million tokens of image-video input/text output, $4.57/$18.13 per 1 million tokens of audio input/output via Alibaba Cloud
Behind the news: Alibaba recently released Qwen3-Next, which accelerates performance by alternating attention and Gated DeltaNet layers. The new models don’t use this architecture, but it remains a potential path for future models in the Qwen family.
Why it matters: While Qwen3-Max falls short of competitors, the new open-weights multimodal models offer opportunities for developers. Qwen3-VL-235B-A22B offers low cost, versatility, and customizability, and Qwen3-Omni-30B-A3B provides a welcome option for voice applications. Alibaba has been a consistent, versatile experimenter that has put open releases first, and its new releases cover a wide range of needs.
We’re thinking: We love to see open-weights models turning in world-beating results! With their prowess in multimedia understanding, reasoning, and tool use, Qwen3-VL and Qwen3-Omni put a wide range of agentic applications within reach of all developers.



